
Qwen2.5-VL is the latest vision-and-language large model from Alibaba Cloud’s Qwen series, designed to understand images (and even videos) and generate text responses. It is an open-source model (Apache 2.0 license) available in 3 sizes – approximately 3B, 7B, and 72B parameters – to suit use cases from edge devices to high-performance servers. Built on the improved Qwen2.5 language model backbone, Qwen2.5-VL has been instruction-tuned for multimodal inputs, meaning it can follow natural language prompts that include images and text.
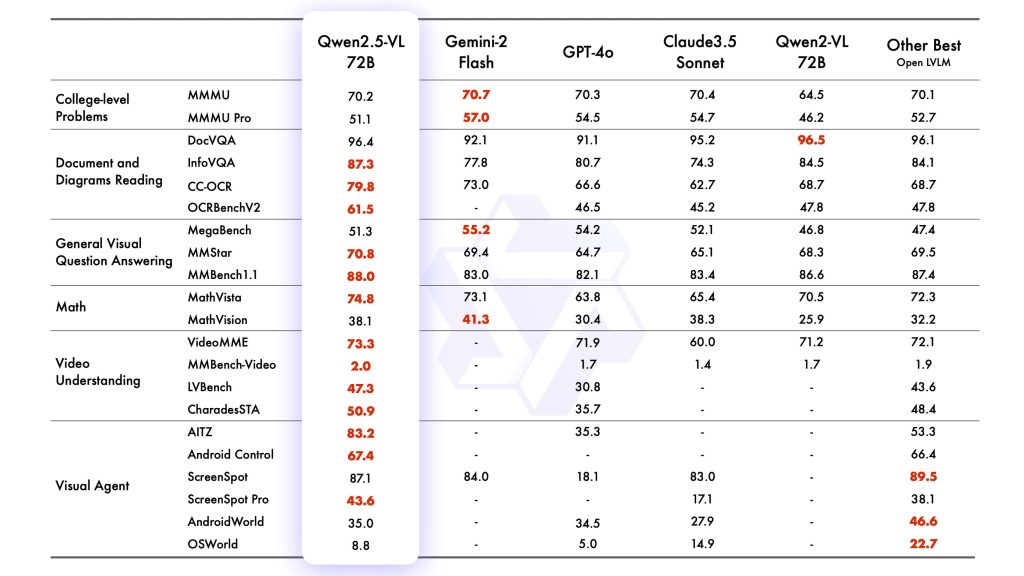
This model represents a major leap in multimodal capabilities: it offers enhanced visual recognition, precise object localization, robust document parsing, and even long-video comprehension beyond what its predecessor (Qwen-VL 2.0) could do. In practical terms, Qwen2.5-VL excels at tasks like image captioning, visual question answering (VQA), optical character recognition (OCR), table and chart data extraction, and complex reasoning over visuals. The flagship 72B model delivers state-of-the-art performance in these domains – notably outperforming previous open models on document understanding and diagram analysis – all while preserving strong natural language abilities for coherent and context-aware responses.
Unlike a simple image classifier or OCR engine, Qwen2.5-VL is a general-purpose multimodal AI. It can describe what it sees in detail, answer questions about an image, extract structured information (e.g. pulling fields from a form or numbers from a graph), and even act as an agent by interpreting a UI screenshot and deciding on actions. The model has been trained on an extremely large multimodal dataset (4.1 trillion tokens of text along with corresponding images/video), giving it a broad base of knowledge.
It recognizes an “ultra-large” number of visual categories – not just common objects like dogs or cars, but also fine-grained items (plants, bird species, etc.), famous landmarks, logos, products, and more. Additionally, it can read and understand text within images in multiple languages (English, Chinese, Arabic, and beyond) and handle varied layouts and orientations. In summary, Qwen2.5-VL is a powerful foundation for building multimodal applications, combining a top-tier language model with advanced visual understanding capabilities.
In this guide, we’ll explore Qwen2.5-VL’s architecture and features, the input formats it supports, and how you can integrate it into your own applications. We’ll dive into key use cases – from image captioning and VQA to OCR, document parsing, and using Qwen2.5-VL as a visual agent. Code examples (in Python) will illustrate how to load the model, supply image+text prompts, and parse its outputs for different tasks.
We’ll also discuss real-world deployment scenarios, best practices to get optimal results, and important limitations to keep in mind. By the end, you should have a clear understanding of what Qwen2.5-VL can do and how to harness it in your projects.
Architecture Overview
At a high level, Qwen2.5-VL consists of a vision encoder coupled with the Qwen2.5 large language model. The vision encoder is a Transformer (ViT) that processes images into a sequence of visual tokens, which are then fed into the language model to be integrated with textual context. The architecture introduces several innovations to improve efficiency and flexibility:
Dynamic Resolution Encoding: Rather than forcing every image to a fixed size, Qwen2.5-VL uses a “naive dynamic resolution” approach. It can ingest images of various resolutions and aspect ratios by converting them into a dynamic number of tokens proportional to image size. In other words, a larger or more detailed image will produce more tokens, allowing the model to preserve fine details. This avoids excessive downsampling and enables the model to natively perceive different spatial scales. Notably, the model does not normalize bounding box coordinates or image positions to a fixed scale – it learns with actual pixel coordinates, so it inherently understands absolute sizes and distances in the image. This is a big advantage for tasks like object detection or measuring regions in an image.
Enhanced Vision Transformer with Window Attention: To keep computation tractable despite variable image sizes, Qwen2.5-VL’s ViT uses a mix of global and windowed self-attention. Only a few layers use full (global) attention, while most use Window Attention with a fixed window size (e.g. 8×8 patches). This means the image is processed in localized chunks for efficiency, without needing to pad smaller images up to a huge size. Regions smaller than the window require no padding and retain their original resolution. Combined with optimizations like RMSNorm and SwiGLU activation (borrowed from the LLM’s design), the vision encoder is streamlined and faster. This careful design yields faster training and inference, aligning the vision backbone closely with the language model’s architecture.
Multimodal Positional Encoding (M-RoPE): Qwen2.5-VL extends the Rotary Positional Embeddings used in Qwen LLM to handle two new dimensions – vision and time. For images, the model can handle different spatial positions and scales thanks to multi-scale RoPE. For videos, an absolute time encoding was introduced, along with dynamic frame rate (FPS) sampling, so that the temporal sequence of frames is encoded with actual time intervals. Essentially, the model learns the “pace” of time by the spacing of frame tokens. This allows it to comprehend very long videos (over an hour) and even pinpoint events at specific timestamps, a capability far beyond typical image-only models. The temporal encoding is integrated with the spatial encoding, enabling joint space-time reasoning for video inputs.
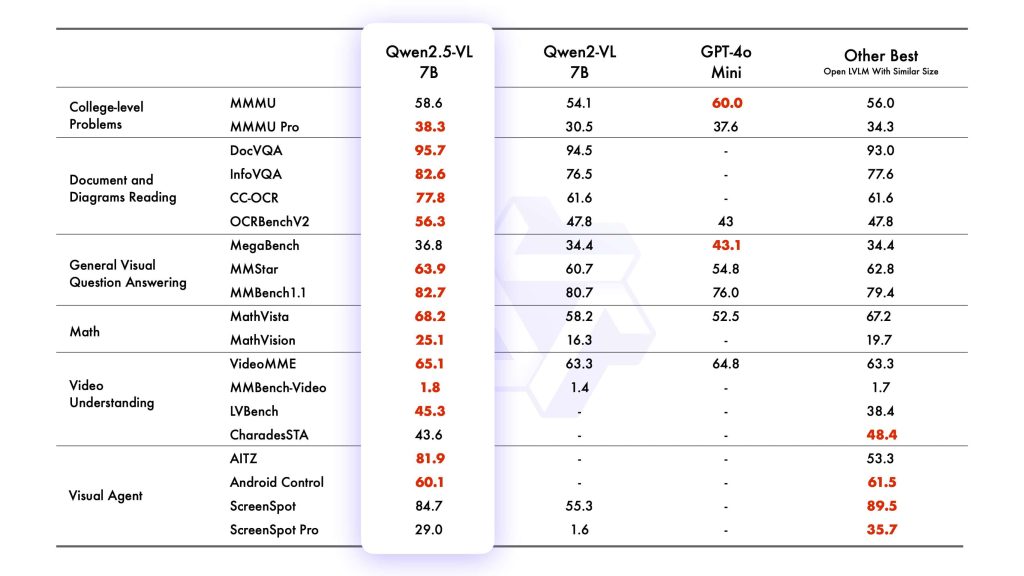
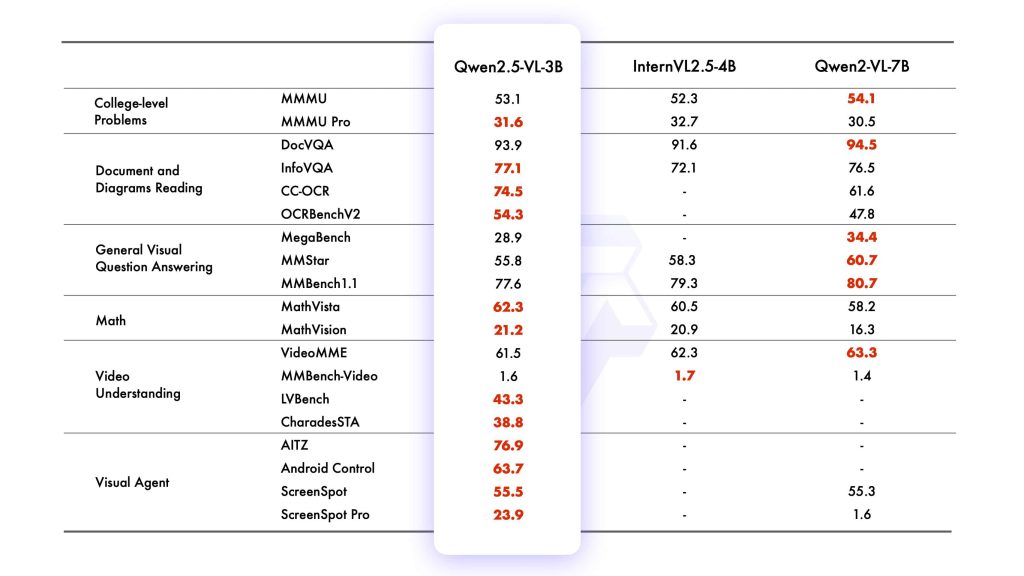
Model Sizes and Variants: Qwen2.5-VL is released in three model sizes – roughly 3 billion, 7 billion, and 72 billion parameters – each available in a base version and an instruction-tuned version. The base models are pretrained on multimodal data (image/text) but not specifically aligned to follow user instructions. The Instruct models have undergone supervised fine-tuning and reinforcement learning from human feedback, so they are better at following natural language prompts and producing helpful, safe responses. In this article we focus on the instruct models (e.g. Qwen2.5-VL-7B-Instruct and 72B-Instruct), as these are most suitable for developers to use out-of-the-box. Despite their size differences, all share the same architecture and features – the smaller models are distilled versions intended for lower resource environments (for instance, the 3B model is touted for edge AI use and even outperforms the old 7B Qwen-VL model). The largest 72B model is the flagship that achieves the best accuracy (competitive with the top-tier multimodal models in the industry).
In summary, the Qwen2.5-VL architecture was crafted to handle diverse visual input (images or video) with varying size and timing, feeding into a powerful language model core. By training the vision encoder from scratch with these dynamic and multi-scale techniques, Qwen2.5-VL can natively handle high-resolution details and long temporal sequences.
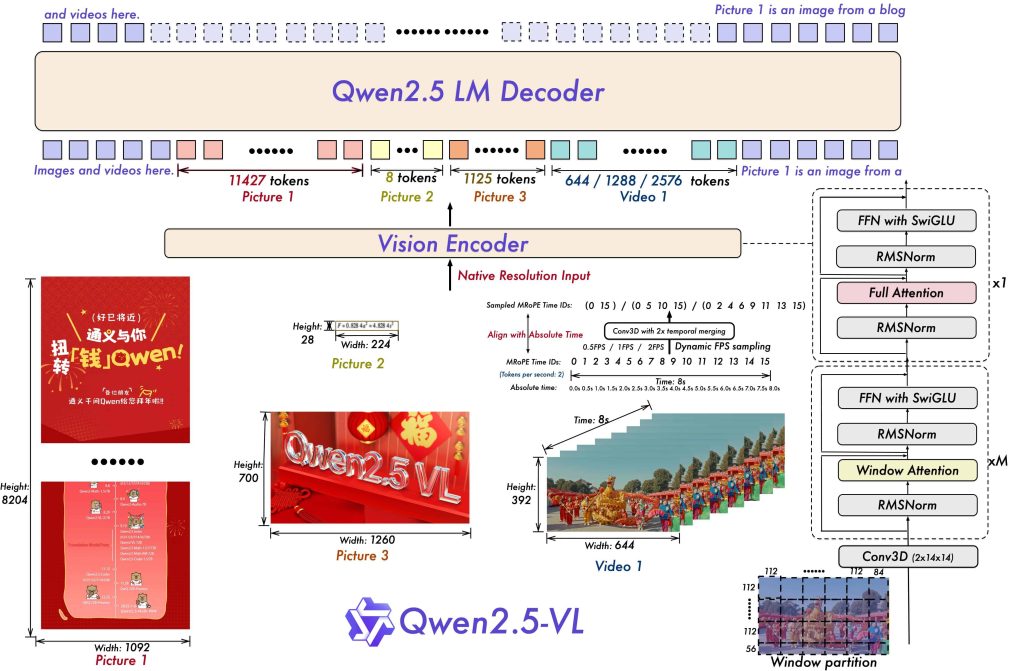
This makes it adept at tasks like reading fine print in a document or analyzing a lengthy video, all while generating coherent text answers. The integration with the Qwen2.5 LLM ensures it retains strong language understanding and can follow instructions or have a dialogue about the visual input. Next, we’ll look at how you provide inputs to Qwen2.5-VL and what formats it supports.
Input Formats and Supported Modalities
Interacting with Qwen2.5-VL involves supplying both images (or video frames) and text prompts in a structured format. The model is built to handle multi-turn conversations with interleaved images and text. In practice, the input is formatted as a sequence of messages (like a chat) with roles (e.g. “user” and “assistant”) and content that can include text segments or images/videos.
For example, using Hugging Face’s Transformers API, you can construct a messages list where a user message contains an image followed by a textual question or instruction. Here’s what a single-turn prompt might look like in Python:
from transformers import pipeline
# Load Qwen2.5-VL instruct model (7B variant) on available GPU
pipe = pipeline(
task="image-text-to-text",
model="Qwen/Qwen2.5-VL-7B-Instruct",
device=0, # use GPU 0
dtype=torch.bfloat16
)
# Example prompt: an image + a question about it
image_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": image_url},
{"type": "text", "text": "Describe this image in detail."}
]
}
]
result = pipe(text=messages, max_new_tokens=100, return_full_text=False)
print(result[0]['generated_text'])
In the above snippet, we create a pipeline for the "image-text-to-text" task and specify the Qwen2.5-VL-7B-Instruct model. The messages structure follows the model’s expected input format: an array with a user role containing a list of content pieces. We first give an image (with a URL to an image of a cat, in this case) and then some user text asking the model to describe the image. When we call the pipeline, Qwen2.5-VL will process the image+text prompt and generate a text answer (accessible via result[0]['generated_text']). The output might be something like:
“The image shows a large fluffy gray cat lying on a sofa. The cat looks very well-fed and relaxed, with its belly exposed. Its eyes are half-closed in a content expression, and overall it appears to be a calm, chubby cat enjoying a lazy afternoon.” (The exact wording will vary, but Qwen2.5-VL is known for producing quite detailed descriptions.)
Under the hood, the AutoProcessor for Qwen2.5-VL handles preparing the image (loading and patchifying it) and adding special tokens around visual content in the prompt. If you use the lower-level API, you might call processor = AutoProcessor.from_pretrained(...) and then processor(images=<...>, text=<...>, return_tensors="pt") to get model inputs, or use processor.apply_chat_template(messages, ...) to format a multi-turn conversation. The pipeline abstraction, however, simplifies this by letting you pass the messages dict directly.
Multiple images and videos: Qwen2.5-VL supports more than one image in a single conversation, as well as video input. You can include multiple {"type": "image", ...} items in the content list (and even {"type": "video", "path": ...} for a video clip) before or between text segments. The model will assign each image or video a placeholder token internally (like <|image_1|>, <|image_2|> etc.) so that it can refer back to them if needed.
For example, you might have a dialogue: User: (Image A) “What is this device?” – Assistant: “It’s a vintage telephone.” – User: (Image B) “Now how about this one?” – here the model keeps context of which image is being discussed. Qwen2.5-VL can handle a few images interleaved with text in this way, as well as fairly long videos. To use a video with Transformers, you would mark content with "type": "video" and provide a local video file path or a sequence of frames. (Internally, the processor will extract frames; using the qwen-vl-utils library with the decord backend can speed this up.) According to the technical report, the model can ingest videos over an hour long and still pinpoint events with timestamps – thanks to its dynamic temporal encoding.
Image resolution and tokenization: Because of the dynamic resolution design, there isn’t a single fixed input image size for Qwen2.5-VL. By default, images are converted into between 4 and 16,384 visual tokens, depending on their pixel count. You can control the resolution processing via the processor’s min_pixels and max_pixels settings to balance accuracy vs. speed. For example, you might set min_pixels=256*28*28 and max_pixels=1024*28*28 to constrain the tokenization such that each image yields between roughly 256 and 1024 tokens.
Higher resolution (more pixels) gives the model more detail but will use more memory and compute; lower resolution trades off some detail for efficiency. In practice, the default is usually fine for typical images, but for very large images (e.g. high-res documents) you may raise the max_pixels to let it take in all the detail, or conversely lower it for speed if you only need a coarse analysis.
Output format: Qwen2.5-VL’s outputs are pure text. It does not generate images – it’s not a text-to-image model – rather it generates textual descriptions, answers, or data based on the visual input. The content of the output can be plain natural language (e.g. a paragraph describing the scene) or a structured format like JSON or HTML if you prompt it accordingly. Notably, the model has been fine-tuned to follow instructions about output format quite strictly, which means you can trust it to produce valid JSON or HTML when asked. For instance, if you say “Detect all faces and give their bounding boxes in JSON format”, Qwen2.5-VL will return a JSON array of coordinates and labels, without extra commentary.
Similarly, it can output an HTML representation of a document’s layout (the special QwenVL HTML format) when requested – essentially treating document parsing as a conversion to HTML with text and positioning metadata. We’ll see examples of these structured outputs in the use cases section. The key point is that you, as the developer, control the format by how you prompt the model. This makes Qwen2.5-VL very flexible: it can be a conversational agent, a caption generator, or a data extractor depending on your instruction.
Having covered how to feed inputs and request outputs, let’s explore Qwen2.5-VL’s capabilities in specific domains and how to use the model for each.
Use Cases and Capabilities
Qwen2.5-VL is a generalist, but it has been specifically tuned and evaluated on a variety of vision-language tasks that are highly relevant for developers. Below we break down its key use cases and what you can expect for each:
1. Image Captioning and Description
One of the basic functions of Qwen2.5-VL is image captioning – generating a textual description of a given image. Thanks to its large training corpus and strong language model core, Qwen2.5-VL can produce very detailed and coherent captions. It doesn’t just list objects; it often captures relationships, attributes, and context. For example, given a photograph of a living room, it might output: “A cozy living room with a gray sofa and a television. A cat is curled up on the sofa, and sunlight is coming through a window to the right, illuminating a coffee table with books.” This goes beyond a trivial caption, demonstrating spatial understanding and scene context.
The model’s visual recognition breadth means it can identify a huge range of entities in images. As noted, it was trained on diverse categories – from common animals and food items to specific products and even fictional or iconic characters. This means your captions will often include proper names or specific terms when appropriate (e.g. “Porsche 911 sports car” instead of just “car”, or “Great Wall of China” instead of “a wall” if the landmark is recognizable). In team benchmarks, Qwen2.5-VL showed substantially improved recognition of fine-grained categories and rare objects, which makes its captions richer in information.
Another strength is multilingual captioning. Qwen2.5-VL can understand prompts and produce output in multiple languages. The examples provided by the authors show it naming objects in both English and Chinese simultaneously. If you ask in English, you’ll get an English caption by default; if you ask in Arabic or French, it will likely respond in that language. This is extremely useful for applications where you need localized descriptions (for accessibility or user experience in a given locale). The model’s OCR abilities (discussed next) also feed into captions – for instance, if there’s visible text in the image (like a street sign or product label), Qwen2.5-VL might include what it says as part of the description.
To use Qwen2.5-VL for captioning in code, you simply provide an image and a prompt like “Describe this image.” (as we did in the pipeline example above). No special format is needed; the model’s default behavior on a single image + “describe” prompt is to output a descriptive paragraph. You can further steer the style by prompt: e.g. “Describe this image in one sentence.” or “Provide a creative caption for this image.” and it will follow suit. In summary, Qwen2.5-VL makes it straightforward to generate informative captions, which can be used in image search, social media alt-text, digital asset management, etc.
2. Visual Question Answering and Reasoning
Beyond generic captions, Qwen2.5-VL shines at visual question answering (VQA) – answering arbitrary questions about an image. This could be as simple as “What color is the car?” or as complex as “What is happening in this picture and why might it be important?”. Because Qwen2.5-VL retains the full power of a language model, it can provide reasoned, contextual answers rather than just blunt identifiers. It can combine clues from the image with its world knowledge. For example, ask it “What might this tool be used for?” with a picture of an odd kitchen gadget, and it can infer likely uses. Or give it a scene of people and ask “How are they feeling?”, and it may interpret facial expressions and body language to answer (e.g. “They appear to be excited and happy, possibly celebrating something.”).
A special capability is visual reasoning – solving tasks that require logical inference on the image content. One common example is counting objects. Qwen2.5-VL can count with pretty high accuracy, even when objects are scattered or partially occluded. It was tested on benchmarks like COCO-Count and came out with strong results. Another example is comparing two things in an image (“Is the person taller than the door?”) or analyzing causality (“Why is the floor wet in this image?” – perhaps because it sees a spilled bucket). The model can handle these thanks to its training on both image-QA data and general knowledge.
Example: The image below shows a pile of coins spread out on a surface. If we ask Qwen2.5-VL, “How many coins are in this image, and what type of coins are they?”, it inspects the visual details and responds accordingly.
Qwen2.5-VL can accurately count and identify objects in an image. In this example, it determined there are 51 coins and recognized them as Indian 5-rupee coins, providing a detailed answer.
In the above scenario, the model not only counted 51 coins but also noted the currency and denomination (by recognizing the markings on the coins). This demonstrates multilayered reasoning: object detection, counting, and identification using domain knowledge (knowing what an Indian ₹5 coin looks like). Many traditional vision models would struggle to do all of these at once, but a multimodal LLM like Qwen2.5-VL can because it merges vision with contextual knowledge.
Using Qwen2.5-VL for VQA is as simple as providing the image and phrasing your question. You don’t need to tell it how to answer; the instruction tuning ensures it will attempt a helpful answer. If the question expects a structured answer (e.g. “List all the items you see with their colors”), the model will format the answer accordingly (a list in text form, unless you specifically ask for JSON). For more complex reasoning, you can have a multi-turn dialogue. For instance, you might ask a high-level question, get an answer, then ask a follow-up for clarification. The model keeps context of the image throughout the conversation (unless you explicitly reset it), which means in the second question you don’t need to re-send the image – it remembers what it saw.
Qwen2.5-VL has been evaluated on VQA benchmarks like DocVQA, TextVQA, and InfoVQA, and it achieves top-tier accuracy. This indicates it not only handles images of natural scenes but also specialized cases like questions about documents and charts (more on those shortly). In practice, this means you can trust it for building QA systems in domains like e-commerce (ask about product images), education (ask about diagrams or textbook figures), or general photo understanding.
3. Optical Character Recognition (OCR) and Text Reading
Reading text in images is a critical skill for many applications, and Qwen2.5-VL includes a very robust OCR capability. It can detect and recognize text that appears in images, such as signage, documents, screenshots, subtitles in videos, etc. This goes hand-in-hand with its document parsing abilities, but it’s worth focusing on OCR alone first.
Qwen2.5-VL’s OCR module was significantly upgraded from the previous version: it can handle multiple languages, different fonts, and orientations of text. Whether the text is horizontal, vertical (common in East Asian documents), curved (like on a logo), or at an angle, the model can still read it. It was trained on a large corpus of scene text and document text, so it learned to recognize characters in English, Chinese, Japanese, Arabic, Cyrillic, and more. For example, the model was shown an image with Arabic store signage and correctly transcribed the text (including phone numbers) line by line. In benchmarks, Qwen2.5-VL outperforms most open models on text recognition tasks – it scored the highest on an internal OCR challenge and very well on TextVQA which combines vision and reading.
It’s important to note that Qwen2.5-VL doesn’t output text in image as a separate modality – it integrates the recognized text into its answer. You can prompt it in a couple of ways for OCR:
- Plain transcription: “Read all the text in this image.” The model will then output the strings of text it finds, usually separated by lines or in a logical order. For example, given a photo of a sign with multiple lines, it might return each line of text on a new line. If the image is a receipt or form, it might list each field’s text content in sequence. This is straightforward when you just need the raw text.
- Localized text (detection + recognition): If you need the positions of text (for example, to highlight them or to reconstruct a document layout), you can ask for output in JSON with coordinates. For instance: “Spot all the text in the image and return a JSON list of objects with ‘bbox’ and ‘text’.” Qwen2.5-VL will then produce something like:
[{"bbox_2d": [x1,y1,x2,y2], "text_content": "Hello World"}, {...}, ...]. Each entry has the bounding box of a line or word and the text content. Impressively, the model is consistent in this format – it will include every detected text segment as an element in the JSON array. This kind of structured OCR output can directly feed downstream systems (for example, you could parse the JSON in Python to get a list of texts and their locations). - Focused extraction: You can also instruct the model to extract specific information from an image with text. For example, “From this invoice image, find the ‘Invoice Number’ and ‘Total Amount’.” Qwen2.5-VL will combine OCR with its language understanding to identify those key fields and output their values. In one example, given a Chinese train ticket image, it correctly extracted fields like 发票代码 (invoice code), 乘车日期 (travel date), 座号 (seat number), etc., and returned them as JSON keys with the corresponding values. This is essentially OCR + information extraction in one step, powered by the model’s ability to comprehend what the text means.
Using Qwen2.5-VL for OCR tasks in code is similar to VQA: you supply the image and a prompt describing what you need. If it’s generic OCR, just say “read all text” or “extract all text lines”. If it’s targeted, specify what fields or format you want. Because Qwen2.5-VL has been trained on documents and forms, it often knows the terminology (e.g. it recognizes an address, a date, a total amount, etc.) and can smartly give you the result. This makes it extremely useful for automating data entry from scans, understanding IDs, receipts, bills, business cards, and so on. Essentially, it combines what normally required separate systems (text detection, text recognition, form understanding) into a single unified model.
One thing to be mindful of: for very long documents or dense text, the image might convert to a lot of tokens. Qwen2.5-VL can handle it, but ensure your max_new_tokens is set high enough so it doesn’t cut off the output. Also, if the document is multi-page, you’d feed each page as an image (or use the conversation to handle page by page). The model doesn’t have a built-in notion of “pages” except as separate images.
4. Document Understanding and Structured Data Extraction
Moving a step beyond plain OCR, Qwen2.5-VL is capable of comprehensive document understanding. This means it not only reads the text, but also grasps the layout and can output structured representations of documents like forms, tables, and charts. The developers introduced a novel output scheme called QwenVL HTML for this purpose. In QwenVL HTML format, the model represents the document as an HTML snippet, where each element (like headings, paragraphs, table cells, images in the document) is marked with tags and has data-bbox attributes indicating its position on the page. Essentially, the model is doing what a document OCR pipeline plus a layout parser would do: turning a magazine page or PDF into a HTML DOM structure with text content and bounding boxes.
For example, if you show Qwen2.5-VL a research paper page and ask for QwenVL HTML, it might produce output like:
<h1 data-bbox="x1 y1 x2 y2">Title of Paper</h1>
<p data-bbox="x1 y1 x2 y2">Author names...</p>
<div class="image" data-bbox="x1 y1 x2 y2">
<img data-bbox="x1 y1 x2 y2" />
</div>
<p data-bbox="x1 y1 x2 y2">Figure caption text...</p>Every piece of content is enclosed in a semantically appropriate tag (heading, paragraph, list, etc.), and the coordinates on the page are preserved. This is extremely powerful for digitizing complex documents while keeping their format. It works on a variety of structured content – magazines, academic papers, websites, mobile app screenshots – anything where the spatial arrangement is meaningful. Qwen2.5-VL essentially performs end-to-end document layout analysis.
Another area is tables and charts. Qwen2.5-VL can parse tables in images and extract their cells. If you ask it, “Output the data in this table as CSV,” it will read the table and give you comma-separated values. Or you can ask for JSON. This is invaluable for scenarios like processing financial statements, lab reports, or any tabular data that only exists as images/PDFs. Similarly, for charts or graphs, the model can describe them or even extract numeric values if clearly shown. The Qwen team reported significantly better performance in benchmarks like ChartQA (questions about chart images), indicating that the model not only sees the text in the chart but understands the visual structure (axes, bars, trends) enough to answer questions. For example, if shown a bar chart image and asked “Which category has the highest value and what is that value?”, Qwen2.5-VL can determine the tallest bar and its label/value from the chart.
Let’s consider a concrete use case: processing an invoice or form. Suppose you have thousands of scanned invoices from different suppliers and you want to extract structured data (like invoice number, date, total due, line items, etc.). You can feed each invoice image to Qwen2.5-VL with a prompt like: “Extract the following fields from this invoice: Invoice Number, Date, Bill To, Total Amount. Return a JSON object with these fields.” The model will locate the relevant text on the invoice (using OCR) and output something like:
{
"Invoice Number": "INV-100123",
"Date": "2025-07-01",
"Bill To": "Acme Corp, 123 Main St, City...",
"Total Amount": "$5,412.00"
}If any field is missing, it might output null or an empty string for that field. You could also ask it to include the bounding box for each field if you need to double-check or highlight it. The fact that Qwen2.5-VL understands document semantics (it knows what a “Total Amount” looks like, often appearing at the bottom with a dollar sign, for instance) helps it ignore irrelevant text and zero in on what you asked for.
The model is also capable of some cross-document reasoning. An impressive example from the Qwen team: they gave the model an image of a courier label and a photo of a house door (with a number on it) and asked it to verify if the package was delivered to the correct address. Qwen2.5-VL extracted the address from the label (1935 South Wabash Ave…) and the house number from the door (1935), then compared them and concluded they match – hence the delivery is correct. This shows the model doing multi-image analysis and logical verification, which goes beyond a single OCR or caption. In practical terms, you could use it for things like checking if a shipping label matches the contents of a package, or if two forms have consistent information.
Overall, Qwen2.5-VL greatly simplifies document AI tasks. Instead of stitching together an OCR engine, a layout analyzer, and a rule-based extractor, you can prompt this one model to do it all. The quality of results is state-of-the-art for open models – the 72B version in particular is on par with proprietary solutions in many document benchmarks. The key to getting good results is to clearly instruct the format you want (plain text summary, specific fields, JSON, HTML, etc.), and ensure the image quality (resolution) is sufficient for the tiny text. If you find the model struggling on very crowded documents, consider splitting the page or increasing max_pixels to let it take in more detail.
5. Object Detection and Localization with JSON Output
Another notable capability of Qwen2.5-VL is precise object grounding – essentially, identifying objects in an image and giving their coordinates. While traditional computer vision approaches (like YOLO or Faster R-CNN detectors) can output bounding boxes for predefined classes, Qwen2.5-VL offers a more flexible, language-driven approach. You can ask it to find arbitrary things and output results in a structured format.
For example, you might prompt: “Detect all motorcyclists in the image and return their locations as bounding boxes. Also note whether each is wearing a helmet or not. Provide output as a JSON list of objects with fields bbox_2d, label (motorcyclist), and sub_label (helmet status).” Qwen2.5-VL will then analyze the image and output something like:
[
{"bbox_2d": [341, 258, 397, 360], "label": "motorcyclist", "sub_label": "not wearing helmet"},
{"bbox_2d": [212, 332, 274, 448], "label": "motorcyclist", "sub_label": "not wearing helmet"},
{"bbox_2d": [66, 124, 112, 198], "label": "motorcyclist", "sub_label": "not wearing helmet"},
{"bbox_2d": [5, 235, 63, 320], "label": "motorcyclist", "sub_label": "wearing helmet"}
]
This is exactly what the model produced in an example for an image with several people on motorcycles. The bounding boxes (x1,y1,x2,y2 pixel coordinates) tightly frame each person on a motorcycle, and the model correctly identified whether they had helmets. Such output can be directly parsed by a program. You could loop through the list in Python to count helmet vs no-helmet, or draw the boxes on the image for visualization.
Example of Qwen2.5-VL’s object localization. The model was asked to find all motorcyclists and whether they wear helmets. It returned bounding boxes for each rider, enabling drawing of precise boxes around them (green boxes indicate detected motorcyclists, with labels for helmet status). The JSON output from the model is shown above.
Under the hood, Qwen2.5-VL treats this task as just another language generation – but because it has learned the concept of JSON formatting and coordinate numbering during fine-tuning, it can output well-formed JSON consistently. The model was likely trained with some vision-and-language data that included bounding box descriptions, which is why it knows how to align coordinates with image content. This ability serves as a foundation for visual reasoning; for instance, the model can first “think” in terms of where objects are, and then reason about relationships (like distances or counts) among those objects.
You are not limited to pre-defined categories. You could ask for things like “the red circles in the diagram” or “any animals visible, with their locations” and it will try to comply. However, note that extremely fine-grained detection (e.g. detecting all instances of dozens of classes at once) is not the primary design – a dedicated detection model might still be better for, say, COCO-style 80-class detection. Qwen2.5-VL is most useful when you need a detector on-the-fly for a custom query or when you also need accompanying reasoning. For example, “Find the basketball players in this image and mark points on their hands and heads.” The model can output key point coordinates for “head”, “left hand”, “right hand” for each player, even naming the players if they are famous. That’s something hard to do with off-the-shelf detectors which don’t know identities or abstract concepts like left/right in an image – but Qwen2.5-VL can integrate visual recognition with knowledge (it recognized the players as LeBron James and Stephen Curry in the example, by their jerseys and faces) and follow the instruction to output labeled points.
From a developer’s perspective, using Qwen2.5-VL for object localization involves crafting the prompt carefully to specify the output format and the target objects. It’s often helpful to show an example in the system message if consistency is crucial (few-shot prompting with a dummy JSON output), but in many cases the model does well zero-shot as demonstrated. Always parse and validate the JSON string output – the model usually gives a parseable JSON, but slight format issues can be handled (for instance, remove trailing commas or use a JSON forgiving parser if needed). The Qwen team specifically noted that the model provides “stable JSON outputs” for coordinates, so it’s generally reliable.
Possible applications of this include: ad-hoc image analysis in user queries (e.g. “find the logo in this image and give me its position”), robotics (a robot’s vision system asking the model “where is the cup on the table?” and then using the coordinates to grasp it), or any scenario where you quickly need to detect something without training a custom model.
6. Multimodal Agent and Tool-Usage Workflows
One of the most intriguing use cases of Qwen2.5-VL is using it as a multimodal agent – effectively, an AI that can not only understand visuals and language but also take actions in a digital environment. This is similar in spirit to how one might use GPT-4 with vision to control a computer (for example, the idea of an AI that sees your screen and clicks buttons for you). Qwen2.5-VL has been designed with this agentic capability in mind. In fact, the authors highlight “Being agentic: [it] directly plays as a visual agent that can reason and dynamically direct tools, capable of computer use and phone use.”.
What does this mean concretely? Imagine you have a smartphone UI and you take a screenshot. You could feed that image to Qwen2.5-VL and say something like, “Open the Settings app and turn on Bluetooth,” or “Please book a one-way flight from NYC to LA on January 28th using the booking app shown.” The model will interpret the instruction and the visual context (the UI screenshot), then generate a series of actions or a plan to accomplish the task. For example, it might output: “1. Tap on the ‘Flights’ icon. 2. Enter ‘New York’ in the From field and ‘Los Angeles’ in the To field. 3. Select date Jan 28. 4. Tap Search. 5. Choose a flight and tap Book.” – or if integrated with an automation API, it could output a JSON of actions/click coordinates, etc., depending on how you prompt it. Essentially, the model can serve as the “brain” of a UI automation agent, deciding what to do based on what it sees on the screen.
Similarly on a desktop, Qwen2.5-VL could be fed screenshots of a computer and you ask, “Find the weather for Manchester, GB for this month” (one of the example prompts) – it could then output something like: “Opening browser, navigating to weather.com, searching ‘Manchester monthly weather’, reading the result: …” or directly provide the answer if it’s allowed to use tools like an API. The model was tested on several benchmarks for agent tasks (like controlling Android apps, performing web navigation, etc.) and achieved promising scores. This indicates it can follow through with complex, multi-step instructions in a grounded visual context.
To leverage Qwen2.5-VL as an agent in your own projects, you would likely use it in combination with a tool execution environment. For instance, you can set up a loop where the model looks at the current state (an image of a screen or a description of available tools), the user’s goal, and then outputs an action. Your code then carries out that action (like clicking a button, or calling an external API if the model says “use calculator tool to add numbers”), and then you capture the new state (e.g., a new screenshot or updated info) and feed it back to the model, and repeat. This turns Qwen2.5-VL into the decision-maker in a control loop, enabling visual-feedback loops. A simpler scenario is a static one where you just want the plan – you give an image and ask for instructions. The model will output a numbered list of steps in natural language. You can then parse those and execute them with another script or human-in-the-loop.
One area this is immediately useful is UI testing and RPA (Robotic Process Automation). Instead of writing brittle scripts to find UI elements, you can literally ask the model in plain English, and it will navigate the UI as a human would (“click the ‘Save’ button”, “scroll until the Settings icon is visible, then tap it”). Another area is assistive technology: e.g. for users who are visually impaired, a system could use Qwen2.5-VL to interpret what’s on screen and perform actions via voice commands (“read my WhatsApp messages and reply ‘I’ll be there soon’” – the agent can find WhatsApp on the phone, open the chat, read messages aloud, then send a reply dictated by the user).
It’s important to note that, currently, such agent capabilities with Qwen2.5-VL require you to build the surrounding infrastructure (the model itself won’t actually press the buttons; it only tells you what to do). Also, safety is a consideration – the model might attempt actions that are harmful or outside allowed bounds if not constrained, so implementing guardrails or confirmations is wise. The Qwen team demonstrated that their model could do things like install a VS Code extension given a prompt, or compose a new year greeting message to a contact on QQ, which showcases its versatility. These were done presumably with a research prototype environment. As developers, we can start experimenting by hooking Qwen2.5-VL into our own tool frameworks (e.g. combining it with langchain or custom Python scripts for tool use).
In summary, Qwen2.5-VL opens the door to multimodal agent workflows where an AI can see and act. While this is an emerging area, the model’s ability to interpret visual context and generate step-by-step plans is a game-changer. It allows building assistants that can handle tasks involving reading screens or operating software without hardcoded instructions. Keep an eye on this capability if your application could benefit from automated UI interactions or complex multi-step visual reasoning.
Integration: Using Qwen2.5-VL in Your Applications
Integrating Qwen2.5-VL into a project can be done via open-source libraries or APIs. Here we focus on a Python integration using Hugging Face Transformers, which is a common way to deploy the model locally or on a server. We already saw a simple pipeline example; let’s break down a few integration tips:
Loading the Model: If using Transformers, make sure you have a recent version (Qwen2.5-VL support was added in early 2025, so use Transformers >= 4.33 or install from source as recommended). You can load the instruct model as shown:
from transformers import AutoProcessor, Qwen2_5_VLForConditionalGeneration
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
processor = AutoProcessor.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct"
)This will download the model weights (which are several gigabytes for 7B) and the processor (tokenizer + image preprocessor). The device_map="auto" will distribute the model on available GPUs (or CPU if none). For 72B model, you’d need multiple GPUs or at least one 80GB memory GPU – otherwise consider the 4-bit quantization trick below.
Memory and Quantization: Running the large models can be resource-intensive. The 7B model typically requires ~14–16 GB of GPU VRAM for full precision; the 72B can require >60 GB (usually split across 8× 80GB GPUs for training). If you don’t have that, you can use model quantization to reduce memory. Qwen2.5-VL supports 4-bit and 8-bit quantization. For example, using the torch Accelerated Orthogonal (AO) backend:
from transformers import TorchAoConfig
quant_config = TorchAoConfig(
bit_width=4,
computation_dtype=torch.bfloat16
)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct",
quantization_config=quant_config,
device_map="auto"
)This would load the 7B model in 4-bit weight precision, cutting memory usage significantly. You can also try the bitsandbytes 8-bit or 4-bit integration (load_in_4bit=True with bnb_4bit_quant_type="nf4" etc.). The performance drop from quantization is usually minimal for 7B; for 72B, int4 can still preserve a lot of the capability while making it feasible to run on a single high-end GPU.
Inference Pipeline vs. Manual: For quick prototypes, the pipeline("image-text-to-text", ...) approach is very convenient as shown earlier. It wraps the model and processor and handles multiple modalities. If you need more control (say you want to feed a video or manipulate the conversation history), you might use the model’s generate function directly. In that case, you would do something like:
inputs = processor(
images=[image1, image2],
text=prompt_texts,
return_tensors="pt"
)
outputs = model.generate(
**inputs,
max_new_tokens=200
)
answer = processor.decode(
outputs[0],
skip_special_tokens=True
)But the exact usage is tricky because you have to format the prompt with vision tokens. It’s easier to use the high-level conversation format as the Qwen docs suggest. There is also a utility library qwen-vl-utils which provides helpful functions like process_vision_info to embed images/videos into the prompt and manage IDs.
Handling Outputs: The model’s text output will come as a string. If you requested a structured format like JSON, you should parse this string to ensure it’s valid JSON. Usually, json.loads(output_str) will work if the model obeyed the format. If the model added some explanation text before or after the JSON (which it usually doesn’t if prompted well), you might need to extract the JSON portion. One strategy is to wrap your prompt with something like: “… output only a JSON, with no extra commentary.” Qwen2.5-VL tends to follow that instruction reliably (it was a focus of their fine-tuning to yield “standardized JSON output” for such tasks).
Batch Processing: If you have many images to process independently (say, captioning 1000 images), you can use the pipeline or model in batch mode. The pipeline supports a batch of inputs (just pass a list of messages). The model can also handle batch dimension if you prepare inputs with multiple images. Just be mindful of memory – processing several images simultaneously multiplies the token count.
API Deployment: If you want to serve Qwen2.5-VL as an API (e.g., a REST endpoint that takes an image and returns an answer), you can do so by wrapping the above logic in a web framework (Flask/FastAPI). For instance, you’d accept an image file upload and a text query, call the model, and return the result. There is no official REST API from Alibaba for Qwen2.5-VL as of writing (besides their cloud service on ModelScope perhaps), but since it’s open, you are free to deploy it on your own infrastructure or platforms like Hugging Face Spaces. In fact, there is a Hugging Face Space demo for Qwen2.5-VL where you can upload an image and enter a prompt to see the model’s answer. That interface internally does exactly what we described.
Alternative Tools: The Labellerr blog demonstrated running Qwen2.5-VL 7B via Ollama, which is another way to use the model locally with an optimized backend. With Ollama, you can run a command-line or HTTP chat with the model, and even pass images (as base64) in the API call. If you prefer not to handle the model in raw PyTorch, such packaged solutions might be convenient. For example, after installing Ollama and pulling the Qwen2.5-VL model (ollama pull qwen2.5vl:7b), you can do ollama chat -m qwen2.5vl:7b -i image.jpg "Your prompt" and get an answer. Underneath, it’s similar to how we used the pipeline, but it abstracts the details.
Tool Integration (advanced): If you plan to use Qwen2.5-VL as part of a tool-using agent, you might integrate it with frameworks like LangChain. You can create a custom Tool that when invoked, captures a screenshot or image, then calls Qwen2.5-VL to analyze it. The model’s response (text) can then be fed back into your agent chain. Given Qwen2.5-VL’s multimodal nature, you might orchestrate it alongside a purely text LLM or just use Qwen for both text and image reasoning (since it’s also a full LLM, it can handle text-only queries too, but might be heavier than needed for purely textual tasks).
The bottom line is that Qwen2.5-VL can be integrated wherever you can run PyTorch models. The code examples above give a starting point. Just remember to handle the larger memory and compute requirements compared to text-only models – e.g. always check that your GPU has enough memory and consider using the smaller versions for prototyping. Next, let’s consider some real-world examples of how Qwen2.5-VL can be applied, and then cover the model’s limitations and best practice tips.
Real-World Applications and Demos
To solidify understanding, here are a few real-world scenarios where Qwen2.5-VL can be employed effectively:
- Automated Document Processing: Companies drowning in paperwork (invoices, receipts, contracts) can use Qwen2.5-VL to automate data extraction. For instance, an accounts payable system can auto-extract invoice numbers, dates, vendor names, and totals from PDF scans, populating a database with no manual entry. The model’s structured output (JSON/HTML) ensures integration with existing systems is smooth. This has applications in finance (processing expense receipts), logistics (reading bills of lading, labels), and healthcare (digitizing medical forms).
- E-commerce and Catalog Management: An online retailer with thousands of product images can generate rich descriptions and tags for each item using Qwen2.5-VL. It can identify product attributes from images (e.g., type of garment, color, pattern) and even read text on product packaging. This helps in creating better product listings and enabling visual search (customers searching by image). The model can also answer customer questions about product images: e.g., “Does this sofa have wooden legs?” by analyzing the photo.
- Interactive Visual Assistants: With Qwen2.5-VL, one can build an assistant that users chat with about images. Imagine a user uploads a photograph and asks, “What do you think is happening here?” – the assistant (powered by Qwen) can analyze it and respond conversationally. This is great for educational tools (students asking about a diagram or a painting), creative brainstorming (generating narratives about an image), or just fun applications. Because the model can handle dialogue, the user can continue asking follow-ups about the same image set.
- Multilingual Sign Translation: Travel and navigation apps could use Qwen2.5-VL to instantly translate signs, menus, or any foreign text that the user encounters. The user snaps a picture; the model reads the text (OCR) and then the app can translate it via a translation API (or you could prompt Qwen to translate it itself since it’s multilingual). The app could then overlay the translated text back on the image for an AR experience. Qwen’s ability to handle multi-language text makes it a one-stop solution for reading any script from Latin and Chinese to Arabic or Devanagari.
- Data Analysis from Charts: Analysts can feed chart images into Qwen2.5-VL to get quick summaries: “This is a sales bar chart, the highest bar is Q4 with $10M, indicating Q4 performed best. The trend shows…”. It’s like having a little assistant that can read graphs out loud or convert them to data. This can save time when you have image-only reports. It’s also useful for accessibility – converting visual data into text for blind users.
- AI-Powered UI Automation: As discussed, Qwen2.5-VL can be the engine behind an automation script. For example, a QA tester could use it to automatically test an app’s interface: feed screenshots and instructions, and let Qwen figure out if the right elements are present and clickable. Or an end-user could say “post this photo to my profile and add the caption ‘Sunset mood’” – a system could use Qwen to interpret the task and control the app to do it. This hints at future personal assistants that can bridge vision and action (with appropriate safety, of course).
- Surveillance and Safety Monitoring: With its object and person detection capabilities, Qwen2.5-VL could be applied (carefully) in security contexts – e.g., monitoring CCTV for certain scenarios: “alert me if you see a person without a hardhat in this area” – the model can identify people and check for helmets (like the motorcycle example). Because it can take image input continuously (frames of video), it could serve as a smart filter that flags situations for human review. (This should be done ethically and within privacy guidelines, naturally.)
These examples scratch the surface. Essentially, any application that previously required separate computer vision models, OCR pipelines, and language understanding can consider Qwen2.5-VL as a unified solution. Early adopters have already run the 7B model on local machines to experiment with tasks like UI understanding and chart analysis. The technology is accessible and does not require API fees or usage limits since it’s open source – you just need the compute.
To see Qwen2.5-VL in action, you can try the official Qwen Chat web demo (hosted by Alibaba Cloud), selecting the vision-language model and uploading images to chat. There are also community demos on Hugging Face Spaces for the 32B instruct model – these let you interact through a browser. Keep in mind the largest model will give the best quality, but even the 7B can be impressive on many tasks as a proof of concept.
Limitations and Best Practices
While Qwen2.5-VL is powerful, it’s not without limitations. Understanding these will help you deploy it more effectively:
1. Resource Requirements: As mentioned, the model is large. The 72B parameter version is challenging to run without very high-end hardware (multi-GPU). The 7B version is more accessible but still needs a decent GPU (ideally 16 GB VRAM or more) and plenty of RAM for loading the model weights (the fp16 model file is tens of GB). If you only have CPU, you’re likely limited to the 3B model and even that will be slow for complex tasks. Best practice is to use GPU acceleration and leverage quantization. If deploying at scale, consider using model parallel or optimized inference engines (TensorRT, vLLM, etc.) to serve responses faster.
2. Latency: Processing images is generally slower than text for these models. The vision encoder part adds overhead. Expect a single image query on 7B to take on the order of 1–3 seconds on a GPU, depending on image size and the length of the answer. The 72B could take ~10 seconds or more per image question on strong hardware. If you need real-time performance (e.g. in a live video analysis), you might need to use the smaller models or reduce the image resolution (max_pixels). Also consider batching if you have multiple queries, to amortize the cost of loading the model into memory.
3. Output Accuracy & Hallucinations: Although Qwen2.5-VL is generally reliable in describing what it sees, it can still hallucinate or make errors. For example, if an image is ambiguous or low-quality, the model might confidently state something that isn’t true. It might misread text if the font is unusual or the image is blurry (OCR is not 100% perfect). When it comes to reasoning, if the question involves external knowledge that the image alone can’t answer, the model might guess. Always have a validation step if using it for critical tasks – e.g. double-check important extracted numbers or ensure that any decisions made by an agent are reviewed by a human or a simpler rule-based check.
4. Complex Visual Tasks: Some tasks are still very challenging – e.g. interpreting medical images (like X-rays), or doing fine-grained identification that requires expert knowledge. Qwen2.5-VL has general knowledge but it’s not a specialist in every domain. It might do a decent job at obvious medical findings, but it’s not a certified diagnostic tool. Similarly, while it can identify celebrities or branded products (due to training data), using it for face recognition in a security context would raise both ethical and accuracy concerns. (And as an AI assistant, we also avoid identifying real individuals in images for privacy reasons.) Use caution and consider domain-specific fine-tuning if needed for high-stakes applications.
5. Bounding Box Precision: The model’s localization is good but not infallible. The boxes it outputs might be slightly off or loose. If you require pixel-perfect localization (for example in an AR overlay or for measurements), you might still need to refine the coordinates or use a dedicated detector as a post-processing step. The Qwen output can serve as a great starting point or proposal generator for objects, which you then refine. The authors did note that some advanced features like detailed keypoint detection or complex video analysis may benefit from the larger model sizes or more specialized prompting. So if you find the 7B model isn’t catching something, try the 72B or adjust your prompt to guide it.
6. Safety and Unexpected Refusals: Qwen2.5-VL, being an instruction-tuned model, does have some safety guardrails. It might refuse to answer if it thinks the request is sensitive or violates guidelines (for example, questions about an image that it interprets as private or unsafe). It may also be overly cautious (a trait observed in many RLHF-tuned LLMs), sometimes responding with warnings. This is generally a good thing for user-facing applications, but if you have a legitimate use that triggers a refusal, you may need to adjust the system prompt or fine-tune the model with custom data to relax certain constraints. Always abide by ethical use: avoid tasks that could be invasive (like surveillance on individuals) or generating harmful content. Even though it’s open source, responsible AI practices should be followed.
7. Best Prompting Practices: To get the most out of Qwen2.5-VL, be clear and specific in your prompts. For complex tasks, break down the request. The model is quite capable of multi-step reasoning (it can do some math, comparisons, etc.), but giving it a step-by-step prompt can improve reliability. For example, instead of asking directly “Is the door number in the label the same as on the house?”, you might prompt it in a structured way: “First, extract the house number from the delivery label and the house number from the door. Then state whether they match.” This was essentially done in the earlier verification example, and the model followed the steps and even organized the answer with headings. Using a chain-of-thought prompting style (like telling it to show its reasoning) can also work, though the model might include the reasoning in the final answer unless you instruct it to separate them.
Another tip: use the conversation history. Qwen2.5-VL can handle quite lengthy interactions with images. If the first answer isn’t what you need, you can ask a follow-up refining the request. For instance, “Actually, please output that as a table.” The model will take its own previous answer into account and reformat it. This can sometimes be easier than trying to get everything perfect in one prompt.
8. Utilize Smaller Models for Simpler Tasks: If your use case doesn’t require the full might of 72B, using the 7B or 3B can save a lot of resources. The 7B is quite good at common tasks like captioning and basic OCR. The 3B, while less accurate, might be sufficient for lightweight uses (and could potentially run on a CPU or mobile device for non-real-time tasks). Alibaba has positioned the 3B for edge AI, and indeed it can be a game-changer to have even a moderately capable multimodal model running on a device without internet.
9. Keep Up with Updates: Qwen2.5-VL is a snapshot in time (as of early 2025). The field is moving fast, and new models or versions may come that further improve on it (the existence of Qwen3-VL is already teased). The good news is your integration work is likely to carry over – these models adhere to similar interfaces. But always check for updates or community findings (e.g., prompt tricks, known issues). Given it’s open, you might also find fine-tuned variants on Hugging Face (for example, someone might fine-tune Qwen2.5-VL on medical images or on a specific language, and share the weights).
In conclusion on limitations: Qwen2.5-VL is currently one of the most advanced open multimodal models. Treat it as you would a very knowledgeable but sometimes quirky assistant – it can do a lot, but you need to guide it and double-check critical outputs. Optimize for your use case, use the right size model, and maintain oversight especially for agentic tasks.
Frequently Asked Questions (FAQs)
What exactly is Qwen2.5-VL and how is it different from a regular vision model?
What sizes of Qwen2.5-VL are available and what hardware do I need to run them?
Is Qwen2.5-VL free to use commercially, and where can I get it?
Qwen organization, e.g. Qwen/Qwen2.5-VL-7B-Instruct) and ModelScope. You can download the weights and run them on your own hardware. Alibaba also provides access through their cloud (ModelScope Model-as-a-Service) if you prefer not to host it yourself. Always double-check the latest license text in case there are usage restrictions (Apache 2.0 is very permissive; just note it comes with no warranty and you should give proper attributions in your documentation if required).How does Qwen2.5-VL handle videos? Can it really analyze hour-long videos?
Can Qwen2.5-VL generate images or only understand them?
How do I get Qwen2.5-VL to output structured data (JSON/HTML)?
json library) to use in your application.What are the differences between the -Instruct model and the base model?
Qwen2.5-VL-7B) are the raw pre-trained checkpoints. They are good at general pattern recognition but they might not follow instructions or converse as well. The *-Instruct models (like the 7B-Instruct and 72B-Instruct) have an additional layer of fine-tuning using supervised Q&A and human feedback alignment. These instruct versions are what you want for almost all use cases described here – they will respond helpfully to prompts without needing example demonstrations, and they tend to be safer. The base model might be useful if you plan to fine-tune on a specific dataset or if you want to see the “unfiltered” capabilities (which could include some raw knowledge but also possibly unguarded outputs). In summary, use the Instruct model for a chat or interactive system (the difference is analogous to GPT-3 vs ChatGPT, if that helps). The Qwen team has provided both, but the instruct ones are clearly marked in the model name.