
Qwen3‑VL is the latest open-source vision-language model from Alibaba Cloud’s Qwen team, designed for sophisticated image and video understanding integrated with text.
It belongs to the third-generation Qwen AI model series and delivers major upgrades in both visual perception and textual reasoning. Qwen3‑VL can accept both images (or videos) and text as inputs and generate natural language outputs, enabling tasks like answering questions about an image, describing a scene, reading text in images, and even controlling user interfaces via visual input. The model is released under a permissive Apache-2.0 license and available in large-scale configurations (the flagship version has ~235 billion parameters in a Mixture-of-Experts architecture).
This makes Qwen3‑VL one of the most powerful open multimodal AI systems to date, targeting not just basic image recognition but deeper visual reasoning and even agent-like behavior on visual tasks.
Unlike simple image captioning models, Qwen3‑VL is trained to handle complex multimodal interactions. For example, it can read a document image and answer questions about its content (combining OCR with comprehension), analyze a chart or diagram and provide insights, or follow step-by-step reasoning to solve a visual problem.
It supports Visual Question Answering (VQA), detailed image description, multi-image comparison, document parsing, OCR in 32 languages, and even long-duration video understanding. Qwen3‑VL’s multilingual OCR capabilities are notably strong – it can recognize text in many scripts (Latin, Chinese, Arabic, etc.) and in challenging conditions (low lighting, blurred or rotated text). Crucially, the model blends vision and language processing in a unified transformer, so its text understanding is on par with text-only large language models while incorporating visual context.
In summary, Qwen3‑VL represents a cutting-edge foundation for building AI assistants and applications that see and reason, bringing advanced visual intelligence to LLM-driven systems.
Architecture Overview: Multimodal Model Design and Context Handling
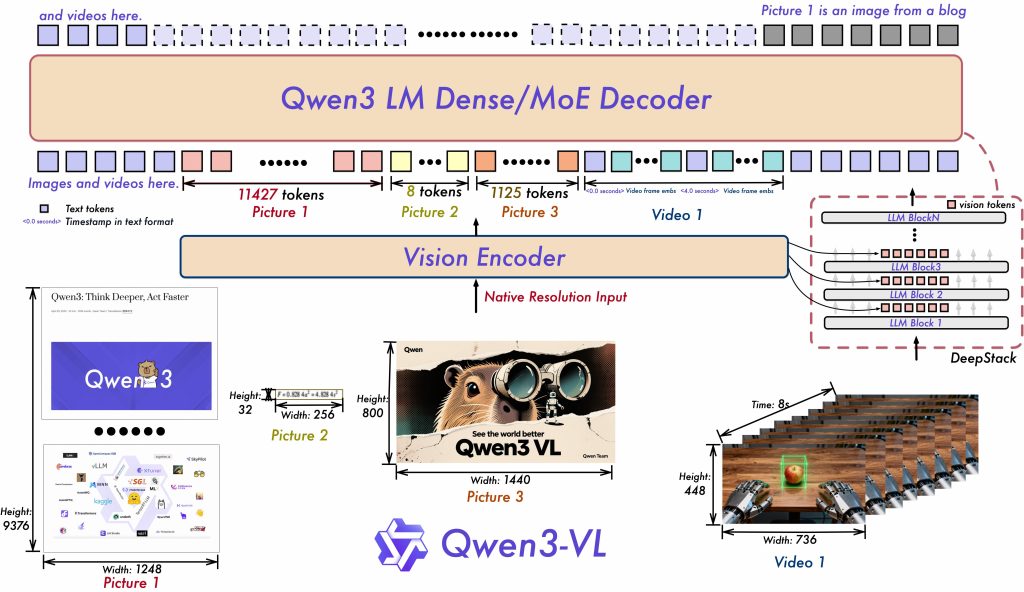
Architecture of Qwen3‑VL (simplified). Qwen3‑VL uses a hybrid transformer architecture that integrates a Vision Transformer (ViT) encoder with a large language model (LLM) decoder in a single unified framework. At a high level, images (or video frames) are encoded into visual tokens which are then fed into the LLM alongside text tokens, allowing the model to attend to both visual and textual information together. The architecture supports dense or Mixture-of-Experts (MoE) variants – for example, the flagship 235B-parameter MoE model (with ~22B parameters active per token) maximizes capacity by routing tokens to multiple expert subnetworks. Despite the MoE design, inference still demands significant computational resources (the full 235B model weights are ~471 GB), so smaller Qwen3‑VL variants (e.g. 32B, 7B, 4B, etc.) are provided for more accessible deployment on modest hardware. All versions share the same core architecture and capabilities, differing mainly in scale.
Multimodal Encoder-Decoder: Qwen3‑VL’s vision module is based on a ViT-like encoder that splits images into patches (with a default patch size of 16×16 pixels in Qwen3) and embeds them into token representations. These visual tokens are interleaved or concatenated with text tokens for joint processing by the transformer decoder. The model employs specialized positional encoding to handle both spatial dimensions and temporal sequences: an Interleaved-MRoPE scheme extends Rotary Position Embeddings (RoPE) to 2D and time, enabling the model to naturally index image patches in width/height and sequential video frames in time. In other words, the positional embeddings cover time (for video) as well as X–Y location (for image patches), which greatly improves the model’s ability to reason over long image sequences (e.g. multiple images or lengthy videos). Another innovation is DeepStack, a technique that fuses multi-level features from the vision encoder: instead of relying only on the final layer of the ViT, Qwen3‑VL incorporates intermediate visual features to capture fine-grained details. DeepStack improves image-text alignment, ensuring that even subtle visual details (small objects, fine print text, etc.) can influence the language model’s output. For video inputs, Qwen3‑VL adds Text–Timestamp Alignment, which helps the model associate parts of the text (like a question about an event) with specific frames or moments in the video. This gives more precise temporal grounding, so the model can, for example, locate when something happens in a video when answering a query.
Context Length and Long-Form Input: A standout feature of Qwen3‑VL is its extended context window. Natively it supports up to 256,000 tokens of context (yes, 256K) and even has a path to extend further to 1 million tokens for special cases. This extremely long context means Qwen3‑VL can ingest very large inputs – such as entire documents or books, lengthy conversation history, or hours of video frames – without dropping earlier parts. Achieving this required advances in scaling RoPE embeddings (the Interleaved-MRoPE mentioned) and memory optimizations. In practice, such a large context is computationally expensive, so it’s used selectively. The model’s developers advise using the long context wisely – for example, chunking long documents or videos and using retrieval techniques to avoid feeding irrelevant data, since processing hundreds of thousands of tokens will be slow and costly. Nonetheless, the ability to handle extremely long multimodal input is a game-changer for tasks like analyzing multi-page PDFs or performing QA on a full-length movie transcript with frames.
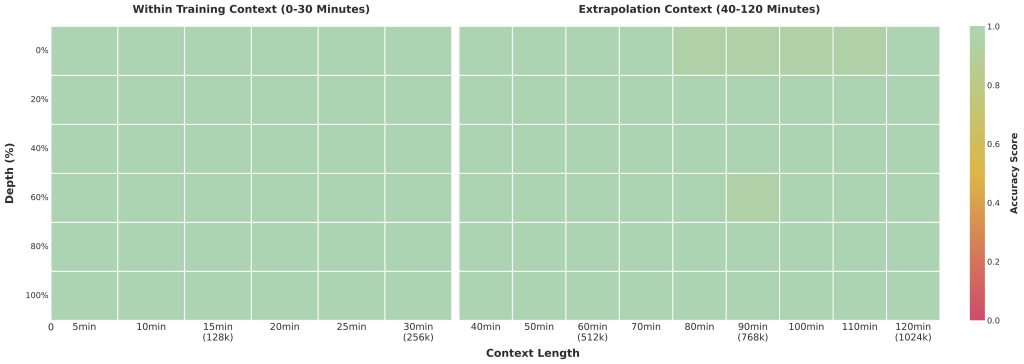
Image Resolution and Visual Token Handling: By default, Qwen3‑VL’s preprocessing will resize or downsample images to keep the number of visual tokens within a reasonable range for the transformer. The vision encoder yields one token per image patch, and the default pipeline limits the total patches to manage memory (for example, one can configure the processor to allow between 256 and 1280 visual tokens per image depending on needs). Developers have control over this via the AutoProcessor – you can set a maximum pixel budget or specify target dimensions for the image. For instance, if you need higher resolution detail, you might increase the max_pixels setting to let the model process a larger image (at the cost of more compute). Qwen3‑VL’s image encoder compresses input by a factor of ~32 in each dimension by patching and pooling, so an image of e.g. 1024×1024 pixels would result in on the order of 1024 visual tokens. The model also supports multiple images and even video as input: multiple images can be simply listed in the input message (each will be encoded in sequence), and video is handled by sampling frames. The processor can sample a video at a specified frame rate (default ~2 FPS) or take a fixed number of frames, and similarly constrain the total number of image tokens from all frames. This ensures that even long videos can be processed by selecting representative frames, and the positional embeddings will label each frame by its timestamp so the model knows the order.
Overall, Qwen3‑VL’s architecture is optimized for rich multimodal understanding: a strong LLM core augmented with vision-specific modules, extremely large context capability, and architectural tweaks for spatial and temporal reasoning. It is implemented within the standard HuggingFace Transformers framework, so developers can easily load the model and use it as they would any text generation model – but now with image and video inputs.
Supported Input Formats and Modalities
One of Qwen3‑VL’s strengths is the flexibility of inputs it can handle. It supports a wide range of image and document formats, as well as multimodal input sequences. Key supported input types include:
- Images (Photographs or Diagrams): You can input common image formats (PNG, JPEG, etc.) containing anything from natural scenes to objects, charts, screenshots, or drawings. The model will process the pixels through its vision encoder. For example, you could show it a photo and ask a question about it, or give it an illustration/diagram to analyze. High-resolution images are supported with adjustable resizing; by default the system will scale large images down so that their pixel count stays under a configured limit. This ensures the number of visual tokens isn’t too large, but developers can raise the limit if needed for detailed images.
- Screenshots and User Interfaces: Qwen3‑VL is particularly tuned for GUI screenshots from computers or mobile devices. The model can ingest a screenshot image of an application or webpage and interpret the interface – e.g. identifying buttons, menus, text fields, and their labels. This is the basis of its “Visual Agent” capability to operate UI elements. A developer can provide a screenshot and ask something like, “Which button enables dark mode?” and Qwen3‑VL will locate and read the relevant part of the image to answer (it might even output the button label or coordinates).
- Documents (Scans or PDFs): You can feed scanned documents, PDFs (converted to images), or photographs of text documents. Qwen3‑VL will perform OCR internally and extract text, while also understanding the layout and structure of the document. It supports complex formatted documents with tables, forms, or multiple columns. For example, a developer might input a scanned invoice or a research paper PDF page image – Qwen3‑VL can read the text, identify headings vs paragraphs, and answer queries about the content. Thanks to the expanded OCR covering 32 languages and improved layout parsing, it can handle multilingual documents and even tricky cases like historical prints or stylized text. Note: for very long documents (dozens of pages), splitting into pages or segments is advisable despite the large context, to keep inference efficient.
- Charts and Graphs: The model can take images of charts (plots, bar graphs, pie charts) or tables and interpret them. This means you could show it a line graph image and ask “What does this graph depict?” or “Around what value did X peak?” and expect a sensible answer. Qwen3‑VL has been trained on tasks involving data visualizations, so it can read axes labels, legend text via OCR and understand visual patterns. This unlocks use cases in data analysis and business intelligence where charts are output as images – the model can help explain or summarize them in natural language.
- Multiple Images in one query: Qwen3‑VL allows multi-image context. You can include several images in the prompt (as a list in the message content) before a question. For instance, providing two different product images and asking “What differences do you see between these products?” is supported. The model will encode each image and consider them jointly to produce an answer comparing them. Similarly, one can show before-and-after images, or a page of a document followed by a second page, etc., and ask questions that span across them. This multi-image capability is useful for tasks like consistency checking (e.g. “Find the changes between image A and B”) or combining information from multiple visuals.
- Video: Qwen3‑VL can accept short videos or sequences of frames. The input format for video can be either a direct video file (which the processor will sample frames from) or an explicit list of image frame URLs/paths provided as a “video” content type in the message. When a video is input, by default the model will take a subset of frames (e.g. grabbing one frame every half second, or a fixed number of frames) to represent the video content. You can control the sampling rate via parameters – for example, setting
fps=4to sample 4 frames per second, or directly specifyingnum_frames=128to capture a specific number of frames. This way, even a long video can be truncated to a manageable sequence of image tokens. The model’s temporal awareness (via timestamp alignment) means it tries to maintain the chronological order of events. You can ask it to describe a video, summarize what happened, or answer questions like “What occurs after the person enters the room in the video?” and it will reference the frames in order. Keep in mind that extremely long videos (hours) would produce a lot of frames; it’s usually necessary to limit frames or break the video into parts for analysis.
In all cases, the input to Qwen3‑VL is ultimately converted into a unified message format: a JSON-like structure with roles and content segments. Each segment of content can be of type "text", "image", or "video", which the Qwen3 processor and model interpret accordingly. This makes it very flexible – e.g. you could have a prompt that starts with some text context, then an image, then more text, etc. – as long as it falls within the token budget. The ability to mix modalities and vary input format opens up a wide array of multimodal workflow possibilities for developers.
Multimodal Capabilities: OCR, VQA, Captioning, and Reasoning Power
Qwen3‑VL is not just about input flexibility; it brings an array of powerful vision+language capabilities that developers can leverage. Through its training and architecture, the model demonstrates competence in tasks ranging from basic perception (like identifying objects) to complex reasoning and planning with visual information. Below are key multimodal capabilities of Qwen3‑VL:
Visual Question Answering (VQA):
Qwen3‑VL can answer free-form questions about images. This includes questions about objects (“What is the person holding?”), attributes (“What color is the car?”), counts (“How many people are in the photo?”), and more abstract queries (“Why might the cat be looking at the window?”). The model combines image recognition with world knowledge and reasoning to generate answers. It has been evaluated on standard VQA benchmarks and the Qwen team reports that its performance is competitive with the best systems, thanks to the “Thinking” edition tuned for complex reasoning. For developers, this means you can feed an image and a question and get a pretty detailed answer, often with explanations if prompted. Unlike rigid classification models, Qwen3‑VL’s generative nature allows open-ended, conversational answers.
Image Captioning and Scene Description:
The model excels at describing images in natural language. Given a scene, it can generate a paragraph describing the salient elements – for example, “A busy street intersection at night with neon signs, and a group of people waiting to cross.” This is useful for accessibility (describing images for visually impaired users) or for automatic alt-text generation. Qwen3‑VL’s captions tend to be detailed and coherent, reflecting its training on image-text pairs. It also can handle multiple images, generating comparative descriptions or noting differences if asked. Additionally, it can produce titles or brief captions if instructed, which is handy for summarizing an image in a sentence rather than a long description.
OCR and Document Understanding:
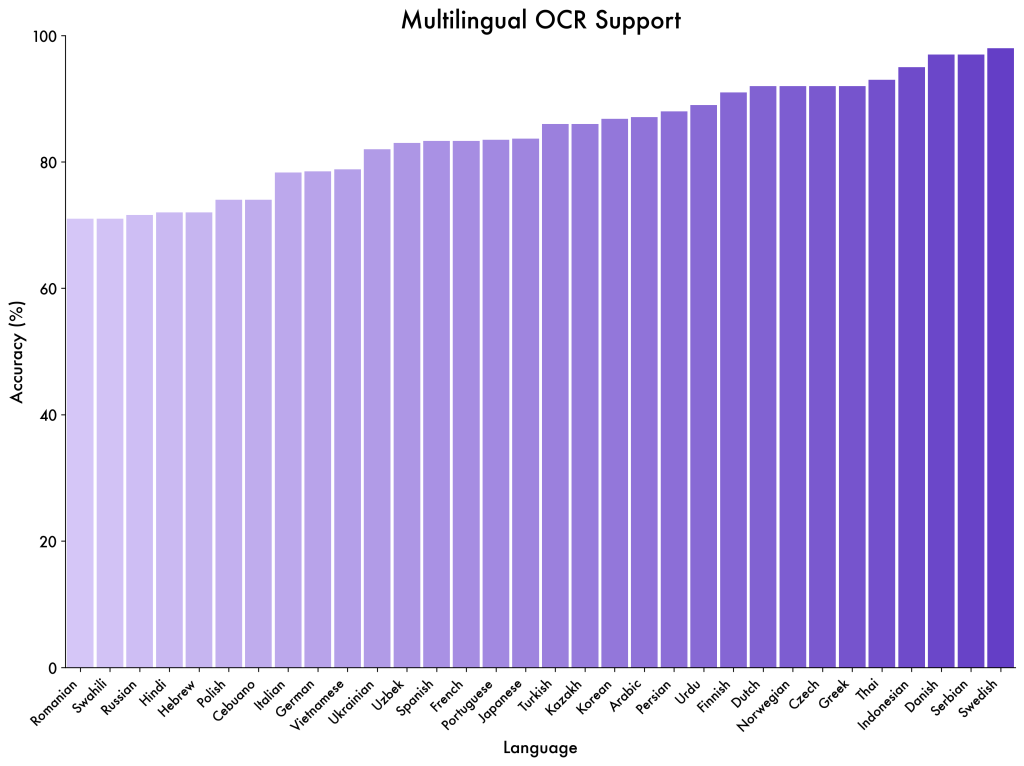
One of Qwen3‑VL’s standout features is its integrated OCR capability across dozens of languages. It can read text that appears in images, such as signs, documents, screenshots of webpages, forms, receipts, and so on. But Qwen3‑VL goes beyond just reading text – it also understands the context and layout. For example, if given an image of an invoice, it can extract key fields (date, total amount, vendor name) and present them in a structured way if prompted. The model’s training has included documents, so it learned to parse structured layouts like tables or forms: developers can ask it to provide an answer drawing on specific parts of a document (e.g. “What is the due date on this invoice image?”). Notably, OCR is supported in 32 languages, up from the previous generation’s ~19, covering languages with different scripts (English, Chinese, Arabic, European languages, etc.). It’s also robust to challenges like rotated or low-quality text. The Qwen team has introduced a special output format called Qwen HTML for document parsing, where the model can output recognized text along with HTML-like tags indicating layout structure. This is useful if you want to reconstruct the document or analyze its format. In short, Qwen3‑VL can serve as a unified OCR + interpreter, saving the need for separate OCR engines and text analysis pipelines.
Advanced Spatial Reasoning:
Qwen3‑VL is designed to understand spatial relationships in images. It can judge the positions of objects relative to each other (e.g. “the red box is to the left of the blue circle”), understand perspectives and occlusions (knowing if one object is hiding part of another), and even infer 3D structure from 2D images to some extent. This spatial understanding means the model can answer questions about layouts (like “Is the person in front of the table or behind it?”) or help with planning in physical environments. An impressive aspect is object grounding: Qwen3‑VL can output coordinates of objects in an image if requested. For instance, you might ask “Locate the cat in the image and give me its bounding box.” The model can respond with something like “The cat is at approximately (x: 150–300, y: 80–200) in the image.” This is enabled by training tasks where the model had to reference positions and the introduction of relative position embeddings. The model even supports outputting points or boxes in multiple formats, which developers can leverage to draw regions on the image or feed into other systems. This kind of capability opens the door to visual grounding tasks, such as referring expression comprehension (identify “the man next to the blue car”) or assisting robotics/AR systems that need to refer to real-world coordinates.
Multimodal Reasoning and Chain-of-Thought:
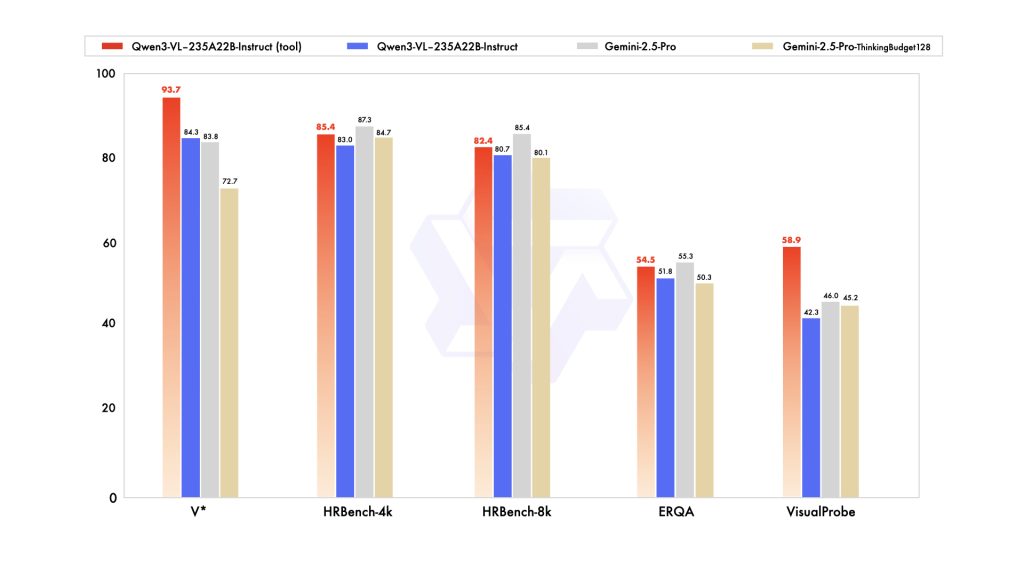
Beyond identification, Qwen3‑VL can perform reasoning tasks that involve both vision and language. The “Thinking” edition of the model is explicitly tuned to produce reasoning traces (i.e. chain-of-thought) internally. While the chain-of-thought is not usually exposed directly (unless using a special API mode), it means the model can tackle complex, multi-step problems. For example, solving a puzzle in an image that requires logic, or reading a graph and performing some analysis to answer a question (like “looking at this sales chart, which quarter had the highest growth and why?”). It excels in STEM-related visual tasks – e.g., analyzing a physics diagram or solving a math problem given as a handwritten image – due to training that emphasizes logical, evidence-based answers. Qwen3‑VL’s performance on benchmarks for compositional reasoning (where multiple clues must be combined) is state-of-the-art among open models, according to the team’s reports. For developers, this means you can trust Qwen3‑VL not just for straightforward descriptions, but also for tasks where the answer requires explaining or deducing something about the visual input, potentially even providing a step-by-step explanation if prompted to do so.
Agentic Visual Capabilities:
A very distinctive feature of Qwen3‑VL is its ability to interface with tools and perform actions based on visual input. The model was trained with a “visual agent” paradigm in mind. Practically, this means if you show Qwen3‑VL a screenshot and tell it to “click the Settings icon,” it can identify the settings icon in the image and (in a controlled environment) output an action or reasoning to that effect. Combined with an external tool executor, Qwen3‑VL can drive UI automation: e.g., read a screen, plan a sequence of clicks or text inputs to accomplish a task. This has enormous potential in RPA (Robotic Process Automation) and assistive technology. For example, given an image of a software interface, the model could output something like: “The user should tap the gear-shaped icon in the top-right corner to open settings.” Of course, the model itself won’t physically perform the action, but its output can be used by an agent framework to execute operations. Additionally, Qwen3‑VL can generate code based on visual input – the so-called “Visual Coding Boost” feature. If you show it a wireframe or a drawn UI design, it can produce HTML/CSS or even vector drawings (like a Draw.io diagram) in code form to match the image. This is an advanced capability that hints at converting visual information into actionable outputs like code, which developers could use for rapid prototyping (e.g. converting a napkin sketch of a webpage into actual HTML suggestions).
These capabilities illustrate that Qwen3‑VL is far more than a captioning model – it is a general-purpose multimodal AI. It can see, read, reason, and even plan actions. Many of these abilities can be combined in one workflow. For instance, consider an AI assistant that helps with business analytics: you could give it a PDF report (which it will parse for text and data), along with an embedded chart image from the report, and ask for a summary of insights. Qwen3‑VL can read the text, interpret the chart, and generate an integrated answer discussing both the written findings and the visual data. The range of tasks it unlocks is vast, covering domains like healthcare (analyzing medical scans and reports), education (explaining diagrams to students), finance (reading forms and charts), and much more.
Real-World Use Cases for Developers
With its diverse skill set, Qwen3‑VL enables a host of practical applications. Below are several real-world use case scenarios where developers can leverage Qwen3‑VL to build powerful multimodal systems:
Automated Document Processing: Extracting information from forms, invoices, receipts, and contracts becomes easier with Qwen3‑VL. For example, a developer can build a service where users upload a photographed receipt and the model returns a structured summary (merchant name, date, total, items purchased). Qwen3‑VL’s built-in OCR and document understanding obviate the need for separate OCR and parsing modules. Similarly, in legal or finance domains, it can help analyze PDFs by answering queries about clauses or figures in scanned documents.
Multimodal Virtual Assistant: Integrate Qwen3‑VL into a chatbot or voice assistant to handle visual queries. A user could ask, “I’ve uploaded a photo of my living room, how can I rearrange it to look more spacious?” – the assistant (powered by Qwen3‑VL) can analyze the photo and provide suggestions, combining visual scene understanding with design knowledge. In customer support, a user might send a screenshot of an error message and ask for help; Qwen3‑VL can read the error text and guide them through a solution. The model’s ability to carry on dialogue about an image makes it ideal for interactive assistant applications.
Data Analytics and Business Intelligence: Business users often have charts, graphs, or dashboards that they want insights from. Qwen3‑VL can serve as a “visual data analyst” that interprets chart images. A developer could create a tool where a user uploads a sales graph and asks questions like “Which region had the highest sales in Q3?” or “Describe the trend over the year.” The model will read the chart’s axes and legend via OCR and then analyze the visual trend to answer. This lowers the barrier for non-technical users to get insights from visual data – they can just ask questions in natural language about their charts.
Accessibility Solutions: For visually impaired users, Qwen3‑VL can power applications that describe the visual world. Developers can build mobile apps where a user takes a picture of something (their surroundings, a sign, a product label) and the app uses Qwen3‑VL to speak out a description or read the text on it. Because the model can handle a variety of content (scenes, printed text, screens), a single model can drive a comprehensive assistive tool – describing scenery, reading documents, interpreting UI screens, etc., in the user’s preferred language.
Robotics and Embodied AI: Robots or drones equipped with cameras can use Qwen3‑VL to interpret their environment and make decisions. For instance, a home robot could send frames from its camera to Qwen3‑VL and ask “Is there an obstacle on the floor?” or “Which object here is the electric outlet?” The model’s spatial reasoning and object recognition help the robot understand where things are. In more advanced scenarios, the robot can query the model for plans, like “I see this toolbox and a table, how can I get to the toolbox?” and Qwen3‑VL might respond with a reasoning about the path. The 2D and 3D grounding capabilities (identifying object positions, enabling 3D reasoning from 2D images) make it useful for any AI agent that navigates or manipulates in the physical world.
UI Automation and Testing: Qwen3‑VL’s visual agent skills are a boon for automating software tasks. Developers can create QA bots that verify if a UI is rendered correctly by having Qwen3‑VL parse a screenshot and check for expected elements (for example, confirm that a “Submit” button is present and labeled correctly). It can also be used to script interactions: given a high-level instruction like “open the Settings and enable Bluetooth,” a system could have Qwen3‑VL interpret a sequence of screenshots and output step-by-step actions (click coordinates or UI element identifiers) to accomplish that task. This is highly valuable for testing apps on different devices or for accessibility automation where the model can effectively see the interface and operate it conceptually.
Video Analysis and Summarization: In media and security, Qwen3‑VL can be applied to analyze video content. A developer might feed frames from a surveillance camera and ask “Do you see any people entering the restricted area between 3pm and 4pm?” The model can scan the frames for the presence of people and respond accordingly. Or for content creation, one might use Qwen3‑VL to generate a summary of a video (e.g. summarizing a lecture or a meeting recording by sampling frames and transcribed text). Because the model can handle long videos with many frames (thanks to the 256K context and video temporal modeling), it is suitable for building tools that digest video into readable summaries or answer questions about video content (“When did topic X get mentioned in this recorded presentation?”).
These examples barely scratch the surface – Qwen3‑VL’s versatility means developers across industries can dream up new multimodal applications. The key advantage is that a single model can replace what used to require multiple systems (e.g. an OCR system + an image classifier + a separate QA system). With Qwen3‑VL, you feed in visual data and text prompts, and get intelligent, context-aware output that can drive real products.
Python Integration and REST API Workflow
Integrating Qwen3‑VL into your applications can be done using the familiar Hugging Face Transformers library or via REST APIs. Here we’ll outline both approaches with examples, demonstrating how to send an image + text to the model and get outputs.
Using Hugging Face Transformers (Python): Qwen3‑VL is supported in transformers (version 4.57.0 or newer). You can load the model and processor as follows:
from transformers import AutoModelForImageTextToText, AutoProcessor
model_id = "Qwen/Qwen3-VL-7B-Instruct" # Example smaller model; use 235B model id if you have the resources
model = AutoModelForImageTextToText.from_pretrained(model_id, device_map="auto", dtype="auto")
processor = AutoProcessor.from_pretrained(model_id)
This will download the model weights (make sure you have sufficient VRAM or use device_map="auto" for automatic sharding across GPUs). The AutoProcessor handles image preprocessing and text tokenization jointly. Now, prepare an input message. Qwen3‑VL expects a chat-style message even for single-turn queries – basically a list of messages with roles (user/system) and content. The content can include an image. For example:
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/example.jpg"},
{"type": "text", "text": "Describe what is happening in this image."}
]
}
]
Here we have one user message containing an image and a prompt question. We can now convert this into model inputs and run generation:
# Process the message into model inputs (includes image processing and tokenization)
inputs = processor.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
inputs = inputs.to(model.device) # move data to the model’s device (GPU)
# Generate a response
outputs = model.generate(**inputs, max_new_tokens=200)
# Decode the generated tokens to text
response_text = processor.batch_decode(outputs[:, inputs["input_ids"].shape[1]:], skip_special_tokens=True)[0]
print(response_text)
When you run this, response_text will contain Qwen3‑VL’s answer, for example a description of the image. Under the hood, the apply_chat_template function formatted the prompt in the way Qwen expects (it typically adds system instructions and special tokens). The above code mirrors the official example from Qwen’s documentation. If you have multiple images or a video, you would include them in the messages list accordingly (e.g., add another {"type": "image", "image": ...} entry, or use {"type": "video", "video": ...} with a video file or frame list). The rest of the process is the same – the processor will handle merging the visuals and text.
REST API via Hugging Face Inference: If you prefer a hosted solution or want to call the model from a language other than Python, you can use Hugging Face’s Inference API or other endpoints. For instance, Hugging Face provides a cloud inference endpoint for models. You can send a POST request with your image and text. Typically, you’ll need to authenticate with a Bearer token. Here’s an example using curl with a base64-encoded image in a JSON payload:
curl -X POST "https://api-inference.huggingface.co/models/Qwen/Qwen3-VL-7B-Instruct" \
-H "Authorization: Bearer YOUR_HF_API_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"inputs": {
"image": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBD... (base64 data) ...",
"text": "Extract the table data from this document image."
}
}'
In this JSON, we provide an image (as a Data URI containing base64 JPEG data) and a text prompt. The model will respond with text, which the API returns in JSON, for example:
{
"generated_text": "The document is an invoice dated 2023-08-15 from XYZ Corp to John Doe. It lists 3 items: Widget A ($50), Widget B ($30), Service Fee ($20). The total amount due is $100."
}
The exact format may vary; some inference endpoints wrap the result in an array or include additional info. In this example, the model looked at an invoice image and returned a structured summary as requested. You could also use the OpenRouter API or Alibaba Cloud’s Model Studio endpoints, which similarly accept a message with image attachments. For example, OpenRouter allows you to specify a model like qwen3-vl and send a chat conversation (including base64 images) in JSON. Always consult the API documentation for the correct payload format and size limits – images might need to be below a certain size or encoded properly.
Output Parsing: The model’s outputs are plain text by default. If you need structured data (e.g. JSON lists, coordinates), you should prompt the model accordingly. Qwen3‑VL is generally good at following format instructions, especially in the Instruct variant. For example, if you want a JSON list of objects detected in an image, you can prompt: “List all objects you see in JSON format with their names and positions.” The model might output something like [{ "object": "cat", "bbox": [100,50,200,150] }, ...]. However, LLMs are not guaranteed to produce perfectly formatted JSON every time – for critical applications, you may need to validate and correct the output. Another best practice is to use the Thinking mode for complex queries. The Thinking edition of Qwen3‑VL can internally perform multi-step reasoning (which the API might expose in a special field or just use to improve the answer). It can be beneficial for tasks like multi-part questions or when you want the model to explain its answer. Keep in mind the Thinking mode will consume more tokens (since it generates reasoning), so use it when needed but default to Instruct for straightforward tasks.
Prompting and Formatting Best Practices
Working effectively with a multimodal model like Qwen3‑VL requires some care in how you craft prompts and handle the conversation format. Here are some best practices for prompting and formatting when using Qwen3‑VL:
Use the Structured Message Format: Always wrap your inputs in the chat message structure that Qwen expects. Even if you’re doing a single turn Q&A, format it as a user message containing the image and question (as we showed in the code example). The AutoProcessor.apply_chat_template will do this for you in Python. If calling via API, ensure your JSON follows the required schema (a list of messages with roles, etc.). This structure helps the model disambiguate what is the user query vs. the system instructions or its own answer.
Provide Clear Instructions in Text Prompts: Just as with any LLM, being explicit in your prompt improves results. If you want a brief answer, say “Explain in one sentence.” If you need a structured output, specify the format (e.g. “Answer with a JSON object” or “List the items as bullet points.”). Qwen3‑VL is capable of returning tables, lists, or code snippets as part of its text output when instructed. For instance, to get a table from an image of a chart, you might prompt: “Create a 2-column CSV where the first column is Year and second is Sales, extracted from this chart.” The model will then attempt to output something in that format. Clarity is key: mention the desired output style in the user prompt.
Leverage System Messages for Role Behavior: Qwen3‑VL, like many chat models, can take a system message that defines the assistant’s role or behavior. As a developer, you can use this to set the stage. For example, a system message could be: “You are an AI assistant specialized in analyzing images and documents. Answer concisely and prioritize factual information from the image.” This can guide the model to focus on visual evidence. In multi-turn dialogues, system instructions can also remind the model to carry over context or not to reveal certain things (like if you want it to only use the image information and not outside knowledge, you could say so in a system prompt).
Be Mindful of Token Limits and Chunking: While Qwen3‑VL has an enormous context window, you should still plan how to present input for efficiency. If you have many images or a long document, consider whether they can be processed in parts. For example, rather than one giant prompt with 50 pages of a document, you might break it into sections and have the model summarize or extract from each, possibly using a higher-level strategy (this is sometimes called Retrieval-Augmented Generation, where you fetch relevant pieces as needed). The Qwen team themselves suggest using pre-processing like separate OCR for very large documents or using retrieval to avoid filling the context arbitrarily. Essentially, use the long context when it truly adds value (e.g. analyzing temporal events in a long video, or maintaining a long conversation state), but don’t feed redundant data. This will keep responses faster and reduce cost.
Choosing Instruct vs. Thinking Models: Qwen3‑VL comes in two finetuned flavors: Instruct (for general aligned responses) and Thinking (which is enhanced for complex reasoning, possibly producing intermediate “thoughts”). In practice, the Instruct model will be more than sufficient for most use cases and will be faster. The Thinking model might shine on tasks where the model struggled to get the right answer – it might internally break the problem down better. If using the API, you might see an option to enable “thinking mode” which corresponds to this variant. Best practice is: start with Instruct for basic queries and only use Thinking for particularly challenging queries (e.g., multi-step logical problems or highly ambiguous questions that need exploration). Also note that Thinking mode can sometimes output its reasoning if not configured correctly, which might not be desirable in an end-user facing app – ensure you follow their guidance on how to use it (some APIs may hide the reasoning and only give the final answer).
Multilingual Prompting: Since Qwen3‑VL supports text in multiple languages (for both input and output), you can ask questions or get answers in languages other than English. For instance, you can provide an image with Chinese text and ask the question in Chinese, and it will answer in Chinese. Or ask it to translate the text in an image from French to English. The model’s core understanding is multilingual, but keep prompts consistent – it’s usually best to stick to one language in a single interaction to avoid confusion. Also, specify if you want the answer in a particular language: “Translate the text in the image to English.” or “回答用中文” (answer in Chinese).
Handling Uncertainty: If the model might not be sure about an answer (common in visual tasks if the image is unclear), you can encourage it to express uncertainty. For example, prompt: “If you are not sure, say you are not certain.” Qwen3‑VL will generally indicate uncertainty with phrases like “It looks like … but I’m not entirely sure.” Aligning this with user expectations is important in applications like medical or legal image analysis – you might want the model to flag low confidence rather than hallucinate. While there’s no direct probability output from the model, such instructions in the prompt can influence it to be more cautious.
By following these practices, developers can get the most out of Qwen3‑VL’s capabilities while maintaining control over format and relevance. Always remember that, as an LLM, Qwen3‑VL will sometimes guess if not constrained – so the more guidance you give in the prompt, the better the reliability of the output.
Limitations and Considerations
Despite its impressive capabilities, Qwen3‑VL has some limitations and practical considerations to keep in mind:
Resource Intensity: The flagship Qwen3‑VL models are extremely large. Running the 235B-parameter model requires multi-GPU setups with high memory (likely multiple A100/H100 GPUs just for inference). Even the smaller variants (e.g. 7B or 32B) will need a good amount of GPU memory to handle image inputs. This means not all developers can self-host the largest model. In many cases, using a cloud inference service or awaiting optimized smaller models is more feasible. The Qwen team has indeed released smaller sizes (down to 2B) by late 2025 to cater to “edge” applications – these smaller models can run on a single GPU or even CPU (with performance trade-offs). Be prepared to quantize the model or use techniques like 8-bit loading if you need to deploy on limited hardware. Memory and compute will also scale with context length: if you actually utilize tens of thousands of tokens of context (e.g. analyzing a huge document), the runtime and memory usage grow linearly, so ensure your infrastructure can handle it.
Latency: Along with size comes inference latency. Processing visual inputs is slower than text alone, due to the image encoding. If you feed multiple images or a video (with dozens of frames), the model has to handle a lot of tokens which can make inference quite slow (possibly many seconds or more per query, depending on hardware and model size). This may not be ideal for real-time applications. You can mitigate this by limiting image resolution (fewer patches) or frames sampled, and by using the smallest model that meets your accuracy needs for a given task. Also consider enabling faster transformer implementations (the Qwen docs mention FlashAttention-2 support for speedups). Ultimately, there’s a trade-off between thoroughness of visual processing and speed.
Image Resolution and Detail Limits: While Qwen3‑VL can handle fairly high resolution images, the fact that images are downsampled to patch tokens means some very fine details might be lost. For example, tiny text or very small objects might not be recognized if the image is scaled down significantly to fit the token budget. If your application relies on fine detail (like reading very small font, or identifying a small defect in an image), you may need to feed a cropped or zoomed-in version of the image to the model, or adjust the max_pixels to allow a higher resolution processing. But increasing resolution increases tokens, which can hit memory limits – so it’s a balance. The DeepStack improvement does help retain more detail than earlier models by using multi-level features, but it’s not magic; extremely subtle image cues might still be missed.
Reliability of Structured Outputs: When asking Qwen3‑VL to produce structured outputs (like JSON, HTML, code), keep in mind it’s learned this behavior but doesn’t have a guarantee of correctness like a traditional parser. The model might occasionally produce slightly malformed JSON (e.g. missing a quote) or make up values if it’s unsure. It might also include extra explanatory text if not prompted tightly to “only output JSON”. Therefore, if you use it for structured data extraction, it’s wise to post-process and validate the outputs. In critical pipelines, you might pair the model with a verifier or do a second pass where the model checks its own output for format correctness. The Qwen ecosystem might release specialized utilities or finetunes for structured output (for example, OmniParser or others), so keep an eye on that if you need high accuracy extraction.
Knowledge Cutoff and Accuracy: Qwen3‑VL, like other LLMs, has a training data cutoff (it knows up to the state of the world from training data, likely 2025 or earlier). It may not recognize extremely new objects or events in images that were not in its training. For instance, a brand new model of car released in late 2025 might confuse it. It also might not always give correct answers for very intricate questions – e.g. medical images or complex scientific charts might be outside its domain of expertise. Always evaluate the model on your specific domain; it might require finetuning on domain-specific data to improve accuracy (the Qwen code release allows fine-tuning on custom data). And as always, double-check critical outputs – the model can hallucinate (make up plausible-sounding info) if asked something ambiguous or if it misreads an image.
Multimodal Alignment and Ambiguities: In some cases, Qwen3‑VL might mistake what part of the image a question refers to, especially if the scene is crowded. For example, if an image has multiple people and you ask “What is the person on the left doing?”, the model should ideally identify the left-most person and describe them. It usually does thanks to spatial awareness, but there can be ambiguity (which left from whose perspective?). If the answer seems off, it could be a misalignment. The model doesn’t have an explicit object detection module; it’s all implicit, so it might not be 100% consistent on references. In UI screenshots, if many elements have similar text, it could mix them up. Careful prompt phrasing or additional clarifications might be needed in such cases.
Security and Privacy: Handling images, especially user-provided ones, has additional considerations. If you use a cloud API, be mindful that images might contain sensitive information (documents, personal photos). Ensure you comply with privacy requirements – perhaps use on-premise deployment for highly sensitive data. There’s also a risk that the model could inadvertently output private information if it was present in the image (like reading someone’s contact info from a form). As a developer, you should sanitize or filter outputs if necessary and inform users that images are being analyzed by an AI. From a security angle, adversarial images (crafted to confuse vision models) could theoretically make Qwen3‑VL output incorrect or harmful content. While Qwen3‑VL will refuse obviously disallowed requests, images are another channel that could be exploited (e.g., an image containing provocative text might trick it). So consider content filtering on both inputs and outputs if you are deploying a public-facing service.
In summary, Qwen3‑VL is a cutting-edge tool but not a plug-and-play solution for every scenario. It requires responsible use and sometimes creative engineering (like combining it with validators or breaking tasks into parts) to get the best results. By understanding its limits – computational, visual, and cognitive – you can design your application to avoid pitfalls, using Qwen3‑VL where it shines and complementing it with other methods where needed. The Qwen project is rapidly evolving, so we can expect improvements and smaller models that will mitigate some of these limitations over time.
FAQs for Developers
What does the name Qwen3‑VL‑235B‑A22B mean?
This naming indicates the model variant. “235B” is the total parameter count (~235 billion). “A22B” refers to the active parameters per token – in this case about 22 billion, meaning it’s a Mixture-of-Experts (MoE) model. Essentially, Qwen3‑VL-235B-A22B uses multiple expert subnetworks and at each inference step only a subset (22B worth) of parameters are used, which makes it more compute-efficient than a fully dense 235B model. For the developer, this detail mainly matters for understanding memory use (it’s still huge) and performance – it’s how Qwen scales up capacity without making runtime completely intractable.
Can I fine-tune Qwen3‑VL on my own dataset?
In principle, yes – the model is open weight and the code for fine-tuning was provided for earlier versions (Qwen2-VL, Qwen2.5-VL), and likely for Qwen3‑VL as well. You would need significant compute resources to fine-tune a model of this size (especially the 235B MoE). Fine-tuning smaller variants (like 7B or 32B) on domain-specific data (e.g. medical images with reports, or specific document layouts) is more feasible and can yield better performance on niche tasks. Techniques like LoRA (Low-Rank Adaptation) could be used to fine-tune efficiently by training only small adapter weights. Always check the license – Qwen3‑VL is Apache-2.0, which is very permissive for commercial use. That means you’re allowed to fine-tune and even deploy commercially without many restrictions, which is a big advantage over some other models that have tighter licenses.
What is the best way to deploy Qwen3‑VL for real applications?
Given the model’s size, a pragmatic approach is to start with hosted APIs (unless you have the infrastructure). Services like OpenRouter or Alibaba Cloud’s ModelScope offer access to Qwen3‑VL via API, which lets you prototype quickly. If you find the latency/throughput acceptable and have usage under control, you could continue using the API for production. If you need on-premises deployment (for data privacy or cost reasons) and the full 235B model is too heavy, consider using one of the smaller Qwen3‑VL models (the team has 32B, 8B, 4B, etc. by now) – you might sacrifice some accuracy, but these are still powerful and much easier to serve. You can also use techniques like model distillation to compress Qwen3‑VL into a faster model. Another tip is to utilize quantization: many Qwen models are available in 8-bit or 4-bit quantized form, which drastically reduces memory at a slight cost to quality. For scaling, the vLLM library or Hugging Face text-generation-inference server can help serve the model with high throughput by optimizing context reuse. Ultimately, the “best” way depends on your use case and constraints – but Qwen3‑VL being open means you have flexibility to run it on anything from a single beefy server to a multi-GPU cluster, or simply outsource the heavy lifting to a cloud service and focus on your application logic.