
Qwen2.5-VL is the latest flagship vision-language model in Alibaba Cloud’s Qwen family, representing a significant leap from the previous Qwen-VL models. It is a multimodal large language model (LMM) that can interpret both images/videos and text, enabling advanced tasks like visual question answering, image captioning, optical character recognition (OCR), and even acting as a visual agent. Qwen2.5-VL comes in multiple model sizes (open-source releases at 3B, 7B, and 72B parameters) and is available in both base and instruction-tuned variants. Notably, the model supports at least 11 languages (including English, Chinese, Japanese, Korean, Arabic, French, German, etc.) for its visual and textual understanding, making it a versatile multilingual assistant. The project is open-sourced under the Apache 2.0 license, with model weights and code accessible on GitHub and Hugging Face. In the sections below, we provide a deep technical overview of Qwen2.5-VL – covering its architecture, training, capabilities, performance, and guidance on usage and deployment – aimed at developers and researchers who want to leverage this state-of-the-art vision-language model.
Qwen2.5-VL Model Architecture
Architecture Overview: Qwen2.5-VL follows a two-module architecture consisting of a vision encoder and a language decoder, fused to enable end-to-end image-to-text generation. The visual encoder is a custom Vision Transformer (ViT) built to handle dynamic image resolutions, while the text decoder is based on the Qwen2.5 LLM, a transformer large language model. The vision encoder processes an input image (or video frames) into a sequence of visual embeddings, which are then fed into the language model to be decoded into text. The fusion is achieved by treating the image embeddings as visual tokens that the decoder can attend to via cross-attention mechanisms, allowing the model to integrate visual context into its text generation. This design is similar in spirit to other multimodal models, but Qwen2.5-VL introduces its own optimizations for efficiency and scalability.
Dynamic Resolution ViT Encoder: A standout feature of the architecture is the dynamic-resolution Vision Transformer trained from scratch for Qwen2.5-VL. Instead of requiring all images to be resized to a fixed resolution, the model can ingest images at various resolutions while controlling the number of visual tokens produced. The ViT uses a base patch size of 14×14 pixels (for Qwen2.5-VL) and can merge patches to effectively adjust the token count. By grouping 2×2 patch regions into one token when needed, each visual token can represent up to a 28×28 pixel region. This approach lets the encoder preserve native image detail for smaller images while avoiding an explosion of tokens for high-resolution images. Developers can specify minimum and maximum pixel counts per image to control this behavior. During training, Qwen2.5-VL’s ViT was exposed to images of varying sizes (and video frames) without forced uniform scaling, enabling the model to “natively” handle different spatial scales.
Windowed Attention: To improve efficiency, Qwen2.5-VL’s ViT employs a Window Attention mechanism. Rather than full global self-attention across all image patches, the ViT restricts attention to local windows (with a max window size of 8×8 patches) to reduce computation. Only a few designated layers (4 layers) use full global attention, while the majority use windowed attention to focus on localized patch regions. Importantly, if an image (or region) is smaller than the window (e.g. <8×8 patches), no padding is added – the model processes it at its native resolution without filler. This design addresses the load imbalance issue when training on diverse image sizes and helps maintain high resolution detail with lower compute cost.
Alignment with LLM Decoder: Another architectural decision was to streamline the vision encoder’s design to be more consistent with transformer language models. The ViT encoder uses RMSNorm normalization and SwiGLU activation in its layers, matching the architecture patterns of the Qwen2.5 text decoder. This harmonization likely eases the integration of vision features into the language model. The text decoder itself is a transformer decoder (similar to GPT-style models) that has been extended to accept visual token inputs. In practice, the integration is implemented via specialized cross-attention layers or by inserting the visual tokens into the model’s input sequence with appropriate positional encoding. The fusion strategy allows the language model to attend to image features and generate text conditioned on them, enabling functionalities like describing an image or answering visual questions. Qwen2.5-VL’s decoder retains the full language capabilities of its text-only counterpart (Qwen2.5 LLM), ensuring that multimodal understanding does not come at the expense of pure language proficiency.
Video Processing: Qwen2.5-VL extends its vision encoder to handle video inputs by introducing an additional temporal dimension to the attention mechanism. It uses dynamic frame rate sampling during training – meaning it trained on videos sampled at varying frame intervals – so it can process videos of different lengths and speeds. The model encodes each video frame as image patches and also embeds a timestamp for each frame using a modified 3D rotary positional encoding (mRoPE) in time. Crucially, Qwen2.5-VL uses absolute time encoding for frames: the position IDs in time are aligned to actual timestamp intervals rather than just sequence order. This helps the model learn the pace of time and even pinpoint specific moments in a long video by their time index. In essence, the architecture can treat a video as a sequence of images with temporal positional cues, allowing it to handle videos up to hours long with temporal reasoning.
Overall, the architecture of Qwen2.5-VL is geared toward high flexibility (dynamic image sizes, long videos, multi-turn interaction) and efficiency (windowed attention, patch merging, optimized norms/activations). By combining a powerful ViT visual encoder with a large language decoder, the model serves as an end-to-end system that “sees” and “talks,” bridging computer vision and natural language in a unified framework.
Tokenization and Context Window
Text Tokenizer: Qwen2.5-VL uses the same tokenizer as the Qwen2.5 text-only LLM, which is designed for multilingual support. It likely employs subword tokenization (such as SentencePiece or BPE) that can handle English letters, Chinese characters, and other Unicode scripts in its 11 supported languages. The vocabulary is built to cover a wide range of languages and symbols, enabling tasks like reading multilingual text from images. For developers, using the tokenizer is straightforward via the provided AutoTokenizer in Hugging Face Transformers. Special tokens and prompt templates are used to structure the input (for example, tokens to denote the start of a system/user message, or to represent an image placement – more on input formatting in a later section). The tokenizer preserves formatting such as LaTeX or code segments in images (for instance, math formulas in an image can be output as LaTeX text), which is crucial for tasks like document analysis.
Multimodal Context Length: One of Qwen2.5-VL’s strengths is its ability to handle extremely long combined contexts of text and visuals. The model was trained with an extended context window, and the open-source releases support up to 131,072 tokens context length in the 72B model (which is a 128k token context). This huge context window means Qwen2.5-VL can take in very long documents (hundreds of pages of text) or long sequences of hundreds of images frames. Even the smaller 7B model has been demonstrated with very long context capabilities (e.g. 32k or 128k tokens if enabled by the model version). In practical terms, the multimodal context includes both text tokens and visual tokens. Each image contributes a number of tokens proportional to its content (up to 16,384 visual tokens per image by default). For example, an image might be internally represented by a few hundred up to several thousand tokens, and the remaining budget is for text. The context limit applies to the sum of all input tokens.
Implications of Long Context: With such a large context window, Qwen2.5-VL can handle tasks like parsing very long documents or multi-page PDFs in one go, analyzing long videos (frame-by-frame), or participating in extended multi-turn conversations with references back to numerous images and prior dialogue. This far exceeds typical context sizes of other open models (for comparison, LLaVA and similar models often have 2k or 4k context limits). The model uses rotated positional encodings (RoPE) to maintain performance even as sequence length grows, and as mentioned, a specialized approach for temporal positions in video. Alibaba Cloud’s documentation notes that certain enhanced versions of Qwen-VL were introduced to expand the context window to 128k and improve long-range understanding. Developers should be mindful of the memory implications: the 72B model with 128k context will require significant GPU memory and computational time for full attention over such long sequences. Fortunately, techniques like FlashAttention are supported (and recommended) to make long-context attention more tractable (this is discussed under Inference).
Tokenizer Behavior for Images: Unlike a standalone vision model, Qwen2.5-VL does not convert images to tokens via a fixed vocabulary. Instead, image patches are directly treated as a sequence of embeddings input to the model (these are the “visual tokens”). The number of visual tokens is determined by image size and the dynamic patch merging strategy (as described in the Architecture section). The AutoProcessor in the Transformers library handles converting an image into these patch embeddings behind the scenes. For reference, by default the model ensures an image yields between 4 and 16,384 visual tokens. A very small image could produce as few as 4 tokens, whereas a very large, detailed image would be capped at 16384 tokens by down-scaling or merging patches. The mapping can be customized: for instance, one can request a higher-resolution processing (more tokens) if a particularly detailed analysis is needed, at the expense of speed. This flexibility is a key aspect of Qwen2.5-VL’s tokenizer behavior – effectively, the model allocates tokens where needed to preserve visual detail, up to the set limits.
In summary, Qwen2.5-VL can ingest an unprecedented amount of multimodal information thanks to its large context window and dynamic tokenization of images. It is designed to fluidly handle mixed sequences of text and images, making it suitable for complex tasks like reading lengthy scanned documents, reasoning across many pieces of visual evidence, or stepping through an hour-long video with accompanying dialogue.
Multimodal Training Data and Methodology
Training Qwen2.5-VL involved an extensive multi-stage process, leveraging massive datasets of image-text pairs and specialized tasks. Alibaba’s Qwen team significantly scaled up both the amount of training data and the training strategy compared to the previous generation. The entire training consumed on the order of trillions of tokens of data, which is among the largest for any vision-language model.
Training Data Composition: The multimodal training data can be categorized into a few broad types:
- Image-Text Pairs (General): A large portion of training data comes from classic image captioning and description datasets. This likely includes datasets like MS COCO Captions, Visual Genome captions, LAION collections, and other web-scraped image-text data. These pairs teach the model to associate images with descriptive text and basic visual understanding. According to one report, the scale of pretraining data was dramatically increased – Qwen2.5-VL saw roughly 4 trillion tokens during training, up from 1.2T in its predecessor. This suggests huge image-text corpora were used.
- Visual Knowledge Data: Qwen2.5-VL was also trained on data that improves its identification of specific entities like famous people, landmarks, products, plants/animals, etc.. This can include labeled images or captions that name what is in the image. By ingesting this, the model builds a broad visual encyclopedic knowledge (the blog mentions it recognizes an “ultra-large number” of categories, from common objects to IP characters and merchandise).
- OCR and Documents: A significant training component was images containing text – e.g. scanned documents, photographs of text (signs, receipts), forms, tables, and so on. For these, the paired text is the transcription or a structured representation of the image. This teaches Qwen2.5-VL robust OCR (optical character recognition) capabilities and the ability to preserve layouts. The model learned not just to read text in images but to output it in structured formats (like markdown, JSON or a custom Qwen-HTML format preserving layout). The inclusion of multi-lingual text in images also means the OCR training data spanned many languages (Chinese, English, etc.), aligning with its multi-language support.
- Video and Temporal Data: Although image frames are the core, training likely included video-based tasks for the model to learn temporal reasoning. For example, frames from instructional videos or movies with descriptions, and specialized video question-answer datasets. The training introduced frame sampling at dynamic FPS (frames per second) – meaning the model saw sequences of frames sampled at different rates. This gives it a sense of how to handle both slow and fast events. Also, tasks like VideoQA (question answering about short videos) or event localization in videos were part of the curriculum.
- Long Context Tasks: In a third stage of training, Qwen2.5-VL underwent long context pre-training. This was a special phase to teach the model to utilize extremely long sequences. The researchers curated tasks where the model had to process very long inputs (such as lengthy multi-page documents or long videos with many frames) and produce some summary or answer. This stage was crucial to expand the model’s context window usage to the 128k range and ensure it remains stable and coherent even when attending over thousands of tokens of history.
Training Stages: The training was broken into three main stages:
- Stage 1 – Vision Encoder Pre-training: A new ViT encoder was trained from scratch using the image-text and visual data described above. This stage was akin to a CLIP-style training: the model learned visual representations aligned with text. It likely used contrastive learning or captioning losses to ensure the image embeddings carry semantic meaning. By the end of this stage, the ViT had strong recognition ability (of objects, text in images, etc.) independently.
- Stage 2 – Joint Training (Vision + Language): The pretrained ViT encoder was then combined with the Qwen language decoder (which may have been initialized from a large language model checkpoint). The combined model was trained end-to-end on multimodal tasks. This included image-conditioned language modeling: the model would take an image and a textual prompt and learn to continue the text. A variety of supervised tasks fall in here: e.g., VQA datasets (where the image+question -> answer), captioning (image -> caption), referring expression comprehension (image+text -> location output), etc. During this joint training, the model learns to fuse visual information into the text generation process effectively.
- Stage 3 – Long Context and Fine-tuning: In the final phase, as mentioned, long context tasks were introduced to push the model’s limits. Additionally, this is where instruction tuning and alignment likely occurred. The open release includes “-Instruct” models, indicating a supervised fine-tuning on instruction-following data. The Qwen team likely curated a large set of multimodal instructions to refine the model’s ability to follow human instructions. It’s possible they used feedback or reinforcement learning from human feedback (RLHF) for alignment as well. Indeed, a later update from the team for the 32B model highlights improved alignment with human preferences, suggesting RLHF or similar alignment was applied to make answers more helpful and harmless.
Throughout training, evaluation and iterative improvements were made on internal benchmarks. The result of this rigorous training pipeline is that Qwen2.5-VL has not only vastly improved raw capabilities but also more aligned, coherent outputs compared to its predecessors. The training methodology focused on scaling up data (4T token dataset), new modalities (video, GUI images), and long-horizon learning. For developers, this means the model comes with a broad knowledge base out-of-the-box, reducing the need for extensive task-specific fine-tuning. Nonetheless, fine-tuning on niche datasets is possible and the Qwen repository provides finetuning code.
Key Capabilities of Qwen2.5-VL
Qwen2.5-VL demonstrates a wide array of capabilities, making it a general-purpose vision-language model. Below are the key capabilities along with what the model can do in each area:
- Image Captioning and Description: Qwen2.5-VL can generate detailed captions for images, describing objects, scenes, and actions. It excels at not just naming common objects but providing rich descriptions. For example, given a complex scene, it can produce a coherent paragraph describing the people, surroundings, and activities. The model’s image understanding covers an “ultra-large” number of categories, including landmarks, animals, fictional characters, merchandise, etc.. This broad knowledge means it can even identify specific famous monuments or species of plants and provide their names in multiple languages. On benchmark captioning tasks like MS COCO, Qwen2.5-VL’s largest version is at state-of-the-art level, with one report noting the 72B model achieved a higher CIDEr score than previous open models (surpassing a BLIP-based baseline by ~5.3 CIDEr).
- Visual Question Answering (VQA): The model can answer questions about images, ranging from simple queries (“What color is the car?”) to complex reasoning (“What might this person be feeling based on the picture?”). It has strong performance on both factual VQA (where the answer is directly present in the image) and reasoning VQA (which may require using external knowledge or logical deduction). For instance, Qwen2.5-VL can count objects in an image, compare attributes, or identify relationships (“Is the cat inside or outside the box?”). On the VQAv2 dataset (a standard benchmark for VQA), Qwen2.5-VL is competitive with other top models in accuracy. The model also demonstrated high scores on more specialized VQA benchmarks like InfoVQA (information-seeking QA on charts/graphics) and DocVQA (question answering on document images), outperforming even some proprietary models in these domains.
- Optical Character Recognition (OCR) and Text Reading: Thanks to dedicated training on text-in-image data, Qwen2.5-VL is very adept at reading text from images. It can transcribe printed or handwritten text from photographs, screenshots, scanned PDFs, etc. Importantly, it supports multi-language OCR – reading English, Chinese, and other supported languages in the image and outputting the text. Beyond raw text, it can extract key information: for example, given an invoice image, it can output the extracted fields (like date, amount, invoice number) in a structured JSON format. Benchmarks like OCRBench (for scene text recognition) show Qwen2.5-VL’s OCR accuracy is very high, exceeding previous Qwen versions. The model also handles mathematical formulas in images (reading LaTeX) and can solve math problems given as images (useful in education scenarios).
- Document Parsing and Layout Understanding: Qwen2.5-VL exhibits specialized skills in parsing documents such as forms, tables, slides, or multi-column articles. It not only reads the text but also understands the layout and structure. The model can output rich formats like a markdown or HTML representation of a document image, preserving headings, tables, and even the positions of elements. This is enabled by training data with labeled layouts and the model’s ability to output special tokens for formatting. In practical terms, this capability means you can feed Qwen2.5-VL an image of a complex form or a magazine page, and it can produce an organized text output (with, for example, table markdown for tables, section titles, etc.). According to the Qwen team, the document parsing ability has reached a “higher level” in Qwen2.5-VL, including outputting in a custom Qwen-HTML format that encodes text positions. This far surpasses basic OCR by giving structured understanding.
- Precise Object Detection and Localization: The model can localize objects within images when prompted – either with bounding boxes or point coordinates. Qwen2.5-VL can output coordinates of an object it identifies, enabling use cases like detecting where in an image a certain item is. For example, you can ask “Locate the cat in the image” and it can return a JSON with the bounding box of the cat. This is a rare capability for a language model and was achieved by training the model to output structured JSON with coordinates and labels. Qwen2.5-VL supports both 2D boxes and even 3D bounding boxes for depth estimation in some cases. The outputs are given as absolute pixel coordinates relative to the image top-left, and the model is consistent in formatting (making it easier to integrate with detection pipelines). Benchmarks like RefCOCO (referring expression localization) show Qwen2.5-VL making a sizable jump in accuracy – one report cites ~73.7% on average RefCOCO tasks for Qwen2.5-VL vs earlier models in the mid-50s. Essentially, it has learned to draw boxes in text form by learning the syntax and semantics of coordinates.
- Visual Reasoning and Tool Use: Qwen2.5-VL isn’t limited to direct Q&A – it can perform reasoning on visual inputs. It can do things like count the number of objects, compare two images, or infer causality (“What might happen next in this image?”). Moreover, the model was designed to be “agentic”, meaning it can use tools or take actions based on visual input. For instance, Qwen2.5-VL has been demonstrated as a visual agent that can control a computer interface or a smartphone UI by “seeing” screenshots. In internal benchmarks, it achieved high success rates on tasks like controlling an Android phone and a PC via screen images (ScreenSpot and AndroidWorld tests). This is achieved by the model outputting action commands (like click coordinates or keyboard inputs) after analyzing the screenshot. Essentially, it can act like an autonomous agent that uses vision to decide what to do – a cutting-edge capability bridging into robotics and automation. While this is a research area, it shows the model’s capacity for multi-step reasoning with images.
- Long Video Understanding: Unique among open models, Qwen2.5-VL can handle long videos (tens of minutes to hours) by processing frames sequentially and answering questions or summarizing. It can generate a summary of a video’s key events or find the timestamp where a specific event occurs. For example, given a 1-hour surveillance video and a query “When does the delivery person arrive?”, the model can analyze frames (with time encoding) and output an approximate timestamp of that event. This leverages the model’s temporal encoding and long context capability. On benchmarks like VideoQA or VideoMCC, Qwen2.5-VL showed improved performance over the previous gen (e.g., MVBench score improved from 67.0 to 69.6 for 7B model). It also introduced a new ability: event segmentation – it can break a video narrative into segments with descriptors, which is useful for video indexing.
- Code Generation from Visual Inputs: An interesting capability noted in documentation is “visual coding”. Qwen2.5-VL can generate code (such as HTML/CSS or UI code) from an image input. For instance, show it a screenshot of a web design, and it might output the HTML/CSS code to replicate that design. This was likely enabled by training on pairs of design images and code, as well as by the model’s general coding abilities inherited from the Qwen LLM. This use case is experimental but promising for automating front-end development from mockups. Similarly, it can generate text based on images for data science. An example from Qwen’s cookbook is “MultiModal Coding” where the model generates accurate code after rigorous comprehension of an input image (perhaps a diagram or specification).
In essence, Qwen2.5-VL is not just an image captioner or a VQA system – it is a generalist multimodal AI. It can see, read, reason, and act. From describing photographs with human-level detail, extracting structured data from scans, to controlling devices via vision, its capabilities span a remarkable breadth. This makes it suitable for a wide range of applications, as we’ll explore in the Use Cases section. Notably, even the smaller Qwen2.5-VL models carry many of these capabilities: the 7B model outperforms other models of similar size (like GPT-4o-mini) on many tasks, and the tiny 3B model already beats the older 7B Qwen-VL on several benchmarks. Of course, the larger models (32B, 72B) push the envelope further, matching or exceeding systems like GPT-4 vision on certain benchmarks.
Performance Benchmarks
How does Qwen2.5-VL actually perform in numbers? The model has been evaluated on a broad set of benchmarks covering vision, language, and multimodal reasoning. Overall, Qwen2.5-VL achieves state-of-the-art or near state-of-the-art results among open models, and even rivals some proprietary models in specific domains.
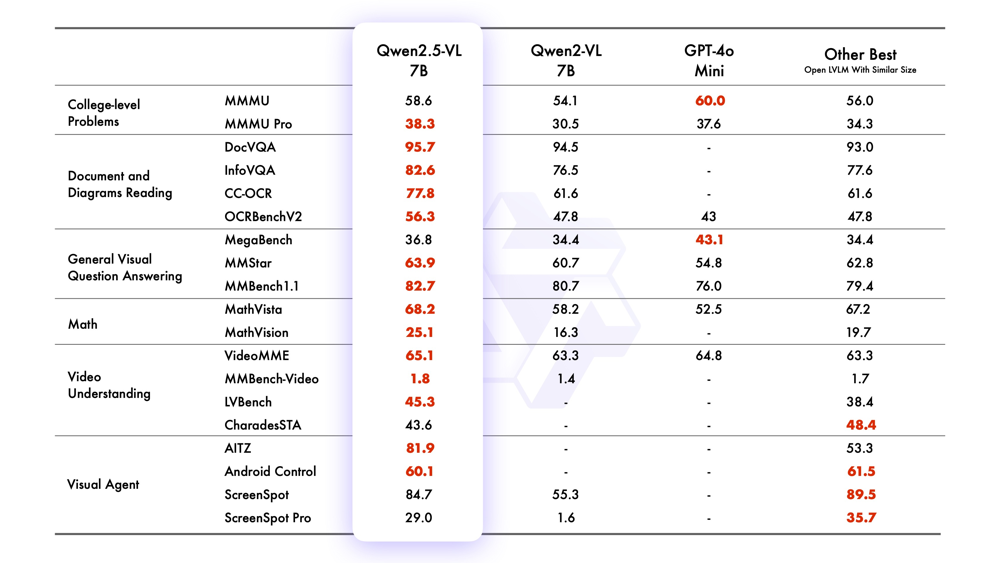
In the above summary table (for 7B models), we see Qwen2.5-VL’s gains. To highlight a few results from both the 7B and the flagship 72B model:
- Document Understanding: On DocVQA (document visual QA), Qwen2.5-VL-7B achieves 95.7 (accuracy) vs. 94.5 by Qwen2-VL-7B. The 72B instruct model reaches 96.4, which is on par with the best open model and even with closed models like Claude 3.5 (95.2). For InfoVQA (which involves infographics and information extraction from images), the 7B scored 82.6, a sizeable jump from 76.5 prior. These indicate superior ability to handle documents, diagrams, and charts.
- OCR and Text QA: On TextVQA (answering questions where reading text in the image is needed), Qwen2.5-VL-7B scores 84.9%, slightly edging the older model. On a general OCR benchmark (OCRBenchV2), the 7B model scored 56.3 (likely an F1 or word accuracy), again higher than the 47.8 of the older model. The “CC-OCR” entry (possibly an internal evaluation combining Creative Commons OCR tasks) also shows improvement: 77.8 vs 61.6 for older 7B. These reflect the improved text recognition in complex scenes.
- General VQA and Reasoning: Qwen2.5-VL-7B outperformed GPT-4o-mini (an open mimic of GPT-4’s vision) on many VQA-like benchmarks. For instance, on a broad MMBench 1.1 (multimodal benchmark) it scored 82.7 vs GPT-4o-mini’s 76.0. On a math-in-image task (MathVista), the 7B hit 68.2, significantly above 58.2 of the older model and even beating GPT-4o-mini’s 52.5, showing strength in visual mathematical reasoning. The only area the smaller Qwen lagged GPT-4o-mini was perhaps some pure image reasoning benchmarks like a “MegaBench” (36.8 vs 43.1) – but those gaps diminish at larger model scales.
- Video Understanding: The 7B Qwen2.5-VL improved on Qwen2-VL in video tasks: e.g., VideoMME (a video multimodal exam) from 63.3 to 65.1, and a Video-MME with subtitles from 69.0 to 71.6. While these increments may seem small, they indicate progress in long video comprehension. The 72B model, as shown in the 72B table, reaches even higher on video metrics (e.g., 73.3 on VideoMME). Notably, LongVideoBench (a test for very long videos) shows the 72B can handle it (score ~54.7) whereas smaller models might not even attempt it.
- Visual Agent / Control: On agentic benchmarks that measure a model’s ability to read UIs and issue control commands, Qwen2.5-VL-7B achieves high scores: e.g., 84.7 on ScreenSpot (locating elements on screen) and 81.9 on AITC (a test for following instructions on UI). These were tasks not feasible for many models. The 72B presumably does even better (the table for 72B shows ScreenSpot 87.1 and even some 3D understanding test scores). For comparison, the older Qwen2-VL didn’t have these capabilities trained, so these represent new benchmark entries for Qwen2.5.
- Comparison to Proprietary Models: According to the Qwen team, the flagship Qwen2.5-VL-72B model is comparable to top proprietary models like GPT-4 (vision) and Anthropic’s Claude 3.5 on many tasks. In particular, they call out that Qwen2.5-VL-72B excels in document and diagram understanding on par with those models. Some numbers bear this out: for example, on DocVQA test, GPT-4o (an approximation of GPT-4 vision) scored ~91.1 whereas Qwen2.5-VL-72B scored 96.4. On a chart QA, Qwen2.5-VL-72B scored ~87, above GPT-4o’s ~74. These suggest Qwen’s specialized training gave it an edge in those structured visual tasks. However, for general tasks like common object recognition or open-ended reasoning, GPT-4 is still superior in many cases (as expected given its scale and training). Still, Qwen2.5-VL significantly closes the gap and even outperforms GPT-4o (open clone) on numerous open benchmarks.
- Smaller Models vs. Competition: Qwen2.5-VL-7B often outperforms other open-source multimodal models of similar size. For instance, comparisons with InternLM-VL or LLaVA-1.5 in research literature show Qwen2.5-VL ahead on tasks like COCO Captioning and VQAv2. One report on COCO Captioning for 7B models indicated Qwen2.5-VL had a higher CIDEr by several points over LLaVA-1.5-7B. On VQAv2, Qwen2.5-VL-7B’s accuracy was reported to be higher than some 12B models (like a Gemma-3 12B) according to community tests. This highlights the efficiency of Qwen’s training – it’s punching above its weight class. Even the Qwen2.5-VL-3B (intended for edge devices) surpassed the older 7B model’s performance in many benchmarks, making it possibly the best <5B multimodal model currently.
In summary, the benchmark results corroborate that Qwen2.5-VL is state-of-the-art among open multimodal models across a spectrum of tasks. From academic benchmarks (VQA, captioning, chart QA) to practical ones (OCR, document QA, UI navigation), it has set new highs for open models. Developers can be confident that Qwen2.5-VL will deliver strong performance out-of-the-box, and potentially approach the quality of much larger closed models in certain niches. Of course, for absolute cutting-edge results, the 72B model is needed – it’s the one that matches GPT-4V in some evaluations – but the smaller sizes provide excellent trade-offs for local deployment as evidenced by these metrics.
Inference and Input Formatting
Using Qwen2.5-VL in practice involves preparing the inputs (images and text prompts) in the format the model expects, and potentially adjusting some settings for optimal performance. Alibaba has provided an easy-to-use interface via the QwenAutoProcessor and the model’s generation API to simplify this.
Input Formatting (Chat Format): Qwen2.5-VL is designed to operate in a chat paradigm similar to ChatGPT. This means the input is structured as a conversation with roles (system, user, assistant) and can intermix text and images. The standard input format is a list of message dictionaries. For example, a single-turn prompt with an image would be represented as:
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "<image_path_or_url>"},
{"type": "text", "text": "Describe this image in detail."}
]
}
]
Each message can contain multiple content parts, where type can be "text", "image", or "video" and the model will interpret them in sequence. This flexible schema allows complex interactions, e.g., a user message could have several images followed by a question that asks to compare them. The AutoProcessor will convert this high-level structure into the actual model inputs: it will tokenize the text, insert special tokens for roles (like <|user|>, <|assistant|> tags in the prompt), and convert each image into patch embeddings with the appropriate positional placeholders.
Multimodal Context Assembly: Under the hood, each image is represented by a sequence of visual tokens. The processor takes raw images (from file path, URL, or base64) and applies the necessary transformations (resize if needed, normalization) before passing them through the vision encoder part to get embeddings. These embeddings are then concatenated in the sequence where the image was placed. The text around images is tokenized by the Qwen tokenizer as usual. The processor ensures that special sentinel tokens or delimiters are used so the model knows where an image’s tokens begin and end (typically a special token like <image> might be used as a placeholder in the text sequence, though implementation details are abstracted away).
Batch Inference: Qwen2.5-VL supports batch inference, meaning you can send a list of such message prompts to the model simultaneously for faster throughput. The processor will collate multiple prompts and pad them appropriately. As shown in examples, one can prepare messages1, messages2, ... and then do something like:
texts = [processor.apply_chat_template(m, tokenize=False, add_generation_prompt=True) for m in [messages1, messages2]]
image_inputs, video_inputs = process_vision_info([messages1, messages2])
inputs = processor(text=texts, images=image_inputs, videos=video_inputs, padding=True, return_tensors="pt")
outputs = model.generate(**inputs)
This will generate outputs for each prompt in the batch. The ability to batch process is useful in production settings where you might want to handle multiple queries in parallel on a GPU for efficiency.
Image Resolution and Token Settings: By default, Qwen2.5-VL’s preprocessing will use the image’s native resolution (up to certain limits) to determine patch tokens. However, developers can tweak this for a trade-off between performance and accuracy. The AutoProcessor accepts parameters min_pixels and max_pixels which define the minimum and maximum number of pixels (in terms of 28×28 patches) that each image should be resized to correspond to. For instance, setting max_pixels lower will force the image to be downscaled more (fewer tokens, faster inference), whereas increasing it allows processing higher detail (more tokens, better accuracy). The default range is 4 to 16k tokens per image as noted. You can also directly specify resized_height and resized_width for an image if you want exact control (the library will internally round it to multiples of 28 to align with patch merging). In summary, Qwen2.5-VL gives fine-grained control: you might choose a high resolution setting for a detailed document image to maximize OCR accuracy, but a lower one for a quick simple captioning task to save compute.
Flash Attention and Speed-ups: When running inference, especially with long contexts or multiple images, using memory-efficient attention is key. Qwen2.5-VL supports FlashAttention-2, which can significantly speed up attention operations (2-4× faster) and reduce memory usage on GPU. It is recommended to enable this in the model loading. For example, in Transformers you can load the model as:
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="auto"
)
as suggested in the documentation. Using bfloat16 or float16 is also advised for faster computation on GPUs. The Qwen models will automatically dispatch layers to multiple GPUs if device_map="auto" is used, which is helpful for the large 72B model (which won’t fit on a single GPU).
Generation Parameters: Once the inputs are prepared and passed to model.generate, standard text generation parameters apply. You can set max_new_tokens to limit response length, and use decoding strategies like greedy, beam search, or sampling as needed. The instruction-tuned models will generally produce well-formed answers in a conversational style. They also have been aligned to follow instructions not to produce disallowed content or overly verbose responses. If you prompt the base (pre-instruct) model, you may need to prepend a system message or few-shot examples to get the desired style.
Output Post-processing: The raw output from model.generate will be token IDs that include the assistant’s reply (possibly including some end-of-sequence token). The AutoProcessor provides a batch_decode to turn these into strings, and in examples they set skip_special_tokens=True to remove special tokens. If the model was asked to produce structured output (like JSON), the developer should verify the format – Qwen2.5-VL is quite good at maintaining JSON syntax for things like coordinates, but minor format issues can occasionally occur if the response is very long.
Multimodal Considerations: When asking the model to output things like bounding boxes or to use tools, these are usually triggered by specific prompt patterns. For example, to get a box, you might prompt: “Provide the coordinates of the cat in the image in JSON format.” The model will then comply and produce JSON if it knows to. The instruction tuning has likely trained it on such patterns. It’s also possible to get the model’s chain-of-thought or rationale (some “Thinking” variants of Qwen-VL exist that output reasoning), but the instruct model by default will hide the reasoning unless asked explicitly.
In summary, performing inference with Qwen2.5-VL involves structuring your prompts as a conversation with embedded images, using the provided processor to handle the heavy lifting of tokenization, and leveraging the model’s optimizations (like FlashAttention) for speed. The design is developer-friendly: you can treat it almost like a chat API that happens to accept images. Whether you input one image or a sequence of 100 images (as frames or multiple inputs), Qwen2.5-VL will handle it so long as it fits in context and will respond in the same chat paradigm.
Example: Here’s a simple end-to-end example (assuming appropriate libraries and model weights are installed):
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct", device_map="auto"
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct")
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "https://example.com/image_of_chart.png"},
{"type": "text", "text": "What does this chart tell us?"}
]
}
]
# Prepare inputs
inputs = processor(messages, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=200)
answer = processor.batch_decode(outputs, skip_special_tokens=True)[0]
print(answer)
The answer would contain a detailed explanation of the chart image. This snippet demonstrates the typical workflow: define the conversation with roles, use the processor to get tensors, and generate using the model. The high-level API hides all the complexity of patch embeddings and token insertion.
Deployment and Scaling
Deploying Qwen2.5-VL in a production environment requires consideration of model size, serving infrastructure, and possibly cost (if using cloud APIs). There are multiple ways to deploy the model: using Alibaba Cloud’s services, open-source frameworks, or custom setups on your hardware.
Alibaba Cloud Model Studio: Alibaba offers Qwen-VL models as a service through their Model Studio and cloud API. The commercial endpoint is updated with the latest features and allows easy scalability. For instance, Qwen3-VL and Qwen2.5-VL are available with context caching and tiered pricing by token usage. If using Alibaba Cloud, one can simply call the API with the image and prompt and get a response, without worrying about infrastructure. The cloud models also support extremely large contexts (128k) in the hosted version, which might be challenging to self-host. However, costs can accrue per million tokens processed, so optimizing prompts and context length is important.
Local Deployment (Open-Source): The open-source Qwen2.5-VL models can be run locally. For the 7B and 3B models, a single modern GPU (like an NVIDIA 3090 or A100) is sufficient (7B typically requires ~14GB VRAM in 16-bit, which can be halved with 8-bit quantization). In fact, the 3B model can even run on CPU for light workloads – Roboflow reports that Qwen2.5-VL 3B/7B can be deployed on devices like Raspberry Pi or NVIDIA Jetson (edge GPUs) for IoT use-cases. The 72B model, on the other hand, is much heavier: it will require at least 4× A100 80GB GPUs (or more) to serve in full precision. For 72B, using multi-GPU with device_map in Transformers or using model parallel frameworks (like DeepSpeed or ColossalAI) is necessary. Alibaba did release AWQ-quantized versions of Qwen2.5-VL 72B (and other sizes) which make use of optimized 4-bit weights for faster inference. These quantized models can achieve up to 3.5× speed-ups, as noted in a collaboration with RedHat for inference optimization, and they reduce VRAM needs. For most developers, the 7B model strikes a good balance and can be run on a typical gaming GPU with 16 GB memory, or even 8 GB with quantization.
Frameworks and Libraries: Qwen2.5-VL is fully integrated into Hugging Face Transformers (as of v4.33+ or later). This means you can use the standard APIs, or even the high-level pipeline. However, for multimodal pipeline, you might need the specialized transformers.AutoModelForImageTextToText. The Qwen team also provides the qwen-vl-utils package which contains the process_vision_info helper and other utilities to simplify video handling. It’s recommended to install that package, as it deals with things like reading videos (using PyTorch’s torchvision or Decord) and formatting the prompts properly. For deployment, you might also consider the vLLM library which is optimized for LLM serving with continuous batching – indeed, there is a vLLM recipe for Qwen2.5-VL. Using such libraries can dramatically improve throughput by batching multiple requests and using efficient KV caching (important for long contexts).
Hardware Requirements: As mentioned, the hardware needed depends on model size:
- 3B model: Can run on CPU (with slow speed) or on small GPUs (4GB+). Good for embedded scenarios.
- 7B model: Requires ~12–16GB GPU memory (FP16). Consumer GPUs can handle this. For faster responses, use a high clock speed GPU or multiple for concurrency.
- 32B model: (if using, was released later) Likely needs ~40GB VRAM, so at least one A100 40GB or two smaller GPUs.
- 72B model: Needs at least 4 × 24GB GPUs with sharding, or dual 80GB GPUs with 8-bit compression. This is enterprise-grade deployment only.
For all, ensure you have a recent GPU with CUDA support. Qwen models also benefit from FlashAttention2, so using GPUs that support it (like A100, H100, etc., or any with CUDA sm75+) is beneficial. CPU deployment is only practical for the smallest model or non-real-time batch jobs.
Scaling and Throughput: If high throughput is needed, consider the following:
- Use the batching capability: Group incoming requests into batches of, say, 4 or 8, to fully utilize GPU parallelism.
- Enable KV cache in generation if doing multi-turn conversations, so that the model does not recompute attention for the entire history each time (Transformers handles this if you pass
past_key_values). - Use quantization: The AWQ 4-bit models or NVIDIA’s TensorRT INT8 optimization can double or triple throughput with some quality loss.
- Deploy multiple model instances: For example, have one GPU serve two 7B models for handling more requests concurrently, if latency per request is more critical than single-model accuracy.
- Leverage ModelScope or Alibaba Cloud for auto-scaling: If you use the cloud service, it can scale behind the scenes to handle variable load, albeit with cost trade-offs.
Integration and APIs: Many developers will integrate Qwen2.5-VL into applications via an API. If self-hosting, you might wrap the model in a REST API (using FastAPI or Flask) or use a solution like Hugging Face Text Generation Inference (which now has some support for multi-modal models). The format of request/response would typically be JSON: you send image files or base64 and the prompt, and get back the model’s answer (and possibly the coordinates or structured data if that’s what was asked). Alibaba’s documentation provides example code for calling their API, including setting the fps parameter for video (to indicate the frame rate used). If deploying in Model Studio, you simply select the model (like qwen-vl-max or qwen2.5-vl-7b-instruct) and use their SDK or HTTP endpoints.
Monitoring and Logging: With such a large context window, it’s easy to accidentally send extremely large inputs which could slow down inference. It’s good to implement checks on input size. Monitoring GPU memory and latency will help optimize prompts. Also, log the model’s outputs and any truncation that occurs to continuously ensure quality.
Security and Filters: Qwen2.5-VL has gone through alignment, so it should refuse or safely handle disallowed requests (especially the instruct version). However, if deploying publicly, one should still have content filters as backup. Also, be mindful that if the model is asked to read sensitive images (like IDs or documents), those should be handled securely (the model itself doesn’t store data beyond the session, but logs or misuse could expose info).
In summary, Qwen2.5-VL can be deployed from cloud to edge. Its smaller variants enable on-premises deployment for privacy, while the larger variant might be consumed via cloud for its superior accuracy. The availability of quantized models and the integration with popular AI frameworks make it relatively straightforward to get started. Early users have already run Qwen2.5-VL 7B on consumer hardware and found it “vision AI made easy” to use. With proper configuration, you can scale Qwen2.5-VL to meet real-world application demands.
Use Cases in Production
Qwen2.5-VL’s rich skill set opens up many practical use cases across different industries. Here we outline some prominent ones and how the model can be applied:
- Education and E-learning: Qwen2.5-VL can serve as a visual tutor. It can solve math problems shown in images (from arithmetic in a worksheet to complex calculus problems in a textbook scan). Students can take a photo of a problem, and the model can not only give the answer but also explain the solution steps. It can also be used to identify objects or animals from pictures for educational apps (“what is this plant?”) given its broad recognition ability. Language learning apps might use it to describe images in the target language or have conversations about a picture (practicing vocabulary). The model’s multi-lingual support is valuable in global e-learning platforms.
- Accessibility for the Visually Impaired: With its strong image description and OCR, Qwen2.5-VL can be the engine in accessibility tools. For example, a smartphone app could use the model to describe a user’s surroundings or read out text from signs, labels, or documents in real-time. This is similar to seeing-AI applications. Qwen2.5-VL can look at a restaurant menu (photo) and read it aloud, or tell a user what is in a photograph they took. Its ability to handle multiple languages means it can translate signs or documents on the fly (take a picture of a German sign and ask for English translation). The detailed descriptions (including reading emotions or scene details) can greatly enrich the experience for visually impaired users.
- Document Processing and Enterprise Automation: Businesses deal with loads of documents: invoices, receipts, forms, contracts. Qwen2.5-VL can automate document understanding by extracting structured data. For instance, scanning an invoice image and feeding it to Qwen2.5-VL could yield JSON output of invoice number, date, items, prices. In financial services, it could parse bank statements or ID documents for KYC. The model’s support for tables and forms means it could integrate with RPA (Robotic Process Automation) systems to handle paperwork. Additionally, Qwen’s high accuracy in multi-language OCR is useful for global companies dealing with international documents.
- Customer Support (Visual): Many customer support queries involve images: a customer might send a photo of a defective product, an error screen, or a bill they received. Qwen2.5-VL can assist support agents or chatbots by analyzing these images. For example, it can read the error message on a screenshot and either automatically suggest solutions or summarize the issue for a human agent. In e-commerce, a customer could send a picture of an item they want a refund for; the model can check if the item matches the order (visually) and identify any damage. Its visual QA ability allows a more interactive support – users can ask “I bought this gadget, here’s a photo, how do I reset it?” and the bot can identify the model and provide instructions. Alibaba likely uses such technology in their e-commerce platform.
- Content Creation and Social Media: Qwen2.5-VL can help content creators by generating captions or alt-text for images automatically. A social app could use it to suggest descriptions for photos a user uploads (improving accessibility and SEO). It can also act as a creativity tool: e.g., “Write a story about this image” or meme generation by understanding an image and suggesting witty text. Marketers could use it to analyze an advertisement image and output key themes or even generate product descriptions from product photos.
- Navigation and Mobile Agents: The model’s agentic capabilities mean it can interpret screenshots and guide UI interactions. In production, this could translate to virtual assistants that can operate other apps. For instance, a voice assistant could take a screenshot of your phone settings and figure out how to toggle a feature by “looking” at the screenshot and instructing actions (this leverages the ScreenSpot skills). Although this is cutting-edge, it hints at automating tech support on devices – the assistant could visually walk a user through performing a task by highlighting where to tap, etc., all driven by the model’s understanding of the UI images.
- Medical Imaging (with caution): With fine-tuning, Qwen2.5-VL might be used in medical or scientific domains. Out-of-the-box, it isn’t a medical expert, but it can describe images like an x-ray or microscope slide in general terms. For example, it could identify “there is a large white area in the lung X-ray” but it won’t diagnose (unless specifically trained). However, for medical education, it could be used to label anatomical structures in an image or pair with a doctor to draft reports. Because it maintains the language prowess of Qwen LLM, it can turn visual observations into well-written text (aiding in radiology report drafting, for instance).
- Surveillance and Security: The long video understanding capability means Qwen2.5-VL could be applied to analyze security camera footage. It could generate summaries of what happened overnight on various cameras. It could also answer queries like “Did anyone wearing a red shirt appear today in camera 3?” — the model can scan hours of video frames to find that event. For critical applications, its outputs would likely be used as assistance for human operators rather than fully automated, due to possible errors. But it can drastically reduce the manual effort of reviewing footage.
- Geospatial and Navigation: Another area is analyzing map or satellite images. Qwen2.5-VL could describe a satellite photo, identifying things like roads, water bodies, buildings. For navigation, it could potentially read street signs from street view images or help an autonomous agent by interpreting visual cues (stop signs, obstacles). Combined with its long context, one could imagine feeding a series of street images from a dashcam and the model narrating the drive or alerting to relevant signs.
- Visual Programming Aids: As mentioned, Qwen2.5-VL can generate code from images (like a design to HTML converter). This could be productized into a plugin for design software: a user draws a wireframe, the model outputs the corresponding front-end code. It could also document code by analyzing UI screenshots and linking them to code components (helpful in large UI codebases to find which part of an image corresponds to which code).
It’s important to note that for some of these use cases, domain-specific fine-tuning or prompt engineering may be required to get optimal results. For example, in customer support, one might fine-tune Qwen2.5-VL on past chat + image transcripts from the company. In document parsing for a specific form type, fine-tuning on a handful of labeled examples can push accuracy to near 100%. The Qwen open-source release encourages such adaptations and even provides a finetuning cookbook for various tasks.
Overall, Qwen2.5-VL’s deployment scenarios are expansive. Its ability to seamlessly blend vision and language makes it a powerful component in any AI system that needs to interact with the real world’s visual data. From helping individuals (assistive tech, education) to powering enterprise workflows (automation, analytics) to cutting-edge AI agents (autonomous tool use), Qwen2.5-VL is a versatile foundation model that developers can build upon.
Limitations and Future Outlook
While Qwen2.5-VL is highly capable, it is not without limitations. Understanding these limitations is crucial for deploying the model responsibly and for identifying areas of improvement for future versions.
Known Limitations:
- Visual Errors and Hallucinations: The model can sometimes misidentify objects or hallucinate details that aren’t present. For instance, if an image is very ambiguous or low-quality, Qwen2.5-VL might give a plausible-sounding description that is incorrect. It might label a random person in an image as a famous look-alike (due to its training on celebrity data), or assume text in an image based on context even if illegible. Although it was trained to be accurate, the sheer scope of possible images means mistakes happen. It may also hallucinate in structured outputs occasionally – e.g., outputting a JSON with an extra field that wasn’t asked for, or guessing at table data that isn’t actually present clearly. Rigorous prompt constraints and post-processing validations (like checking if the coordinates it outputs actually correspond to something in the image) can mitigate this.
- Prompt Sensitivity: Qwen2.5-VL’s outputs can be sensitive to how the prompt is phrased. Different wording in the user instruction might lead to differences in detail or format of the answer. Sometimes, getting the best result (especially for structured tasks like extracting info or giving a step-by-step answer) requires careful prompt engineering or few-shot exemplars. Less experienced users might find that the model gives a very brief answer to a broad question like “Describe this image,” whereas a more specific prompt yields a richer answer. This is common to LLMs; documentation of good prompt patterns (which the Qwen team provides for some scenarios) will help users get optimal results.
- Slow with Very Long Inputs: Even though Qwen2.5-VL can handle extremely long inputs, processing those is time-consuming. If you give it a 100-page document to summarize, it will take significantly longer (possibly many seconds or more) and a lot of memory. The model uses efficient attention, but fundamentally O(n) generation time cannot be escaped. So in practical use, one might still chunk very long inputs or use retrieval-augmented techniques rather than always slam the full 128k tokens at it. Similarly, analyzing a 1-hour video frame-by-frame is heavy – in critical applications it may be better to do some pre-selection of frames (though the model itself can help by its event localization ability).
- Multimodal Fusion Limits: There might be cases where the model struggles to deeply fuse information from multiple images. For example, comparing two very detailed infographics in a single go might confuse it, whereas doing them one by one is fine. The model’s attention is powerful, but if many images are given, it may not fully attend to all if it hits some internal limit or if the prompt doesn’t explicitly guide it. The documentation suggests a max of 4 images minimum and up to 512 images can be given (the latter likely in video frame context). But in practice, giving hundreds of images can dilute focus.
- Emergent Risks: As with any large model, there are potential misuse risks. Qwen2.5-VL could be prompted to describe sensitive images (like personal photos), which raises privacy concerns. It might be used to attempt face recognition – while it can name some celebrities, it should not be used for identifying unknown individuals (it will likely fail or err). Also, OCR capability means it can read things like ID cards or credit card numbers from images; such use must comply with privacy laws and the model’s output should be protected. The model’s alignment tries to avoid disallowed content, but users could still attempt to feed graphic or harmful images. Qwen2.5-VL will usually refuse to describe extremely violent or explicit images (if aligned correctly), but it’s something to monitor.
- Linguistic Limitations: The model supports 11 languages in vision, which is great, but outside those it may not read text well. For example, if an image has Hindi text (which might be unsupported according to the doc), it may fail to OCR accurately. Even within supported languages, complex scripts or artistic fonts might reduce accuracy. Also, when generating responses, it might favor English by default in some cases, so developers should explicitly prompt in the desired language.
Future Enhancements:
The Qwen team has indicated that future work (Qwen 3 and beyond) will aim to make the model even more general and powerful. They envision an “omni-modal” model that goes beyond vision and text – meaning adding audio/speech, and possibly real-time video capabilities. In fact, Alibaba has released Qwen-3-Omni which adds audio and speech generation. We can expect that future Qwen-VL versions (Qwen3-VL) will bring:
- Real-time video analysis: Handling streaming video input rather than discrete frames, and outputting answers continuously.
- Improved Reasoning: Every new model version tends to improve the chain-of-thought and reasoning. Qwen2.5-VL already made progress here, but future models might integrate advanced planning or external tool use.
- Efficiency Optimizations: Perhaps distilling the model down to smaller sizes with minimal loss, for edge deployment. A 3B model is already small, but maybe an even smaller (<=1B) multimodal model could be viable for mobile devices.
- Better Alignment: Continuous refinement using human feedback, especially in understanding what not to say about images (for example, avoiding biases or inappropriate comments about a person’s appearance). Aligning multimodal models is hard, and we’ll likely see improvements where the model is more nuanced in responses.
The Qwen team’s blog also mentions incorporating more modalities and making the model smarter at problem-solving as the next steps. This could mean combining vision with voice (so a user could send an image and speak a question), or adding the ability to output audio for an all-in-one assistant. They are effectively moving towards an AI that can see, hear, speak, and act – an integrated agent.
For developers, the path forward includes possibly fine-tuning Qwen2.5-VL on domain-specific data to overcome some limitations. Since it’s open, the community can contribute improvements or adaptations (for example, someone might fine-tune it on medical images and share a Qwen2.5-VL-Med model). The robust open-source ecosystem means Qwen2.5-VL will continue to get better via community training and feedback, even as Alibaba works on the next big version.
Conclusion: Qwen2.5-VL stands out as one of the most advanced open multimodal models of its time (late 2025). It brings together cutting-edge research in vision transformers, large language models, and multi-turn alignment. By understanding its architecture, capabilities, and proper usage, developers can harness Qwen2.5-VL to build applications that were previously in the realm of science fiction – from AI tutors that see and talk, to automated agents operating computers through vision. As we address its current limitations and anticipate future enhancements, Qwen2.5-VL represents a significant step toward truly general-purpose AI systems that seamlessly blend vision and language understanding.