
Qwen2.5-Omni is a cutting-edge open-source multimodal AI model released by Alibaba Cloud in 2025. It belongs to the Qwen AI family of large language models and is distinguished by its ability to handle diverse input modalities – including text, images, audio, and even video – within a single unified model.
Despite a relatively compact 7-billion parameter size, Qwen2.5-Omni achieves high performance across modalities and can generate outputs in both text and spoken audio (speech) in real-time. This makes it one of the first end-to-end multimodal models that “see, hear, talk, and understand” seamlessly in a single system.
Designed for developers, AI engineers, and researchers, Qwen2.5-Omni is geared towards advanced applications such as AI assistants, enterprise automation, and agent systems that require processing multiple types of data. It is openly available under an Apache-2.0 license, allowing integration into custom solutions without restrictive licensing. In summary, Qwen2.5-Omni can perceive a wide range of inputs and produce rich, multimodal responses, offering a powerful foundation for building the next generation of intelligent applications.
Architecture Overview (High-Level Multimodal Pipeline)
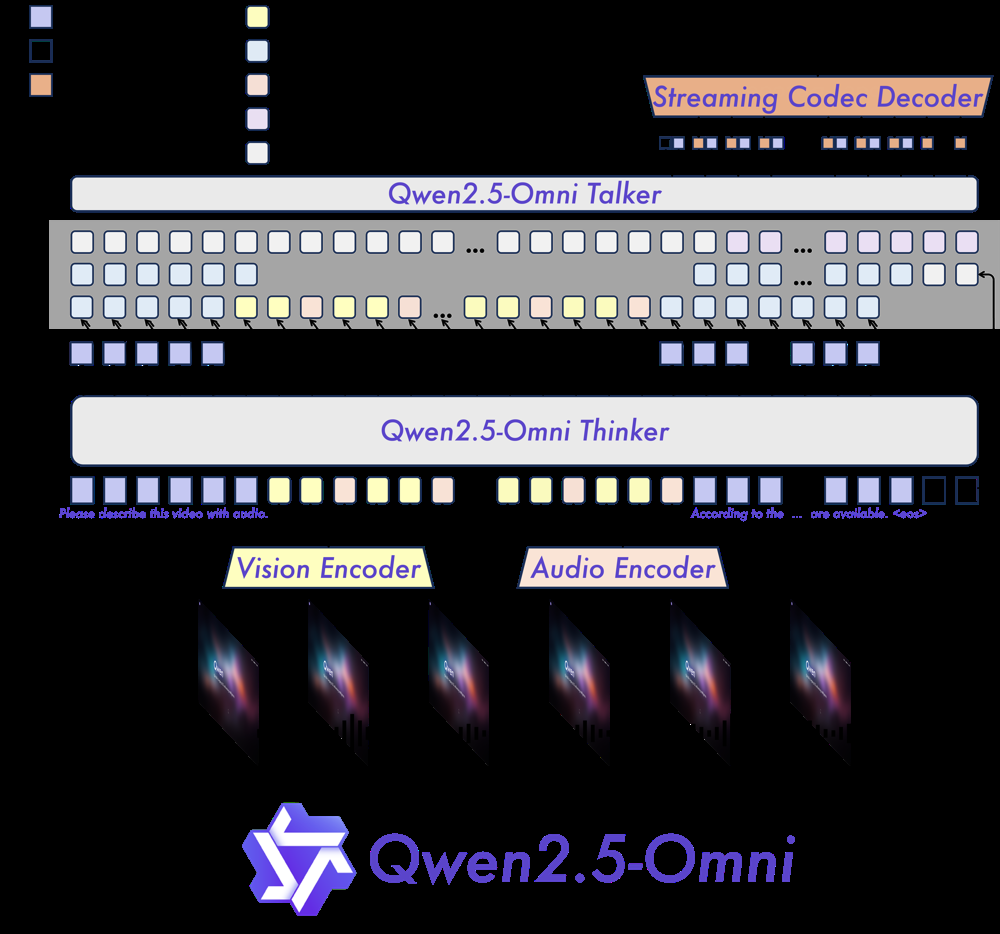

At the heart of Qwen2.5-Omni is a novel two-part architecture called Thinker–Talker. This design cleanly separates the model’s reasoning and language understanding (the Thinker) from its speech synthesis capabilities (the Talker). Here’s how the pipeline is organized at a high level:
- Thinker (Brain): The Thinker is essentially a Transformer-based large language model (decoder) that handles text generation and high-level reasoning. It accepts inputs from multiple encoders: a Vision Encoder processes image or video frames, and an Audio Encoder processes input audio signals (such as spoken queries or sounds). These encoders convert visual and audio data into token embeddings that the Thinker can attend to alongside textual inputs. The Thinker integrates all these modality inputs and produces intermediate representations and text outputs (just like a standard LLM producing a textual answer). Importantly, the Thinker maintains the full conversational or contextual history across modalities, enabling it to perform reasoning over long, multimodal contexts.
- Talker (Mouth): The Talker is a specialized autoregressive decoder that takes the Thinker’s internal representations and text outputs and converts them into audio (speech) tokens in a streaming fashion. In other words, as the Thinker formulates a response, the Talker simultaneously generates a corresponding natural speech waveform. The Talker has a dual-track Transformer decoder architecture: it directly receives the high-dimensional hidden states from the Thinker and shares the Thinker’s context (so it knows what has been said in text). This design ensures that the speech output is tightly aligned with the textual content. The Talker outputs discrete audio codec tokens which are then passed to a streaming codec decoder (a neural vocoder) that produces the final audible waveform (speech). Thanks to this design, Qwen2.5-Omni can generate text and speech concurrently in real-time, without one interfering with the other.
- Position Encoding for Multimodal Synchronization: A challenge with video+audio inputs is aligning visual frames with audio timeline. Qwen2.5-Omni introduces TMRoPE (Time-aligned Multimodal RoPE) – a novel rotary position embedding that interleaves video frame tokens and audio tokens on a shared timeline axis. This ensures that, for example, the model knows which segment of audio corresponds to which video frame in time, leading to coherent understanding of videos with sound. The Thinker can thus process video+audio input in sync, improving tasks like describing a video’s audio-visual content.
- Streaming & Block-wise Processing: Both the audio and visual encoders use a block-wise streaming approach. Rather than waiting for an entire audio clip or video to be encoded, they can encode and feed chunks of the media sequentially. This enables low-latency processing, as Qwen2.5-Omni can start generating responses while still receiving later parts of a long audio/video input. In practice, this means the model is suited for real-time conversations (it can begin answering a user’s spoken question before the user has completely finished speaking). Alibaba reports that this block-wise streaming design enables fully real-time interactions with immediate outputs during voice/video chats.
Overall, the architecture is an end-to-end trainable pipeline – the encoders, Thinker, and Talker are trained jointly so that they work in concert. This innovative design minimizes interference between modalities (text generation vs. speech synthesis) and leads to high-quality outputs in both text and speech modes. By splitting responsibilities, Qwen2.5-Omni’s Thinker–Talker architecture ensures that adding speech capability does not degrade the language understanding quality, and vice versa.
Supported Input Types (Vision, Audio, Text, Video, Mixed Prompts)
One of Qwen2.5-Omni’s core strengths is its ability to natively handle multiple types of inputs, either individually or in combination. Supported modalities include:
- Text: Standard natural language input is supported, as with any language model. You can prompt Qwen2.5-Omni with questions, instructions, or conversation in text form. It excels at long-form text understanding and generation just like a text-only LLM.
- Images: The model can analyze images to perform tasks like description, captioning, or visual question answering. When given an image, Qwen2.5-Omni’s vision encoder will process it, allowing the Thinker to reason about visual content. For example, you could show it a diagram and ask questions, or an image and ask for a summary of what’s happening in it.
- Audio: Qwen2.5-Omni can take audio waveforms as input. This means it can do speech recognition (transcribing spoken language), interpret non-speech sounds, or follow spoken instructions. The audio encoder converts raw audio (like a WAV file) into embeddings for the Thinker. This allows the model to handle user queries delivered via voice, or to understand audio context (e.g. identifying a cough sound or background music in an audio clip).
- Video: Impressively, the model accepts video input – essentially a combination of visual frames and (optional) audio track. It treats video as a sequence of images plus sound. Using TMRoPE, it aligns frames with the audio timeline so that it can answer questions about a video or narrate it. For instance, you could feed a short video clip and ask Qwen2.5-Omni to “describe what’s happening in this video with audio.” The model will parse both the visuals and sounds in tandem to produce a coherent answer.
- Mixed Modal Prompts: You are not limited to one modality at a time – Qwen2.5-Omni can take mixed prompts combining text, images, audio, and video. This is useful in complex scenarios. For example, a single user query could include an image and an audio clip along with text asking a question about both. The model will integrate all pieces. An illustration of a mixed prompt (as JSON for the API) is shown below, where the user provides an image and an audio file together with a textual question:
"messages": [
{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": "https://.../qwen.png"}},
{"type": "audio_url", "audio_url": {"url": "https://.../cough.wav"}},
{"type": "text", "text": "What is written in the image, and what sound is in the audio?"}
]}
]
In this example, Qwen2.5-Omni would concurrently analyze the image (qwen.png) to read any text or details in it, analyze the audio (cough.wav) to recognize the sound, and then answer accordingly (e.g. reading out the text in the image and identifying the cough sound). This multi-input capability demonstrates the model’s “omniperception” – the ability to perceive and reason across modalities in one go.
How are these inputs provided? When using Qwen2.5-Omni via the Hugging Face Transformers interface or via its API, you supply each modality in a structured format. For instance, the Hugging Face Qwen2_5OmniProcessor allows you to pass text, image files, audio waveforms, and video files as different arguments, and it packages them for the model. In JSON API calls, each piece of content is tagged with a "type" (text, image, audio, video) and either the raw data or a URL/path to the data. The model then processes all modalities jointly.
Notably, Qwen2.5-Omni’s design supports streaming inputs for longer media. For very long audio streams or videos, the model can ingest them chunk-by-chunk (block-wise) rather than requiring the entire file up front. This means it could handle, say, a live audio stream or a video call feed, responding in near real-time. However, longer inputs naturally demand more computational resources – e.g. processing a 60-second video with audio can use tens of gigabytes of memory in the current implementation. The developers are exploring more optimized versions to handle long-duration media efficiently.
In summary, Qwen2.5-Omni supports text, vision, audio, and video inputs, in any combination. This flexibility makes it applicable to a wide range of tasks: from answering questions about images, transcribing and summarizing audio, to describing videos or taking multimodal instructions.
Core Capabilities & Reasoning Strengths
Given its multimodal nature, Qwen2.5-Omni exhibits several key capabilities and strengths that developers can leverage:
Integrated Multimodal Reasoning: Qwen2.5-Omni can interpret and reason across different modalities simultaneously. It doesn’t treat vision or audio as separate “addons” but rather weaves them into its single Transformer context. This leads to highly coherent multimodal understanding. For example, if asked to “watch this video and summarize what happened,” the model will correlate the visual events and the sounds over time to produce a unified summary. It has demonstrated state-of-the-art performance on OmniBench, a benchmark that tests reasoning across visual, acoustic, and textual inputs. In tasks requiring integration of modalities (like a question referencing both an image and a spoken hint), Qwen2.5-Omni’s joint reasoning often outperforms handling each modality with separate specialized models.
Long-Context Understanding: The Qwen series is known for handling long inputs, and Qwen2.5-Omni continues that trend. It inherits techniques from prior Qwen models (such as Qwen2.5-1M for long context handling) that allow it to manage extended sequences. This means it can maintain context over lengthy conversations or large documents. Practically, developers can feed it longer transcripts or multiple images in sequence and expect it to remember and refer back to earlier parts. The model uses position embeddings (RoPE) effectively to scale to long sequences. For text inputs, the context window is significantly larger than the traditional 2048 tokens (Qwen’s previous variants support up to 8K or more tokens context). For audio/video, as noted, it can stream in chunks, meaning it isn’t strictly limited by a fixed context length – though memory and latency will be considerations. The ability to reason over long contexts makes Qwen2.5-Omni suitable for tasks like analyzing a long recording (e.g. an hour-long meeting audio) or a multi-page document with images, all within one session.
Multilingual Competence: Qwen2.5-Omni was trained on a diverse multilingual dataset (text and audio), giving it strong abilities in multiple languages. It can understand and generate content in English and Chinese fluently, and has competency in other languages present in its training data. In evaluations, it showed competitive speech recognition accuracy on English, Mandarin Chinese (zh), Cantonese (yue), and French, among others. For example, on the Common Voice corpus (multilingual speech), Qwen2.5-Omni’s word error rates were low and on par with specialized speech models for those languages. This multilingual understanding extends to text input/output as well – you can prompt the model in Chinese and get answers in Chinese, or ask it to translate between languages. The ability to operate in multilingual environments is critical for enterprise use (global userbases) and makes Qwen2.5-Omni an attractive option outside strictly English-centric applications.
Tool-Use and Function Calling: Although Qwen2.5-Omni is a self-contained model, it can be integrated into tool-using agent systems. The model has been designed to follow instructions carefully, which means developers can prompt it to output information in structured formats (like JSON or XML) or to follow a format that triggers external tools. For instance, you could ask Qwen2.5-Omni “Search the web for X and then summarize” – while the model itself cannot browse, it can be paired with an external tool (via an agent framework) that intercepts a special token or formatted output from Qwen indicating a search action. Qwen’s strong instruction-following suggests it can be guided to produce function call-like outputs. In fact, Alibaba provides an OpenAI-compatible API for Qwen2.5-Omni, which means it’s theoretically possible to use OpenAI function calling conventions with Qwen as well. In practice, developers can use libraries like LangChain or their own code to monitor Qwen’s outputs for a predefined syntax (e.g. a JSON with a field “action”) and then have the system execute that action. This way, Qwen2.5-Omni can act as the “brain” of an agent that uses tools like web search, databases, or calculators. While not explicitly fine-tuned on tool use, its general reasoning ability is strong enough to be adapted for these scenarios with proper prompt engineering.
Efficiency and Deployment Viability: A standout aspect of Qwen2.5-Omni is the balance it strikes between capability and size. At 7B parameters (with a smaller 3B variant also available), it is far more lightweight than some giant models, which makes running it on modest hardware feasible. Alibaba specifically optimized it for edge devices like laptops and even high-end mobile phones, as noted by their ability to deploy on Snapdragon 8 Gen1 phones with acceptable speed. The model supports 4-bit quantization of the Thinker, significantly reducing memory footprint with minimal loss in accuracy. Internal benchmarks show that Qwen2.5-Omni can achieve real-time or near real-time performance: for instance, generating speech with low latency thanks to the streaming Talker. This efficiency means enterprises can deploy Qwen2.5-Omni in-house or on-device to handle sensitive data without always relying on cloud APIs. The compact size also lowers the cost of scaling up deployment (running many instances for many users). In summary, Qwen2.5-Omni is efficient enough for practical deployment while still delivering advanced multimodal AI capabilities.
Enterprise-Grade Workflow Integration: The model was built with enterprise use cases in mind, supporting advanced workflows like Retrieval Augmented Generation (RAG), process automation, and complex multi-step reasoning. For example, in a customer support setting the model could take an audio complaint from a user, transcribe and understand it, retrieve relevant knowledge base articles (with a retrieval tool), and then formulate a helpful answer – even verbally explaining it back to the customer. Its ability to handle tools and long contexts means it can ingest company documents or knowledge bases as context (RAG) and use that information to respond accurately. Automation scenarios, such as monitoring sensor data (audio signals, images from cameras) and triggering alerts or actions, can leverage Qwen2.5-Omni to interpret those signals in context (e.g. “alert if machine sound indicates an anomaly”). Moreover, the model’s strong multilingual and multimodal understanding is useful for global enterprises dealing with diverse data. All these strengths combine to make Qwen2.5-Omni a powerful generalist model for building AI agents that operate in real-world environments (listening, seeing, reading, and acting as needed).
In summary, Qwen2.5-Omni’s core strengths lie in comprehensive multimodal reasoning, long-form and multilingual understanding, structured output/tool-use capability, and efficient deployment, making it a versatile foundation for complex AI systems. It is an improvement over earlier Qwen models in that it unifies vision, audio, and language in one model and shows enhanced multimodal reasoning compared to those earlier internal iterations.
Developer Use Cases (Agents, RAG, Enterprise Automation)
With its broad capabilities, Qwen2.5-Omni opens up many exciting use cases for developers and enterprise teams. Below are some developer-focused scenarios where Qwen2.5-Omni can be applied:
Intelligent Voice Assistants and Agents: Qwen2.5-Omni can power virtual assistants that truly understand voice inputs and respond with speech. For example, one can build a voice-based customer service agent that not only hears the customer’s question, but also understands the content of an image the customer sends. Imagine a tech support agent where a user can say, “Here’s a photo of the error message I see on screen” and play a warning sound, and the agent (backed by Qwen2.5-Omni) can interpret both the image (reading the error text) and the audio (recognizing the warning tone) to provide help. Because Qwen2.5-Omni outputs speech, the agent can reply by talking to the user, making interactions natural. These multimodal agents can be deployed as mobile apps or on devices (since the model is relatively lightweight), enabling on-the-go assistance.
Assistive Technology for Accessibility: The model’s ability to describe visuals and generate audio makes it ideal for aiding users with visual or hearing impairments. For instance, helping visually impaired users navigate their environment is a touted use case. A smartphone app could use the phone camera feed and microphone: Qwen2.5-Omni would analyze the live video to describe surroundings or read signs aloud, and listen for user questions (“what does this sign say?”) to answer them. Similarly, it can convert written text or images into spoken descriptions in real-time. This “see and talk” capability can significantly enhance accessibility tools.
Multimodal Content Analysis and Generation: Enterprise teams can use Qwen2.5-Omni for analyzing rich media content. For example, in marketing or media companies, the model could review a video advertisement (images + audio) and generate a textual summary or extract key points. It could also answer questions like “How many scenes does this video have and what background music is playing?”. In security or compliance, the model might monitor video feeds and alert if certain audio-visual events occur (like detecting a loud crash sound plus visual motion, indicating an incident). The model’s ability to integrate modalities is particularly useful for video analytics – e.g. offering step-by-step cooking guidance by analyzing a cooking video: Qwen2.5-Omni can look at the ingredients shown in the video and narrate the next steps in the recipe for the user.
Enterprise Knowledge Assistants (RAG workflows): Qwen2.5-Omni can be the core of an enterprise assistant that answers employees’ or customers’ questions by consulting internal documents. In a Retrieval-Augmented Generation setup, when the model is asked a question, a retrieval system can fetch relevant documents (which may include text, scanned images, even audio transcripts). Qwen2.5-Omni can then consume those as part of its input (it can read the text or parse images of scanned pages, etc.) and produce an informed answer. For example, a user might ask in voice, “What does our 2022 safety manual say about fire extinguisher use?” The system retrieves the manual page (image/PDF), and Qwen2.5-Omni can read the image text and answer, even verbally. This dramatically improves automated Q&A in enterprise settings by combining multimodal input support with up-to-date retrieved knowledge.
Automation and Control Systems: Through its tool-use ability, Qwen2.5-Omni can also serve as the “brains” of automation. Consider an IoT scenario: an industrial agent that listens to machine noise (audio input), detects anomalies (e.g. an unusual vibration sound), then references technical diagrams (images) or sensor readings (text data) to diagnose an issue, and finally triggers an action (by outputting a structured command for a maintenance robot to execute). In home automation, a voice-controlled agent could see through a camera and hear commands – for example, a user says “Is the stove still on?” and the agent checks a camera image of the stove and responds with speech, possibly also controlling IoT devices if needed. Qwen2.5-Omni’s versatility enables a single model to interface with many parts of an automated workflow (vision for state, audio for commands, text for logs, etc.).
Interactive Education and Creative Applications: Developers can also use Qwen2.5-Omni to build applications like interactive tutors or creative tools. An educational app might allow a student to upload a diagram or chart (image) and ask questions about it verbally – the model can answer in a spoken explanation. Or a language learning app could show an image or play an audio clip in one language and have the student ask for a translation or description in another language, with Qwen responding in speech. On the creative side, one could imagine multimodal storytelling – e.g. the user provides an image and a theme, and the model generates a narrated story (text + audio) about that image.
These are just a few examples – the key point is that Qwen2.5-Omni can serve as a general-purpose AI agent that processes the same kinds of inputs a human might (sights, sounds, text) and produces helpful responses. Its deployment-friendly size means these capabilities can be delivered in products ranging from cloud services to mobile apps. By combining perception and generation across modalities, Qwen2.5-Omni enables developers to create more natural and powerful AI-driven experiences.
(In implementing such use cases, developers should be mindful of the model’s limitations – see the Limitations section – and ensure proper testing and safeguards, especially for critical applications.)
Python Integration Examples
To demonstrate how developers can start using Qwen2.5-Omni, let’s look at a few Python code examples. These will show how to load the model, run a multimodal prompt, and handle its outputs. We will use the Hugging Face Transformers interface, as Qwen2.5-Omni is available on Hugging Face Hub.
Before coding, make sure you have the necessary packages installed. You’ll need a recent version of transformers that includes Qwen2.5-Omni support, as well as the Qwen utilities for multimedia processing. According to the model documentation, you should install the Qwen Omni preview of transformers and the qwen-omni-utils package:
pip install git+https://github.com/huggingface/[email protected]
pip install qwen-omni-utils[decord] -U
The qwen-omni-utils provides convenient functions for handling images, audio, and video inputs (and requires FFmpeg; decord is an optional library for faster video loading).
Now, here’s a Python example to load Qwen2.5-Omni and run a multimodal prompt:
import torch
from transformers import Qwen2_5OmniForConditionalGeneration, Qwen2_5OmniProcessor
from qwen_omni_utils import process_mm_info
import soundfile as sf
# 1. Load the Qwen2.5-Omni-7B model and processor
model_name = "Qwen/Qwen2.5-Omni-7B"
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
processor = Qwen2_5OmniProcessor.from_pretrained(model_name)
# 2. Prepare a conversation with mixed modalities
conversation = [
{"role": "system", "content": [
{"type": "text", "text": "You are Qwen, a helpful AI assistant that can see images and hear audio."}
]},
{"role": "user", "content": [
{"type": "image", "image": "/path/to/photo.jpg"}, # an image file
{"type": "audio", "audio": "/path/to/question.wav"}, # a spoken question in audio file
{"type": "text", "text": "Please describe the image and answer the spoken question."}
]}
]
# 3. Preprocess inputs for the model
USE_AUDIO_IN_VIDEO = True # (if we had video; not needed here but kept for completeness)
text_inputs = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = processor(text=text_inputs, audio=audios, images=images, videos=videos,
return_tensors="pt", padding=True, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = inputs.to(model.device) # move data to model's device (GPU)
# 4. Generate a response (text + optional audio)
output = model.generate(**inputs) # by default, return_audio=True for full output
text_tokens = output[0]
audio_tokens = output[1] # the Talker’s audio output tokens
# Decode the text and audio outputs
response_text = processor.batch_decode(text_tokens, skip_special_tokens=True)[0]
sf.write("response.wav", audio_tokens.reshape(-1).detach().cpu().numpy(), samplerate=24000)
print("Assistant text response:", response_text)
print("Speech saved to response.wav (play this file to hear the answer).")
In this example, the user provided an image and an audio clip (containing a spoken question) along with a text prompt. The model will process both the image and the question from the audio, and then generate an answer. The answer will be available as text (response_text) and also as speech audio saved to response.wav. The model.generate call returns both text token IDs and audio waveform tokens simultaneously. We then decode the text with the processor, and use soundfile to write the raw audio data to a WAV file (at 24 kHz, the model’s default speech sampling rate).
A few notes on this code:
- We used
device_map="auto"which will load the model across available GPUs automatically (if you have a multi-GPU setup, it can shard the model). Qwen2.5-Omni’s weights (7B) can typically fit on a single 24 GB GPU in BF16 precision, but for generating audio you might benefit from using multiple GPUs (one for Thinker, one for Talker). The code above keeps it simple; for heavy usage, refer to multi-GPU examples in the docs. - The
apply_chat_templatefunction is used to format the conversation into the model’s expected prompt format. In this case, it likely concatenates the system and user content, and adds an end-of-conversation token. Theprocess_mm_infoutility loads the actual image and audio files and prepares tensors for them. Under the hood, images are transformed, audio is loaded (and possibly segmented), etc., so thatinputs = processor(...)yields a batch with all needed modalities. - We set
USE_AUDIO_IN_VIDEO = Truejust to demonstrate the flag that would include audio tracks if the user content had a video with sound. It’s not actually needed for pure image+audio as in our example. This flag and similar parameters allow controlling whether the audio encoder should consider audio inside video files, etc.. - The model by default will produce both text and audio outputs. If you only want text (disabling the Talker), you can either call
model.disable_talker()after loading the model or pass an argument likereturn_audio=Falsetogenerate. This will skip the audio generation to save time/compute. - The speech output voice by default is a certain timbre (the “Cherry” voice, which is a female voice). The open-source checkpoint supports at least two voices (Cherry and Ethan). In the Alibaba Cloud API, you can actually choose from four voices (e.g. Cherry, Ethan, Serena, Chelsie) via a parameter. For local usage, changing the voice might require using a different checkpoint or adjusting a setting exposed in
Qwen2_5OmniProcessor(the docs mention two voices available). By default, you’ll get a pleasant natural voice for the speech.
This Python example hopefully shows that using Qwen2.5-Omni is quite similar to using any Hugging Face transformer model, with just a bit of extra preprocessing for multimodal inputs and a postprocessing step for audio output.
REST API Usage Examples
For production deployments, you might prefer to host Qwen2.5-Omni behind a RESTful API. The good news is that Qwen2.5-Omni supports the same API format as OpenAI’s ChatGPT (chat completions). In fact, Alibaba provides a cloud service (DashScope) where Qwen2.5-Omni can be accessed via OpenAI-compatible REST endpoints. Alternatively, you can self-host the model (e.g., using the open-source vLLM server or text-generation-inference) to serve a similar API locally.
Using Alibaba Cloud’s API (DashScope): If you have an API key from Alibaba Cloud, you can hit their endpoint with the OpenAI client library. For example, in Python:
import openai
openai.api_key = "YOUR_API_KEY"
openai.api_base = "https://dashscope.aliyuncs.com/compatible-mode/v1"
response = openai.ChatCompletion.create(
model="qwen-omni-turbo",
messages=[
{"role": "system", "content": "You are Qwen, a multimodal assistant."},
{"role": "user", "content": "【image】What is shown in this image?"}
],
files={"image": open("cat.png", "rb")},
stream=False
)
print(response['choices'][0]['message']['content'])
This snippet illustrates an OpenAI-like call where we pass a system and user message. We include an image file in the request (the exact mechanism may vary; here we conceptually show sending an image). The model name is "qwen-omni-turbo" in the cloud service (which likely corresponds to an optimized version of Qwen2.5-Omni). The response comes back with the assistant’s answer in message['content']. Additionally, one can request audio output by adding modalities=["text","audio"] and an audio dict with voice settings, as shown in the official example – the API would then return chunks including base64-encoded audio that you need to decode (as done in the code example from the Qwen repo).
Using a local server (vLLM) with cURL: If you host Qwen2.5-Omni yourself (for example, using vLLM for fast inference), you can get a REST endpoint on localhost. Suppose you launched the server and it’s running at http://localhost:8000/v1 (the path mirrors OpenAI’s API). You can then call it with a JSON payload. For instance, using curl from the command line:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": "https://example.com/pic.jpg"}},
{"type": "text", "text": "Please describe this image."}
]}
]
}'
This POST request sends a chat completion query to the local Qwen server, including an image (by URL) and a text prompt. The server will respond with a JSON containing the assistant’s reply, which in this case would likely be a description of the image. If audio output was requested (with appropriate parameters), the response might stream chunks with audio data (depending on the server’s implementation). The above format demonstrates how modalities are included in the JSON: by using a list for the "content" field of a message, where each element has a "type" and the corresponding data or URL.
Integration Tips: Because Qwen2.5-Omni’s API format aligns with OpenAI’s, existing applications that currently call OpenAI’s chat completions can be adapted to use Qwen by simply changing the API endpoint and model name. This makes it straightforward to swap in Qwen2.5-Omni as a drop-in replacement in many cases. Backend teams can also containerize the model (Alibaba provides a Docker image for Qwen-Omni) and scale it with standard orchestration tools, exposing a REST endpoint internally or publicly as needed.
Whether using the cloud API or a self-hosted solution, developers should ensure that the content is formatted correctly (especially for multimedia data) and that they handle streaming responses if enabling them. Also note that, currently, not all server implementations may support the audio streaming out-of-the-box (for example, the vLLM serving might default to text-only responses until it fully supports the Talker component). Always refer to the latest documentation of the serving solution for specifics.
Prompt Engineering for Multimodal Tasks
Crafting effective prompts for Qwen2.5-Omni involves not only typical language model prompt techniques but also correctly incorporating different modalities and instructing the model on the desired format of output (text vs speech, structured vs freeform, etc.). Here are some guidelines and tips for prompt engineering with this model:
Role (System) Instructions: Use the system message to clearly establish the context and persona of the AI. For Qwen2.5-Omni, it’s useful to remind the model that it can see and hear. For example, a system prompt might say: “You are Qwen, an AI that can perceive images, audio, and text, and respond with text and speech.” This primes the model to expect multimodal inputs and to utilize its full capabilities. The official examples often include a system content like “You are Qwen, a virtual human… capable of perceiving auditory and visual inputs…”. This helps the model not to ignore image/audio parts of the prompt. You can also use the system message to establish behavior (politeness, tone) or constraints (like refusing certain requests), as you would with other chat models.
Formatting Multimodal Inputs: When prompting, each image, audio, or video should be referenced in the message in a structured way. If using the API/JSON approach, follow the content schema shown earlier ({"type": "image", "image": "...path..."}, etc.). If using the Python processor, provide the file paths or URLs appropriately in the conversation structure as we did in the code example. The important thing is to ensure the model actually receives the non-text data. In a raw text prompt scenario (like if you were using the model in pure text mode), you might use placeholders or special tokens for media (e.g. <image> or a caption like “[Image of a cat]”), but the recommended method is to use the structured input approach since Qwen2.5-Omni is designed to handle those directly.
Prompting for Output Modality: By default, Qwen2.5-Omni will produce both text and speech (if not disabled). If you only want a text answer (for example, in a setting where audio output isn’t needed or feasible), it’s best to disable the Talker as mentioned (one-time setting per session). Conversely, if you want the model to speak, ensure your system can capture the audio tokens. You typically do not need to explicitly ask the model to “say it out loud” – if Talker is enabled, it will automatically produce the speech waveform corresponding to any text it generates. However, you could instruct the style of speech via text, like “Speak this answer in a cheerful tone.” The Talker might not perfectly capture “cheerful” vs “serious” tones beyond what the selected voice can do, but it might adjust phrasing. In general, to change voice you would switch the voice setting rather than prompting (since voice is more like a parameter).
Structured Output (JSON, Lists, etc.): If you need the model’s answer in a certain format (for example, JSON for further processing), you should clearly specify that in the user prompt. For instance: “List the following information in JSON format with keys X, Y, Z.” Qwen2.5-Omni is quite capable of following formatting instructions due to its training on instructions. It can output tables, lists, or code snippets as asked. Always double-check the format, especially if the output will be parsed by another system. The model may include explanations or extra text if not explicitly constrained, so you might need to say “Only output JSON, no extra commentary.”
Use of Few-Shot Demonstrations: If a particular prompt format is tricky, you can include a few-shot example in the prompt (especially in the system message) to guide the model. For example, to encourage the model to call a tool or output a function call, you might show a fake dialogue where the assistant responds with a <search> action. Or to get a certain style of image description, you could give a short example: “User: [image] describe image. Assistant: (A detailed description)…”. Few-shot prompting can help align outputs to your needs without fine-tuning.
Managing Personality and Behavior: One operational note: when audio output is enabled, Qwen2.5-Omni does not support on-the-fly system prompt changes via the usual API parameters. In other words, you can’t easily inject a new style or persona prompt mid-conversation if expecting spoken output. The recommended approach is to bake those instructions into the conversation context. For example, if you want the assistant to behave as a friendly tour guide, you might start the conversation with a user message like: “You are a tour guide.” and the assistant acknowledging it, before the actual questions. The Qwen team suggests adding persona instructions as part of the dialogue if using audio output, since the model’s Talker will follow along with whatever the Thinker has generated. This is a subtle point, but important: plan the conversation prompt such that the model’s tone and style are established early on, rather than trying to override it later.
Prompt Length and Content: Because Qwen2.5-Omni can handle long contexts, you have room to include relevant details in your prompt. For example, for a complex question you might include a text passage (as a system or user message) along with an image. The model can take it all into account. However, keep in mind that extremely large inputs (like very long videos or many high-resolution images at once) will tax memory and could slow down inference. If needed, break down a task: e.g. process a video in segments. The prompt should also avoid ambiguity with multiple modalities. If, for instance, you provide two images and an audio clip, be clear in your question about what you want (e.g. “compare these two images” or “relate the audio to the image”).
Multi-turn Conversations: Qwen2.5-Omni supports multi-turn dialogue, meaning you can have back-and-forth interactions. The model will remember previous mentions of images or content from earlier in the conversation. For example, you could show an image in turn 1 and discuss it in turn 2 without re-sending the image, since the Thinker retains context. When engineering prompts in multi-turn settings, use the roles (user, assistant) properly and maintain the conversation history. The context length will allow a good number of turns even if they include media (though each image/video counts as many tokens after encoding). When the context grows too large (close to the limit), you might need to summarize or omit very old turns to conserve space.
In essence, prompt engineering for Qwen2.5-Omni involves thinking in multiple modalities. Provide clear instructions, structure your input data, and specify the desired output format. Leverage the system message for initial guidance and be mindful of how audio output mode might affect prompt usage. With these practices, you can effectively harness the full power of Qwen2.5-Omni in your applications.
Hardware + Deployment Options
Deploying Qwen2.5-Omni can be done on a range of hardware, from powerful GPU servers to edge devices, thanks to its optimized design. Below are key considerations and options for running the model:
Model Variants – 7B and 3B: The primary release is Qwen2.5-Omni-7B, which offers the best performance. Alibaba has also released a smaller Qwen2.5-Omni-3B model. The 3B version is useful for resource-constrained scenarios, albeit with some trade-off in capability and accuracy. If you need to deploy on very low-power hardware (like mobile phones or single-CPU systems), 3B might be the only feasible option. For most enterprise use cases, 7B is recommended, but 3B could serve as a fallback or for experimentation.
GPU Requirements: Running the 7B model with full precision typically requires a modern GPU. For example, in BF16 (half precision), inference on a single image or short text might fit in ~16 GB of VRAM, but for handling audio/video, the memory usage increases. The official benchmarks show that analyzing a 15-second video input with the 7B model in BF16 needed around 31 GB of GPU memory, and up to 60 GB for a 60-second video. These are theoretical minima; overhead can make actual usage ~1.2× higher. This implies that for heavy multimodal tasks (long videos), multi-GPU setups or GPUs like A6000/A100 with 80GB might be needed. However, if your use case is primarily text with occasional images or short audio, a 24 GB GPU (like an RTX 3090 or A5000) should suffice with BF16 and optimizations. For pure text tasks or short prompts, even 12 GB might work with 7B.
CPU or Edge Deployment: Interestingly, Qwen2.5-Omni has been demonstrated on mobile SoCs via MNN (Mobile Neural Network), an inference engine. Alibaba provided MNN models and reported that on a Snapdragon 8 Gen1, the 7B model could run with about 5.8 GB of memory usage. The speeds on mobile (~17 tok/s for Thinker prefill) suggest semi real-time operation is possible on phones. Running on CPU (desktop/server CPU without GPU) is also possible, especially with 4-bit quantization, but expect much slower generation. For non-real-time batch tasks (e.g., processing a dataset of images overnight), CPU inference might be acceptable. Generally, to deploy on the edge, use the 3B model or quantized 7B and leverage any available neural accelerators (mobile NPUs, etc.).
Memory Optimizations – Quantization and Offloading: To make deployment easier on limited hardware, Qwen2.5-Omni supports 4-bit quantization of the Thinker using GPTQ or AWQ methods. Quantizing the model can dramatically reduce VRAM needs (almost 4× smaller footprint). The Qwen team also implemented an optimization to load weights on-demand and offload unused parts to CPU memory during inference. This means the peak VRAM can be kept lower than otherwise by swapping out layers when not active. Additionally, they converted the audio codec (code2wav) to stream, avoiding a large upfront memory allocation. These improvements are aimed to let Qwen2.5-Omni run on GPUs like RTX 3080 (10 GB) or 4080 (16 GB) which are more common. If using the Hugging Face pipeline, look for the GPTQ or AWQ versions of the model (they provided separate checkpoints for those) and use BitsAndBytes or relevant loaders.
FlashAttention 2: It is highly recommended to enable FlashAttention-2, an optimized attention algorithm, when running Qwen2.5-Omni. FlashAttention can significantly reduce memory and increase speed for large context windows. The Qwen repo shows how to enable it via the attn_implementation="flash_attention_2" flag when loading the model. If you install the flash-attn2 library and turn it on, you’ll likely see better throughput, especially for multi-modal input which tends to create long token sequences (imagine an image or audio is many tokens). This is a simple yet effective tweak for production use.
Multi-GPU and Distributed Deployment: Qwen2.5-Omni can be deployed across multiple GPUs. The model loading with device_map="auto" already will chunk the model layers across GPUs if available. Another approach is running the Thinker on one GPU and Talker on another (since Talker has its own parameters). The repository mentions launching the model with separate --thinker-devices and --talker-devices flags for their demo scripts. In an enterprise setting, you might dedicate one GPU for the language part and one for the speech part for better real-time performance. Also, using inference servers like vLLM or HuggingFace’s text-generation-inference can manage multiple requests efficiently. vLLM is highlighted as a great option for fast serving of Qwen2.5-Omni, as it can batch together prompts and handle token streaming effectively. If deploying on Kubernetes or similar, containerize the model (the official Docker image qwenllm/qwen-omni:2.5-cu121 is a good starting point) and be mindful to enable IPC and fast networking (since large multimedia data might be transmitted).
Cloud vs On-Premise: If you prefer not to host the model yourself, Alibaba’s cloud service offers it via API (as discussed). This might be preferable for production if you need scalability and don’t want to maintain GPU servers. But for data privacy or cost reasons, many enterprises will opt to run Qwen2.5-Omni on-premise. The open-source nature and the above optimizations make on-prem viable. For example, an enterprise could run Qwen2.5-Omni-7B on a single A100 GPU server and serve dozens of requests per minute (with partial GPU offloading) – or even run the 3B model on CPU servers for lighter loads.
Monitoring and Logging: When deploying, treat Qwen2.5-Omni as you would other ML models: implement logging of requests (especially important if feeding user images/audio, for debugging), monitor latency (to catch any slowdowns if inputs get too large), and resource usage. Speech output generation is typically slower than text (generating waveform tokens can be time-consuming), so if low latency is critical and voice is optional, consider turning off the Talker to speed up responses. Alternatively, one could generate text with Qwen and use a separate, faster TTS system for voice – but that might sacrifice some quality and the tight alignment Qwen’s joint model provides. It’s a trade-off to evaluate per use case.
In summary, Qwen2.5-Omni is deployable in many environments. Use the 7B model on GPUs for best performance, leverage quantization and FlashAttention to fit smaller GPUs or multiple instances, and consider the 3B model or cloud service for edge cases. The fact that it’s open-source and comes with Docker images and integration guides lowers the barrier to getting it running in production. Alibaba’s emphasis on edge deployment (mobile, PC) means that as the software matures, we might see even more efficient runtimes for Qwen2.5-Omni, making it one of the most accessible multimodal AI models for developers.
Performance Considerations (Latency, Context, Scaling)
When using Qwen2.5-Omni in real-world applications, it’s important to understand how it performs in various dimensions – such as inference speed, latency (especially for streaming interactions), and how it scales with longer inputs or multiple concurrent requests.
- Latency and Streaming Behavior: Qwen2.5-Omni is specifically designed for real-time streaming interactions. In a voice chat scenario, the model can start generating an answer even as it’s still receiving the user’s speech. The architecture’s block-wise processing and separate Thinker/Talker allow it to achieve low latency responses. For example, as soon as the first few seconds of a user’s question are processed, Qwen2.5-Omni might begin formulating an answer and the Talker can start emitting speech. This streaming output means users perceive a faster response, similar to how human conversation overlaps listening and speaking. In practice, you can expect a small initial delay (for the model to process the first chunk), then a steady stream of spoken words. The official demos show that Qwen2.5 can achieve truly interactive speeds, which is a big leap for multimodal models (many older models had to wait for the entire input to finish). Keep in mind that achieving this in your deployment requires using the streaming mode in the API (for example, the OpenAI-compatible API supports
stream=Truewhich Qwen2.5-Omni uses by default). If you disable streaming and wait for full completion, you’ll incur more latency, especially for long outputs. - Throughput and Batch Processing: If you need to handle many requests or very large inputs, consider the model’s throughput. The Thinker can generate text at on the order of tens of tokens per second on a high-end GPU (e.g., ~50 tok/s in some measurements for 7B). The Talker’s generation of audio tokens can also reach dozens of tokens/sec. These numbers suggest that short answers (a couple sentences) are produced very quickly (within a second), while long answers (several paragraphs or long speeches) will take a few seconds. Qwen2.5-Omni supports batching of multiple inputs to improve throughput – you can combine different conversations in one forward pass if you set
return_audio=False(text-only). This is useful on a server: for instance, processing 4 text requests together can amortize the GPU overhead. However, if audio output is needed, batching becomes trickier since each conversation’s audio must be decoded separately. In high-volume scenarios, a practical approach might be to have one instance of the model dedicated to text-only requests (batching them), and another for requests that need speech output, depending on demand. - Context Length Impacts: The context length (number of tokens from all inputs) affects performance. Longer prompts mean more computation per token generation (attention is O(n^2) in length). Qwen2.5-Omni’s efficient attention (FlashAttention2) helps, but if you feed in, say, a 5,000 token transcript plus an image, expect slower responses than a 50 token prompt. Also, very long contexts increase memory usage (as noted in the GPU requirements for long videos). If you see the model slowing down or nearly running out of memory, you might be hitting those limits. The model card references a variant (Qwen2.5-Max or 1M) designed for extreme context lengths, but Qwen2.5-Omni itself likely targets up to 8K or 16K token contexts effectively. For most uses, that’s plenty (e.g., a few images and a page of text). If you need to process something like an entire book with images, consider chunking the task.
- Scaling Concurrent Users: To serve multiple users, you can run multiple model instances or use multi-threaded serving with an async model like vLLM. Qwen2.5-Omni on vLLM will automatically concatenate and serve prompts in parallel, maximizing GPU utilization. That means if one user is waiting on a long response, the GPU can still start processing another’s request in the gaps. This continuous batching dramatically improves overall throughput for many short requests. So, if building a service, choosing the right serving backend (like vLLM or TGI) can be more important for scaling than the raw model speed.
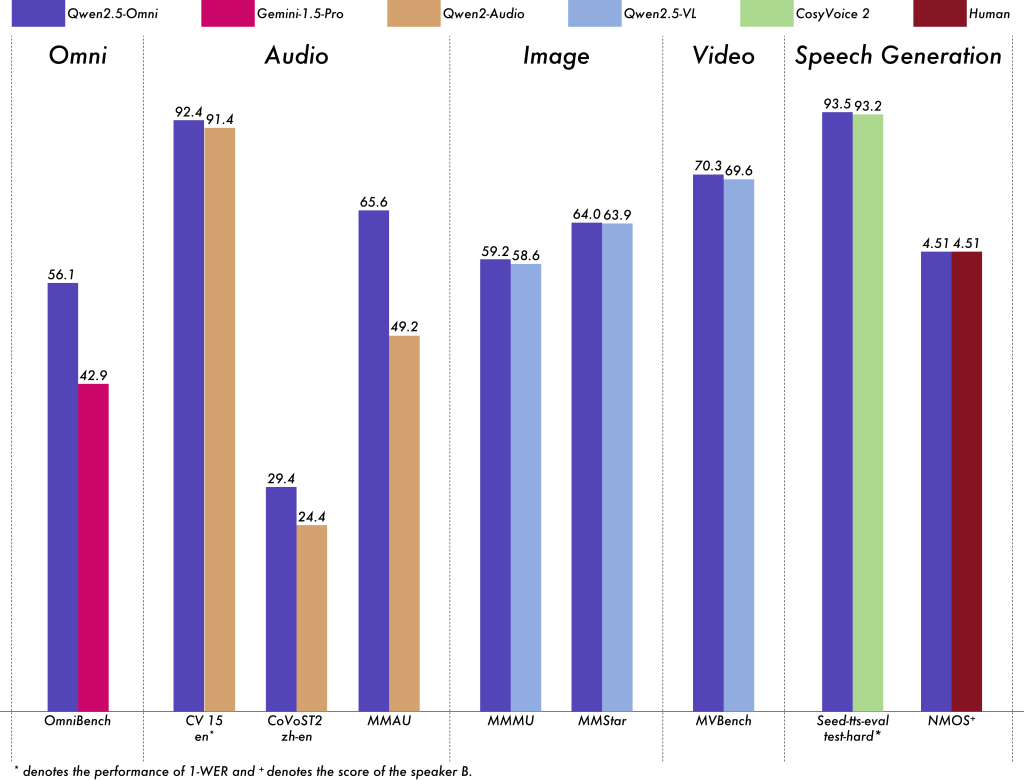
- Benchmark Performance: Qualitatively, Qwen2.5-Omni has been benchmarked and it outperforms or matches larger models in many multimodal tasks. For example, in speech recognition it was on par with models specialized for ASR, and in image QA it was close to state-of-the-art for its size. It even was comparable to human-level naturalness in speech generation on certain metrics (e.g., a Mean Opinion Score ~4.5, close to human 4.51)【22†Image】. While we avoid direct comparisons here, it’s safe to say Qwen2.5-Omni is very strong relative to other open models of similar scale. This means you get excellent accuracy without needing a gigantic model, which again helps with performance (since a 7B model is much faster than a 70B one).
- Limits of Streaming Output: One consideration with the streaming Talker is that the audio is generated in a sequence of small chunks. Very slight delays or imperfections might occur at chunk boundaries (though Qwen uses a sliding window decoding to minimize artifacts). The benefit is responsiveness, but if your application values a perfectly smooth TTS output over interactivity, you might consider generating the full audio then playing it (which is what non-streaming TTS systems do). Qwen2.5-Omni’s streaming TTS is one of the best in class, so this is a minor issue, but worth noting for high-quality audio needs.
- Resource Monitoring: It’s wise to monitor the GPU memory and load when running Qwen2.5-Omni under production conditions. If you notice memory spikes (especially with varying input sizes), you might employ strategies like limiting max video length, resizing images to a smaller resolution before input, or turning off audio decoding for certain requests. The model is new, and as with any complex system, finding the sweet spot for performance may require tuning these parameters.
In conclusion, Qwen2.5-Omni offers real-time capable performance for multimodal interactions, given appropriate hardware. Its streaming design ensures low latency, and with modern optimization techniques, you can achieve good throughput even as you scale up the number of users or length of inputs. Always test under conditions similar to your target use case (e.g., lots of short voice queries vs. a few long video analyses) to fine-tune the deployment for optimal performance.
Limitations & Operational Notes
While Qwen2.5-Omni is a powerful model, developers should be aware of its current limitations and some practical considerations when using it:
No Image or Video Generation: Qwen2.5-Omni can describe and interpret images or videos, but it cannot generate new images or video frames. Its outputs are limited to text and speech. If your application requires visual content creation (e.g. generating an image from text), you’d need to pair Qwen with a separate generative model; Qwen itself will only tell you about images, not create them.
Audio Output Voices: The model’s speech output is restricted to the voices it was trained with. The 7B checkpoint supports two voices (one male, one female presumably), and the cloud API offers four voices to choose from. If you need a very specific voice or speaking style not covered by these, Qwen2.5-Omni cannot arbitrarily change its voice beyond those presets. Also, it doesn’t currently support things like emotional tone adjustments or speaking in different accents on the fly (beyond what might be achieved by phrasing in text). The speech is high-quality and natural, but somewhat general in style (suitable for an assistant).
Prompt Rigidity in Audio Mode: As noted earlier, when the Talker (audio output) is active, you cannot easily use system prompts to dynamically change behavior or do out-of-band instructions. This is an implementation quirk – essentially, the model’s API does not allow a separate “prompt” input for audio generation, so only the conversation history influences it. This means if you wanted to steer the style after some turns (like suddenly make it speak in a pirate tone), you’d have to do it through the conversation content itself. This is different from some text-only models where you can insert a new system message mid-chat. It’s a limitation to keep in mind for dialogue design.
Modal Input Constraints: Each input modality has some practical limits. For example, extremely high-resolution images will be downsampled or might be too large to encode fully. Long audio inputs (minutes long) will be handled, but at a cost of speed and memory – and there might be a cutoff depending on how you run it. The current version may not transcribe very long audio as reliably as a specialized ASR system that streams in real-time beyond a certain length. Likewise, videos longer than a minute or two might be better handled by splitting into segments for now. These are areas for future improvement (and the team has signaled working on more efficient versions).
Knowledge Cutoff & Accuracy: Qwen2.5-Omni was trained on data up to a certain point (likely 2024 or early 2025). It might not know about events or facts beyond its training data. This is a general LLM limitation. For question-answering, it’s best used with a retrieval system if up-to-date information is needed. Also, while it’s very good for its size, it can still make mistakes (hallucinations) or misinterpret inputs occasionally. For instance, misidentifying an object in an image if it’s something uncommon or interpreting an audio sound incorrectly if it’s very noisy. It outperforms previous models like Qwen2-Audio in robustness, but no model is 100% correct all the time. So critical applications should have a human in the loop or a verification mechanism.
Biases and Safety: Being trained on wide-ranging internet data, Qwen2.5-Omni may have inherited some biases or might generate undesirable content if prompted maliciously. Alibaba likely applied alignment tuning (they mention RL optimization to improve response quality). It’s documented that after RL fine-tuning, Qwen2.5-Omni’s speech output had fewer errors and inappropriate pauses. Still, as a developer, you should implement content filtering if necessary and not rely solely on the model’s built-in safeguards. Especially with images or audio, there could be sensitive content (e.g., the model describing something that might be private or graphic). Always consider user privacy – sending images/audio to a model means that data is being processed possibly on external servers if you use the cloud API.
Resource Usage: A single Qwen2.5-Omni instance with audio enabled is fairly heavy. If you try to do too many things at once on limited hardware (e.g., generate a long speech answer while taking a large video input), you may hit memory or runtime limits. Monitoring and perhaps queueing of requests is important. The model currently uses a lot of memory for long video input (as shown, 60 GB for 1 minute video in worst case). It’s not magic – combining modalities is inherently costly because you have more tokens to deal with (an image might be thousands of tokens of latent representation). If you encounter out-of-memory issues, consider strategies like resizing images, truncating audio (or using an audio preprocessing to only send relevant segments), etc.
Training & Fine-tuning: If you plan to fine-tune Qwen2.5-Omni on your own data, be aware it’s more complex than fine-tuning a text-only model. You would need a multimodal training setup (with your own pairs of images/audio and text responses, for example). This is non-trivial and also computationally expensive for a 7B model end-to-end. That said, it’s possible – the community might develop LoRA adapters or low-rank fine-tuning approaches for Qwen’s encoders and decoders. But until that matures, you mostly rely on the model’s pre-trained knowledge and prompt techniques to specialize it. One simpler scenario is instruction fine-tuning just the Thinker (text part) if you have a lot of Q&A data; but then you risk some mismatch with Talker. So, approach fine-tuning with caution and expect to invest in a solid pipeline.
Limited Support for Certain Media Types: Qwen2.5-Omni is very general, but for instance, if you gave it music audio, it can describe it to a point (it might identify genre or instruments), but it won’t compose music or separate stems. If you show it medical images like X-rays, it wasn’t specifically trained on those, so its interpretations might be superficial or wrong. Essentially, outside its training distribution, responses may vary. For niche modalities (e.g. ultrasounds, infrared images), a domain-specific model might still be better.
In operational terms, it’s wise to set user expectations properly when deploying applications using Qwen2.5-Omni. Emphasize that it’s an AI assistant and might occasionally err. Use conservative approaches for high-stakes outputs (double-check critical info, etc.). Keep an eye on updates from the Qwen team – they are likely to release improvements or guidelines over time addressing some limitations.
Developer-Focused FAQs
Finally, let’s address some common questions developers and engineers might have about Qwen2.5-Omni:
How can I run Qwen2.5-Omni on local hardware?
You can run it on a GPU-equipped machine using the Hugging Face Transformers library. Simply load the model from Qwen/Qwen2.5-Omni-7B as shown in the examples above. For acceptable performance, an NVIDIA GPU with at least ~16 GB memory is recommended (for text/image tasks). If you don’t have a powerful GPU, consider using the 4-bit quantized model or the smaller 3B variant. There’s also a Docker image provided for easy setup – you can pull that and run the demo or a server. Running on CPU-only is possible but quite slow, so it’s mainly for testing small inputs.
What input and output formats does the model support?
Input can be provided as text, image, audio, or video – or mixtures of those. When using the model via code or API, you supply images as files or URLs, audio as files/streams, etc., along with text. The output from the model is always text and/or audio. The text output is the content of the assistant’s reply (you’ll get it as a string). The audio output (if enabled) comes as a waveform (in the API it’s base64 encoded, in local use it’s a tensor you can convert to WAV). The model doesn’t output images or other formats. If you need structured text (like JSON or XML), you must prompt it accordingly – it can format its text output as requested since it’s a language model. For audio output, you can choose from a few pre-defined voices but not arbitrary styles.
How do I disable or enable the speech output?
By default, if you use the HuggingFace pipeline or the API without specifying, Qwen2.5-Omni will produce speech if the pipeline is configured to do so. In the provided code, the model returns audio when we call generate. To disable this, you have a couple of options: (1) In code: call model.disable_talker() right after loading the model, which turns off audio generation. (2) At generation time: pass a parameter like return_audio=False (as seen in some examples) so that the Talker’s output is not returned. If using the OpenAI-style API, you might simply request only text in the modalities parameter. Conversely, to ensure you get audio in the OpenAI API, include "modalities": ["text","audio"] in your request and specify the audio format (e.g., "audio": {"voice": "Cherry", "format": "wav"}). Locally, audio is enabled by default unless you disabled it as above. So, manage it via those settings. After generation, if you have audio tokens, you must decode them to a playable format (the example used soundfile to write WAV).
Can I change the voice or language of the speech output?
The model can speak in different languages depending on the response content. If you ask a question in Chinese, it will likely answer in Chinese (and the Talker will speak Chinese). So yes, it’s multilingual in speech too. For voice, the open model has a couple of voices baked in (for example, a female voice “Cherry” and a male voice “Ethan”). In the cloud API, you can choose the voice by name. In local usage, the default is one voice; switching voices might require loading a different checkpoint or a config – currently the documentation suggests only two voices are available with the 7B model. There isn’t an API to dynamically change the voice on the fly in the open source code, apart from using the provided ones. So, you can have different voices, but you’re limited to the ones the model was trained with (you cannot, for example, make it mimic a celebrity voice or a very different style without additional fine-tuning).
Can the model use tools or external knowledge (web search, calculators)?
Not inherently – Qwen2.5-Omni doesn’t have browsing or tool APIs built into it like an agent. However, you can integrate it into a larger system that provides those capabilities. For example, you could use an agent library (such as LangChain) where Qwen is the LLM that decides when to call a tool. Qwen’s strong reasoning means it can output an “action” text (like asking for a search) if prompted in that style. But you have to handle the execution of that action externally. Also, Alibaba’s API is compatible with OpenAI functions; while not explicitly documented for Qwen yet, it suggests that one could define functions and get Qwen to output a JSON for function calls. This likely requires the cloud interface and an updated openai client. In summary, tool use is possible by orchestrating Qwen as part of an agent. It won’t, on its own, perform external actions without such an orchestrator.
What are best practices for fine-tuning or customizing Qwen2.5-Omni?
Direct fine-tuning of the full model (especially including vision/audio encoders and Talker) is expensive and complex. If you have a narrow domain (say medical imaging + reports), you might consider fine-tuning just the Thinker on text (to inject domain knowledge) and maybe do a bit of vision encoder fine-tuning on your images. This would require multi-modal data. Another approach is prompt-tuning or LoRA (Low-Rank Adaptation) which might emerge from the community – attaching small trainable adapters to specialize the model without retraining everything. Until those become available, a lot can be achieved via prompt engineering and providing context (for instance, supplying a glossary or examples in the prompt). The model is quite capable out-of-the-box for general tasks. If you do attempt fine-tuning, ensure you have multimodal training code and consider the license (Apache 2.0 means you’re free to do so and even deploy commercially, but always credit the original model).
Are there any legal or licensing concerns with using Qwen2.5-Omni in my product?
Qwen2.5-Omni is released under the Apache-2.0 license, which is a very permissive open-source license. It allows commercial use, modification, distribution, etc., with no royalty or patent concerns (aside from the Apache’s standard patent clause). This is a huge advantage over some models that had restrictive licenses. So you can integrate Qwen into your enterprise product. Just remember to attribute/credit appropriately (e.g., in about pages or documentation, mention that your product uses Qwen2.5-Omni). Also, be mindful of privacy – if you use the cloud API, you might need to ensure you’re not sending sensitive data to a third-party service without clearance. For on-prem deployments, that’s less of an issue.
How do I keep up with updates or improvements to Qwen2.5-Omni?
The Qwen team actively maintains the GitHub repo and the community pages. They have a Discord for discussions and a blog for major announcements. Since the model is open source, you might see community contributions as well (e.g., someone might add support for a new feature or more voices). Keep an eye on the GitHub releases or Hugging Face model card for any new versions (like a Qwen3.0 in the future perhaps). Given the pace, it’s likely that they will continue expanding capabilities – possibly even more modalities (they hinted at integrating additional modalities down the road). Being part of the community (forums, GitHub issues) can also help you learn from others’ experiences and solutions.
Conclusion: Qwen2.5-Omni represents a significant step forward in AI, combining vision, language, and audio understanding in a single model that developers can actually use and deploy.
In this article, we dived deep into its architecture (the Thinker-Talker split), its multimodal prowess, how to use it in code, and what to watch out for in deployment. For those building next-generation AI applications – whether it’s a voice assistant that can see or an analytic tool that can listen – Qwen2.5-Omni offers a powerful foundation. With thoughtful integration and prompt design, it enables creating truly multimodal agent experiences.
As with any AI model, use it responsibly, play to its strengths, and keep innovating on top of it. Happy building with Qwen2.5-Omni!