
Qwen2.5-Max is a general-purpose Large Language Model (LLM) developed by the Qwen team at Alibaba Cloud. It stands out for its scale and capabilities: built with a mixture-of-experts (MoE) transformer architecture comprising 325 billion parameters and trained on over 20 trillion tokens. This extensive pre-training – followed by specialized Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) – equips Qwen2.5-Max with advanced reasoning skills and alignment for complex instructions.
As the flagship model of the Qwen 2.5 series, Qwen2.5-Max delivers the highest performance in the family, designed to tackle complex, multi-step tasks with ease. It is engineered for enterprise-grade AI workflows – from intricate data analysis to long-form content generation – and serves as a powerful tool for developers building AI systems.
Unlike domain-specific models, Qwen2.5-Max is a general-purpose LLM, meaning it can handle a broad array of tasks including natural language understanding, generation, coding, and mathematical problem-solving.
Its key strengths lie in advanced reasoning (solving problems that require step-by-step logic), long-context understanding (maintaining coherence over very large inputs or lengthy dialogues), and seamless integration into enterprise workflows (supporting structured outputs and tool use). In the sections below, we provide a technical deep-dive into Qwen2.5-Max’s architecture, capabilities, and usage – covering everything from its high-level design to code examples for integration.
High-Level Architecture
Mixture-of-Experts Design: Qwen2.5-Max employs a Mixture-of-Experts (MoE) architecture to achieve its massive scale. Instead of a single dense transformer, it contains multiple expert subnetworks and a gating mechanism that dynamically routes tokens to different experts. This design enables the model to reach 325 billion parameters without linearly increasing computation for every token. In effect, each input token activates only a subset of the model’s parameters, providing a huge capacity boost while maintaining feasible inference speeds. The MoE setup also allows certain experts to specialize (for example, some might focus on coding or math), which contributes to Qwen2.5-Max’s strong performance on those domains. Overall, the architecture is optimized to deliver maximum intelligence per unit of compute.
Transformer Backbone Enhancements: At its core, Qwen2.5-Max is a decoder-only Transformer with several modern enhancements. It uses Rotary Positional Embeddings (RoPE) to represent token positions, which scale effectively to long sequences. Feed-forward layers adopt the SwiGLU activation function (a gated linear unit variant) that improves training stability and model expressiveness. Layer normalization is done via RMSNorm for more stable gradient flow. The attention mechanism includes a learned bias on Q, K, V projections, and the model uses tied input-output embeddings (reducing parameter count without affecting performance). These design choices, carried over from earlier Qwen models, contribute to efficient training and inference.
Long-Context and Efficiency Techniques: Qwen2.5’s architecture integrates techniques to handle very long context lengths efficiently. One such feature is Grouped Query Attention (GQA), where multiple attention heads share the same key/value projections, significantly reducing memory usage for storing attention states. This is important for scaling to contexts of tens or even hundreds of thousands of tokens. Additionally, the Qwen team has explored novel attention paradigms like Dual Chunk Attention (DCA) and a method called YARN to improve how the model deals with long sequences and decides which parts of the context to attend to. Together, these ensure that even with extended context windows, the model remains computationally tractable and maintains coherence. (For example, the RoPE implementation was adjusted with a higher base frequency to allow up to 128K-token positioning with minimal loss of precision.)
Training Data and Post-Training: The model’s capabilities stem from both its architecture and an extensive training regimen. Qwen2.5-Max was pretrained on a massive high-quality corpus of about 18 trillion tokens, covering diverse domains, languages, code, and knowledge sources. This is over twice the data used for the previous Qwen-2 models, providing a richer foundation of common-sense and expert knowledge. On top of pre-training, Qwen2.5-Max underwent an intensive post-training phase: over 1 million curated examples were used in supervised fine-tuning, and multi-stage RLHF was applied to align the model’s outputs with human preferences. These steps notably improved its ability to follow instructions, generate structured data outputs, handle long documents, and produce helpful, aligned responses. The result is an architecture+training combination that not only has raw capacity and knowledge, but is also tuned for practical usability – it can produce well-formatted answers, follow complex directives, and reason through problems in a way that is useful for real-world applications.
(By routing each token through only a portion of the network’s experts, the MoE approach also offers some cost-efficiency: Qwen2.5-Max achieves extreme scale without a proportional increase in runtime compared to a dense model of similar size. This helps in serving the model at scale, though it still requires substantial computing infrastructure.)
Reasoning and Analytical Capabilities
One of Qwen2.5-Max’s standout strengths is its advanced reasoning ability. The model excels at tasks that require logical deduction, multi-step analysis, and careful handling of complex constraints.
Thanks to its large-scale training and fine-tuning, Qwen2.5-Max can break down complicated questions into intermediate steps and solve them in a human-like manner.
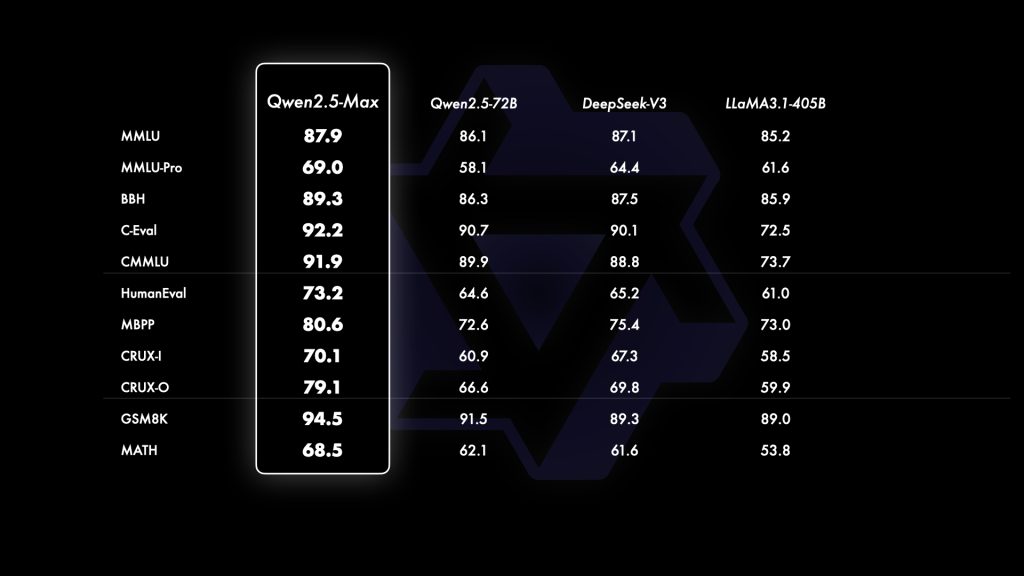
For example, on challenging mathematical reasoning benchmarks, a smaller 72B variant of Qwen2.5 already achieved an 83.1% accuracy on the MATH dataset – a result on par with or exceeding models several times larger. Qwen2.5-Max builds on this foundation and continues to push the state of the art in problem-solving.
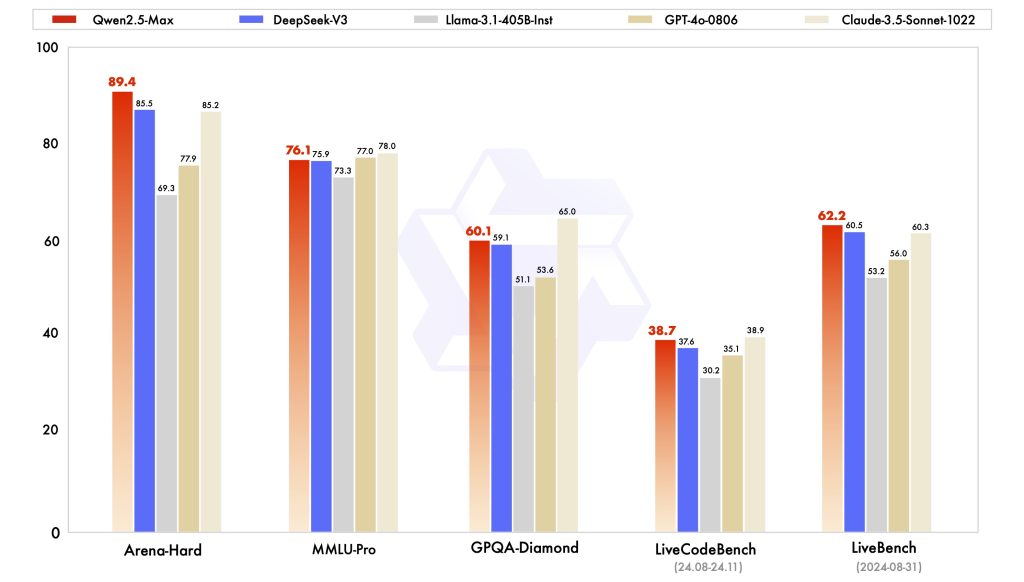
It has outperformed the previous generation of open large models on a range of evaluation sets – including difficult knowledge tests, coding challenges, and logical reasoning benchmarks.
In coding competitions (e.g. LiveCodeBench for programming tasks), Qwen models have taken the top spot, demonstrating an ability to not only generate code but also reason about code logic and errors (the Qwen2.5-72B instruct model scored 55.5 on LiveCodeBench, well above prior open models of similar size).
This LLM is particularly adept at chain-of-thought reasoning. It can be instructed to “think step by step” and will produce a well-structured explanation of its reasoning before giving a final answer. Under the hood, Qwen2.5-Max was trained on datasets that encourage such stepwise solutions. As a result, it handles questions like word puzzles, multi-hop factual queries, or complex decision problems with a clear logical progression. The model can keep track of intermediate results (for instance, doing calculations or breaking down a problem) and then combine them to reach the correct conclusion. This is invaluable for domains like debugging code (where the model needs to simulate code execution logically) or solving scientific word problems where intermediate reasoning is key.
Human-like judgment and alignment are also strong suits of Qwen2.5-Max. Through extensive RLHF tuning, it has learned to follow user instructions carefully and produce helpful, relevant answers. It scores highly on alignment benchmarks that evaluate how well responses align with human preferences – for instance, in the Arena-Hard test (a rigorous chat feedback benchmark), the Qwen2.5-Max instruct model dramatically outscored its predecessors. In practical terms, this means Qwen tends to stick to the user’s intent, clarify ambiguous questions, and avoid going off-track during multi-turn conversations. It can weigh different aspects of a problem and make reasonable judgments or decisions when asked for an opinion or recommendation, much like an expert human would (within the limits of its knowledge).
In summary, Qwen2.5-Max excels at reasoning-intensive tasks such as:
- Mathematical and logical problem solving – e.g. working through complex calculations, proofs, or puzzles step-by-step.
- Programming logic and debugging – interpreting code, finding bugs, explaining algorithms, and generating correct code (it can not only write code but also reason about code, which is crucial for debugging or optimization scenarios).
- Analytical Q&A – answering questions that require combining multiple pieces of information or evidence (it can perform multi-hop reasoning over given context, making it suitable for tasks like case analysis or academic QA).
- Decision support – comparing options, listing pros/cons, or making recommendations based on multiple criteria (the model can articulate the reasoning behind a choice, which is useful in domains like finance or policy).
The ability to explain its reasoning when prompted, and to internally chain reasoning steps even when not explicitly prompted, makes Qwen2.5-Max a reliable AI assistant for tasks that demand more than surface-level pattern matching.
Long-Context Handling
Qwen2.5-Max is designed to handle very long context windows, making it adept at tasks involving lengthy documents or extended dialogues. The model supports an input context of up to 32,768 tokens (around 32K tokens, which is roughly 24,000 words) in the current API implementation. This is an order of magnitude larger than the context length of many earlier-generation models. In practical terms, 32K tokens allows Qwen2.5-Max to ingest dozens of pages of text – for example, an entire academic paper or a detailed contract – and still reason about details from the beginning of the document. It can also maintain long conversations, remembering what was said tens of thousands of words ago. The model is capable of generating very extensive outputs as well (on the order of 8K tokens in a single response) without losing coherence. This makes it suitable for producing long-form content like detailed reports, multi-chapter stories, or exhaustive analytical answers in one go.
Under the hood, Qwen’s architecture and training explicitly account for long-context scenarios. The Qwen2.5 series introduced support for contexts up to 128K tokens by using advanced positional encoding and memory-management strategies. In practice, the default Qwen2.5-Max model uses a 32K window for stability, but the researchers have demonstrated the ability to go much further when needed. In fact, a special variant called Qwen2.5-1M was released, which can handle a staggering 1,000,000 tokens of context (about 800k words) in an experimental setting. Achieving this required innovations such as gradually extending context length during training and implementing sparse attention patterns in the inference engine. The Qwen team even built a custom inference framework (based on vLLM) to efficiently support such long sequences, achieving 3–7× faster processing of 1M-token inputs via optimized batching and memory management. While such extreme lengths are not typical for everyday use, it showcases the emphasis Qwen places on long-context understanding.
From a developer’s perspective, the 32K context window means you can feed Qwen2.5-Max substantial amounts of information as contextual grounding. For example, you could provide an entire knowledge base article or a lengthy log file as part of the prompt, and then ask questions about it – the model can reference any part of the provided text in its answer. This is invaluable for tasks like document analysis, where the relevant information might be spread across a long report. Similarly, in multi-turn conversations (such as a customer support chatbot that has a long interaction), Qwen2.5-Max can remember and utilize details from early in the conversation even after dozens of exchanges.
It’s worth noting that using very large contexts does carry computational costs: processing tens of thousands of tokens in a prompt is slow and resource-intensive. Qwen2.5-Max makes it possible to do this where previous models could not, but developers should still use the context window judiciously (e.g., by retrieving only relevant documents rather than always stuffing the maximum context). The model’s training included objectives to maintain coherence over long outputs, so it generally stays on-topic and consistent even as responses grow lengthy. However, extremely long generations (novel-length outputs) may require breaking the task into smaller segments or providing intermediate summaries to keep the model focused.
In summary, Qwen2.5-Max’s long-context capability unlocks use cases like:
- Analyzing long documents: The model can directly process entire manuals, research papers, or legal contracts and answer granular questions about them or produce summaries.
- Extended conversations and memory: It can serve in roles (like a personal AI assistant or tutor) where the conversation context accumulates over time without forgetting earlier details.
- Multi-document reasoning: By concatenating multiple documents into one prompt (as long as the total is ≤32K tokens), Qwen2.5-Max can perform comparative or synthetic analysis across a corpus. This is useful in retrieval-augmented generation – you can feed several retrieved passages and let the model integrate them in the answer.
- Large-scale content generation: For tasks such as writing a long report or book chapter, the model can generate in one continuous pass if needed, rather than in many small pieces, which can lead to more globally coherent output.
The key is that Qwen2.5-Max gives you the option to work with very large contexts, whereas previously one had to resort to complex workarounds (like chunking and stitching outputs). It provides a new level of flexibility for handling real-world data that often comes in lengthy forms.
Multilingual Proficiency
Modern applications often require support for multiple languages, and Qwen2.5-Max was built with that in mind. The model was trained on a multilingual corpus and can operate in over 29 languages out-of-the-box. This includes widely used languages such as English, Chinese, Spanish, French, Arabic, and many others – covering European languages as well as Asian languages like Japanese, Korean, Hindi, Thai and more. Not only can it understand and generate text in these languages, it can also transition between languages within a single session. For example, you could prompt Qwen2.5-Max in English and ask for an answer in French, or provide a mix of Chinese and English context and get a coherent bilingual response that blends both.
The model has been benchmarked on a number of multilingual evaluation sets and demonstrates strong performance across the board. It tackles knowledge and reasoning questions in non-English languages with nearly the same proficiency as in English. In internal evaluations, Qwen2.5 models showed high accuracy on language-specific exams – for instance, performing well on Arabic and Korean MMLU test sets (academic exam questions) when evaluated in those languages. This indicates the model isn’t just translating from English internally, but genuinely understands queries in those languages. The broad language training also means it has learned diverse scripts and cultural references, allowing it to produce contextually appropriate responses (e.g., it will use idiomatic Arabic when answering in Arabic, rather than a literal English-esque style).
Use cases of this multilingual ability include:
- Content translation and localization: Qwen2.5-Max can translate documents or messages between languages. You can, for example, feed it a paragraph in German and ask for a fluent English translation. It preserves nuances better than direct word-by-word translation, thanks to its context understanding. This is useful for localizing content or bridging communication between speakers of different languages.
- Multilingual chatbots/assistants: For global enterprises, a single Qwen2.5-Max instance can handle users in different languages. It can detect the input language and respond accordingly. If one user asks a question in Spanish and another in Chinese, Qwen can handle both within one model (no need to maintain separate models per language). This greatly simplifies deployment for multi-language customer service or information bots.
- Cross-lingual information retrieval: The model can consume information in one language and respond in another. For example, you could give it a French news article and ask it to summarize it in English. Or ask a question in English about a document written in Korean (by providing the Korean text) – the model will reason over the Korean text and produce an English answer. This cross-lingual transfer is extremely valuable for research and intelligence applications where sources are multilingual.
It’s important to note that while Qwen2.5-Max is very capable in many languages, the depth of knowledge it has might still vary by language. English and Chinese data were especially prominent during training (due to Alibaba’s focus and the abundance of data), so those languages tend to show the strongest performance. For languages with fewer training examples (say, a less common language of a specific region), the model might occasionally be less fluent or make more errors. That said, the fact that it handles tasks like Indo-European and East Asian languages at high levels is a big advantage. Developers should still test the model on critical tasks in the target language(s) and consider fine-tuning or providing examples if absolute precision is needed in a specific language domain.
Use Cases for Developers and Enterprises
Qwen2.5-Max’s capabilities unlock a variety of use cases in professional and enterprise settings. Below are some key scenarios where this model can shine:
Intelligent Agents and Tool Integration: Qwen2.5-Max can serve as the “brain” of AI agents that need to plan actions and call external tools. Its strong chain-of-thought reasoning means it can decide logically what step to take next in a multi-step workflow. For example, in an agent framework (such as one built with LangChain or a custom prompt-based agent), the model can analyze a user query and determine that it needs additional information or action – e.g., “The question asks for live data, I should call a search API”. It can then produce an output that your system interprets as a tool command (like a search query). The model’s fine-tuning for following system instructions makes it amenable to such use – it can follow hidden “thought” prompts or special tool-call formats reliably. In fact, the public Qwen Chat demo uses this concept: the model is able to perform web searches or even invoke image generation tools when asked, by outputting a prescribed format that the back-end recognizes (for example, a <search> tool tag). Developers can leverage this by defining a set of allowed tools (APIs, database queries, calculators, etc.) and prompting Qwen2.5-Max with an agent template. The model will essentially write the code or command to use the tool, step-by-step, enabling the construction of autonomous AI agents for tasks like research assistants, automated DevOps, or customer support bots that can retrieve information.
Retrieval-Augmented Generation (RAG): Because Qwen2.5-Max can handle very large contexts, it is a great fit for retrieval-augmented pipelines where the model is provided with external documents related to a query. A typical use case is a question-answering system on enterprise data: relevant documents (from a knowledge base or vector search) can be injected into the model’s prompt, and Qwen2.5-Max will read them and compose an answer that grounds itself in those references. The advantage of Qwen here is that you can supply a lot of text (multiple documents at once, potentially tens of thousands of tokens) for thorough answers. Its training on knowledge tasks means it will accurately extract and synthesize information rather than hallucinate. Developers have reported that Qwen tends to quote or cite facts from the provided text when asked to, making it easier to build systems that justify their answers. RAG with Qwen2.5-Max can be used for things like customer support chatbots (answering queries by pulling from product manuals, FAQ pages), legal analysis (finding relevant case law paragraphs to answer a legal question), or research assistants (reading academic papers and answering questions). The large context window means you don’t have to cut off potentially relevant information – Qwen can consider all the provided context and determine what matters.
Backend Automation and Workflow Orchestration: Qwen2.5-Max can automate complex backend tasks that traditionally required scripting or manual effort. For instance, consider log analysis in a production system: you could feed raw log data or error traces into the model (possibly chunked across the context if very large) and prompt Qwen to identify anomalies or summarize the key issues. The model’s understanding of code and structured text allows it to interpret logs or JSON records and output an analysis (e.g., “the error is caused by X at timestamp Y”) or even suggest fixes. Another example is generating configuration files or SQL queries from natural language specifications – Qwen can translate a request like “Give me an SQL query to find all users who signed up in the last week” into a correct SQL statement. In enterprise workflows, Qwen2.5-Max can serve as a dynamic automation engine: you provide instructions and context, and it produces output that can be directly executed or fed into other systems. Crucially, its ability to follow structured instructions (like “Output the result as a JSON with fields A, B, C”) ensures that the output can be parsed by downstream tools in an automated pipeline. This opens up possibilities for low-code or no-code automation, where non-technical descriptions are converted by Qwen into actionable scripts or configurations.
Code Understanding and Generation: Software developers and ML engineers can benefit greatly from Qwen2.5-Max’s strong coding capabilities. The model can function as an AI pair programmer – generating code in languages like Python, Java, JavaScript, C++, etc., given a natural language description of the requirements. It was trained on a large corpus of code and demonstrates top-tier performance on coding benchmarks (for example, Qwen2.5-72B-Instruct scores 88.2 on MBPP and 75.1 on MultiPL-E, significantly above its predecessor). In practical use, you can ask Qwen to “write a function that does X” or even “refactor this code to improve efficiency,” and it will produce remarkably good code. It also supports code comprehension: you can paste a block of code and ask Qwen to explain it line-by-line, or ask it to find bugs. Because of its reasoning ability, it doesn’t just regurgitate common patterns – it can adapt and even debug. A workflow might involve the model writing code, you running it and getting an error, and then showing the error to Qwen – often, it can analyze the error and correct its code accordingly. Qwen2.5-Max also formats code outputs well (typically wrapping code in markdown for easy reading). For developers, this means faster prototyping and debugging, and for organizations it means potentially integrating Qwen as a coding assistant in IDEs or as part of continuous integration (for automated code review or documentation generation).
Technical Documentation and Report Generation: Qwen2.5-Max can act as a knowledgeable technical writer or analyst. Given source content (like code with comments, API descriptions, design diagrams in text form, or raw analytics data), it can produce well-structured documentation or reports. For example, a team could supply an outline of a software module or a list of API endpoints, and ask Qwen to generate a user guide or API documentation. The model will expand terse descriptions into full paragraphs, create examples, and organize it into sections (it’s adept at structuring output when instructed). It understands formats like Markdown, reStructuredText, etc., and will consistently apply them if you specify (e.g., “Document this code in Markdown format with headers for each function”). Similarly, Qwen can generate business reports: feed it bullet-point findings from different departments and ask for a coherent summary report, and it will produce a draft narrative that an analyst can then refine. Because it handles long input, you can provide a large amount of reference information (multiple tables of data or a lengthy meeting transcript) and get a comprehensive summary or analysis. The fact that Qwen2.5-Max was fine-tuned to produce structured outputs (lists, JSON, etc.) when asked gives it an edge in generating clean documents that adhere to a requested format. This can save professionals significant time in drafting and compiling documentation or reports.
In all these use cases, a common thread is that Qwen2.5-Max serves as a force multiplier: it can take on complex, labor-intensive cognitive tasks (like reading huge volumes of text, planning multi-step solutions, or writing boilerplate code/docs) and execute them much faster than a human, while still allowing human experts to guide and verify the process. Its versatility across domains means the same model can be used in diverse departments (one team might use it for coding, another for customer support, another for data analysis), simplifying the AI toolchain an enterprise needs to maintain.
Python Integration Examples
Qwen2.5-Max is accessible through the Hugging Face Transformers library (for the smaller open-source variants) as well as via cloud API. For local experimentation, you can load one of the open Qwen2.5 models and use it like any standard transformers model. Below, we demonstrate a few common operations using a Qwen2.5 instruction-tuned model.
(In these examples we use the 7B parameter open model Qwen/Qwen2.5-7B-Instruct for illustration, which has the same interface and behavior format-wise as Qwen2.5-Max. The full Qwen2.5-Max is currently available only via the cloud API – we’ll cover that next – but the integration principles remain the same.)
Basic Text Generation with Hugging Face Transformers
In this snippet, we load a Qwen2.5 instruct model and generate a completion for a simple prompt:
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load a Qwen2.5 instruct model (7B parameters)
model_name = "Qwen/Qwen2.5-7B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
# Prepare a prompt
prompt = "Explain what a 'mixture-of-experts' model is in simple terms."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
When executed, this will download and load the model (which may be a large file, so expect a delay on first load), then print out the model’s answer to the prompt. We use device_map="auto" to automatically allocate the model on available GPU(s) (falling back to CPU if none) – this helps with memory management especially for larger models. In the above example, after generation, the response variable would contain a paragraph explaining MoE models in plain language. You can then work with this string in your code.
Processing Long Inputs (Summarization Example)
This example shows how you might use Qwen2.5 to summarize a long document. We read text from a file and include it in the prompt for summarization:
# Assume 'annual_report.txt' is a very large text file (e.g., thousands of words)
with open("annual_report.txt", "r") as f:
long_text = f.read()
prompt = "Summarize the key points of the following report:\n" + long_text
# Tokenize with truncation to fit the model's maximum input size (e.g., 8192 tokens for 7B model)
inputs = tokenizer(prompt, return_tensors="pt", truncation=True, max_length=8192).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=300)
summary = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(summary)
Here we simply concatenate the long document to the prompt with a clear instruction: “Summarize the following report.” The tokenizer’s truncation=True ensures we don’t exceed the model’s context limit (we set max_length=8192 for the 7B model in this example – Qwen2.5-7B supports up to 8K tokens by default; for Qwen2.5-Max you could set this higher, up to its 32K limit). The model will then output a summary of the lengthy text. We limited max_new_tokens to 300 to keep the summary concise. The final summary string contains the condensed version of the report, which you could further post-process or directly return to a user.
Note: For extremely large documents approaching the model’s context size, you might want to break them into chunks and summarize or analyze in parts (then possibly combine those summaries). Even though models like Qwen2.5-Max can handle very long input, feeding, say, 30k tokens at once can be slow. A strategy is to summarize each section of a long document and then have the model summarize the summaries.
Structured Output (JSON) Example
One very useful aspect of Qwen2.5 is its ability to produce structured outputs on demand. If you ask it for a specific format (like JSON, XML, markdown, etc.), it will usually comply exactly with that format. This is powerful for creating outputs that can be parsed by programs. In the snippet below, we prompt the model to extract structured data (product names and prices) from an unstructured text, and then we parse the model’s output using Python’s JSON library:
import json
text = "Product: ABC, Price: $123\nProduct: XYZ, Price: $87"
prompt = f"Extract product names and prices from the following text and output as JSON:\n{text}"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=100)
result_str = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result_str)
# e.g., result_str might look like: [{"product": "ABC", "price": 123}, {"product": "XYZ", "price": 87}]
data = json.loads(result_str)
print(data[0]["product"], "->", data[0]["price"])
In the printed result_str, you should get a JSON array of objects extracted from the text. The model is quite good at including exactly the requested fields and using proper JSON syntax. In our example output above, notice it dropped the dollar signs and returned prices as numbers – a nice touch. We then use json.loads to parse the string into a Python list of dictionaries (data), which we can easily work with (e.g., here we print the first product name and price).
This demonstration shows how Qwen2.5-Max can be instructed to act as a structured data extractor. You could similarly ask for XML, CSV, markdown tables, etc., and parse those outputs. The reliability in following the format means less cleanup code on your side. Of course, always validate the output from the model – e.g., use a try/except around json.loads in case the format isn’t 100% correct – but in practice Qwen’s structured output compliance is among the best in class.
Using the Qwen2.5-Max API
For production or larger-scale use, you will likely interact with Qwen2.5-Max via its REST API hosted on Alibaba Cloud. The API is designed to be OpenAI-compatible, meaning it uses the same request/response schema as OpenAI’s ChatGPT API. Once you have an API key (obtained from Alibaba Cloud’s Model Studio console after enabling the service), you can call Qwen2.5-Max just like you would call an OpenAI model. The endpoint URL for international regions is:
https://dashscope-intl.aliyuncs.com/compatible-mode/v1/chat/completions
And the model identifier for Qwen2.5-Max (as of the January 25, 2025 snapshot) is "qwen-max-2025-01-25". (You can also use the alias "qwen-max-latest" to automatically use the newest version if it gets updated.)
Below is an example using Python’s requests library. We send a chat-style prompt with a system message and a user question, and then print out the assistant’s reply:
import requests, os
API_URL = "https://dashscope-intl.aliyuncs.com/compatible-mode/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer " + os.getenv("QWEN_API_KEY")
}
payload = {
"model": "qwen-max-2025-01-25",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Which number is larger, 9.11 or 9.8?"}
]
}
resp = requests.post(API_URL, json=payload, headers=headers)
result = resp.json()
print(result["choices"][0]["message"]["content"])
In this request, we pass the model name and a list of messages following the usual chat format (a system instruction followed by a user query). The response will be a JSON object with a structure equivalent to OpenAI’s API. For example, result["choices"][0]["message"]["content"] contains the assistant’s answer to the user’s question. In this case, the model should respond with something like: “9.11 is larger than 9.8.”
Because the API is OpenAI-compatible, you could alternatively use OpenAI’s official Python SDK to call it – simply set openai.api_base to the Alibaba Cloud endpoint and use your Qwen API key. The rest of the code (creating a ChatCompletion with the model name and messages) would be identical to how you call OpenAI’s models. This makes integration into existing applications straightforward: in many cases, you can swap in Qwen2.5-Max with minimal code changes if you’re already using an OpenAI API client.
Deployment note: The Qwen2.5-Max API is a fully managed service. It handles the heavy lifting of running the 325B-parameter model on clusters of GPUs, so you don’t need to manage any infrastructure or model optimization. You send your requests and receive model outputs as shown above. Alibaba Cloud’s service provides scaling and reliability (with default rate limits that can be increased for enterprise customers) suitable for production use. If data privacy or residency is a concern, note that requests will be processed on Alibaba’s cloud – for highly sensitive data, some organizations might choose to use the open-source Qwen models on their own servers instead. But for most cases, using the API is the quickest way to leverage Qwen2.5-Max’s full capabilities in your product.
Prompt Engineering Best Practices
To get the most out of Qwen2.5-Max, here are some prompting tips and best practices, especially relevant when building applications:
Utilize the system role for context/setup: When using the chat format, include a concise system message to establish context, persona, or high-level instructions for the model. For example: “You are an expert cybersecurity analyst.” or “You are a helpful assistant that speaks in bullet points.” Qwen2.5-Max is tuned to respect system-level directives and can adapt its style or behavior accordingly. By clearly setting expectations up front, you ensure the model’s answers align with the desired role (be it a friendly customer service agent, a formal report generator, an empathetic tutor, etc.). The system message is a powerful way to steer the model’s behavior globally.
Be explicit about output format: If you need the answer in a particular structure or style, state that clearly in the prompt. Qwen2.5-Max generally follows formatting instructions very well. For instance, if you ask, “List the findings in a bulleted list,” it will produce a bullet list. Likewise, to get JSON output, you can say, “Respond with a JSON object containing …” As we saw, the model can produce valid JSON or Markdown when asked, without extra text. By explicitly specifying the format (and any example if needed), you greatly reduce the need for manual post-processing of the model’s output.
Encourage step-by-step reasoning for complex queries: If you want the model to show its reasoning or tackle a complex problem systematically, you can prompt it with “Let’s think step by step,” “Show your reasoning before answering,” or a similar instruction. Qwen2.5-Max will then often produce a chain-of-thought explanation, followed by the final answer. This can be useful during development or debugging of prompts – seeing the model’s intermediate reasoning can tell you if it’s on the right track. Even if you don’t want the reasoning in the final output, guiding the model to think through the problem internally can lead to more accurate answers. (You can instruct it to output the reasoning and answer separately, or just to itself – though by default it won’t hide reasoning unless using a special format.)
Leverage few-shot examples: With Qwen2.5-Max’s large context window, you have the luxury of providing examples in your prompt. If you have a very specific task or format, it often pays to show one or two examples of the desired Q&A or input/output behavior in the prompt (few-shot learning). For instance: “Q: [example question]\nA: [example answer]\nQ: [your question]\nA:”. The model will infer the pattern from the examples. Because you can fit a lot in the prompt, you don’t have to worry as much about saving every token – focus on making the example(s) clear and representative. Few-shot prompting can dramatically improve performance on niche tasks without any actual fine-tuning.
Control verbosity and style via instructions: Qwen2.5-Max is quite responsive to instructions about the tone, length, and style of the output. Use this to your advantage. If the answer is too verbose, you can add “Keep the answer brief.” If you need a more narrative style, say “Answer in a storytelling manner, with rich details.” The model will attempt to match the requested style. This works for technical tone vs. casual tone, first-person vs. third-person, etc. Being explicit about style in the prompt is better than expecting the model to guess. Also, if the model is giving unwanted extra information, refine the prompt to explicitly forbid that (e.g., “Answer only with the data asked, no additional commentary.”).
Remember the knowledge cutoff: Like all LLMs, Qwen2.5-Max has a knowledge cutoff (it won’t know events or facts beyond what was in its training data). If you ask about something very recent (past its training date) without providing context, it might make up an answer or say it doesn’t know. For production systems, consider using a retrieval step for any query that might require up-to-date information, and feed those results to Qwen in the prompt. If you manually know something is beyond its knowledge, either inform the model in the prompt or handle that case in your application logic. For example, you can prompt: “As of 2025, [provide updated info]. Given that, answer the question…” to update its context.
Iterate and refine prompts: Prompt engineering often requires a few tries to get perfect output. Qwen2.5-Max is quite advanced and forgiving, but you may still find edge cases where a prompt produces suboptimal output. Don’t hesitate to refine the wording or add clarifications. Even swapping a single word (e.g., using “explain” vs “describe”) or changing the order of sentences in your prompt can sometimes yield a better response. During development, it’s useful to test prompts interactively (for example, in the Qwen Chat web UI or a Jupyter notebook) to see how the model responds, then iteratively adjust. The good news is Qwen’s consistency means once you find a prompt formulation that works, it tends to keep working across similar inputs.
Following these practices will help you harness Qwen2.5-Max’s full potential. The model is highly capable and usually doesn’t require excessive prompt tweaking for straightforward tasks – thanks to its training, it often does the right thing with simple instructions. But for complex or high-stakes tasks, careful prompt design and testing can make a noticeable difference in quality and reliability of outputs.
Performance Considerations
Deploying a model as powerful as Qwen2.5-Max requires some planning regarding compute resources, latency, and cost. Here are a few points to keep in mind:
Inference speed and throughput: As an extremely large model, Qwen2.5-Max does not generate responses instantly. The cloud API is backed by clusters of GPUs to serve the model, but you should still expect higher latency than smaller models. For a moderately sized prompt and answer (say a few hundred tokens each), typical response time might be on the order of 1–3 seconds. If you use the maximum 32K context with a long input, initial processing will be heavy – essentially, the model has to read and encode all those tokens, which can take several seconds by itself. In practice, for full 32K-token prompts you might see response times in the tens of seconds. Keep this in mind when designing user-facing applications; you might need progress spinners or an asynchronous job approach for very large requests. The Qwen API supports streaming results, so you can start receiving tokens as they are generated (much like OpenAI’s streaming mode) – leveraging this can greatly improve perceived latency for end-users.
Memory and hardware (for self-hosting): If you plan to run any Qwen models on your own hardware, be aware of the memory footprint. The open 7B and 14B models are relatively easy to run on a single modern GPU (and even on CPU with enough RAM, albeit slowly). The 32B and 72B models are much heavier – typically requiring multiple GPUs or an 80GB A100 GPU for full 16-bit loads (though 8-bit or 4-bit quantization can allow 72B to run on a single 48–80GB GPU at reduced precision). Qwen2.5-Max, at 325B with an MoE architecture, is not feasible to run on a single machine without a specialized multi-GPU setup (think 16+ GPUs in a server, or a TPU pod, etc.) – hence it’s offered through the managed API. If offline or on-premises deployment is needed, you’ll likely need to stick to the smaller open Qwen models. Fortunately, those models are state-of-the-art in their size class, so a 14B or 32B Qwen2.5 model can still do a lot. Alibaba has also released many quantized versions (int8, int4) of the open models for efficiency, which can significantly reduce memory usage (sometimes allowing a 32B model to run on a single 16GB GPU, for example). Using these comes with a slight drop in precision, but often the impact on output quality is minor.
Scaling and batching: The Qwen API (and the underlying model) can handle batched requests – e.g., generating outputs for multiple prompts in parallel – but keep in mind that the token limit applies per request. Also, extremely large prompts will consume a lot of throughput. The API has a tiered pricing by context length (longer contexts cost more per token). It may be more efficient to process big jobs in smaller chunks when possible. On the other hand, the MoE design means Qwen2.5-Max doesn’t always use all experts for every token, so it can achieve better throughput than a dense model of equal parameter count. Still, it’s a heavy model, so consider your QPS (queries per second) requirements. If you need to handle many requests per second with low latency, you might use a mix of model sizes (for example, use a 7B or 14B model for simple/short requests and only send complex ones to Qwen2.5-Max). Also note that rate limits on the API might throttle extremely high request volumes – these can usually be raised by contacting Alibaba if needed.
Cost optimization: Using Qwen2.5-Max via the API incurs a cost per token (both input and output). This can add up with long prompts or verbose outputs. Some ways to optimize cost:
Minimize unnecessary tokens: e.g., don’t send superfluous context or overly lengthy system prompts if not needed. Every token you send or generate is billed.Adjust output length: If you only need a brief answer, set a max_tokens limit or instruct the model to be concise. Conversely, avoid asking for an essay when a short answer suffices.
Leverage open models when suitable: As mentioned, you might route simpler queries to a local Qwen2.5-7B/14B model which has no usage cost, and reserve Qwen2.5-Max for cases that truly need its prowess. This kind of routing logic can significantly cut costs while maintaining overall quality.
Use caching of results: For repeated or similar queries (especially analytical ones), consider caching model outputs. If the same question is asked again, you can return the cached answer instead of calling the API again.The bottom line is, Qwen2.5-Max gives state-of-the-art quality but is expensive; prudent use of context and selective deployment can keep the ROI favorable.
Reliability and monitoring: The Qwen2.5-Max service is stable, but as with any external API, you should implement error handling. For example, handle cases where the API might return an error or a timeout. Also, monitor the content of the model’s outputs for any compliance issues or errors (especially in early stages of deployment). Even with alignment, it’s good practice to keep logs of model responses (perhaps with user consent as needed) so you can review them for quality and safety. In an enterprise setting, you might run additional filters on the model’s output to catch any disallowed content (as a second line of defense). And if you’re piping model outputs into automated processes, be extra sure to validate them – e.g., if the model is generating database queries, have a sandbox or verification step before execution.
In summary, Qwen2.5-Max brings unprecedented capabilities but also demands significant resources. Using the managed API offloads the infrastructure burden to Alibaba, yet you as the developer should still optimize how and when you call the model. With careful planning – like streaming large outputs, mixing model sizes, or batching requests – you can deliver a smooth and cost-effective user experience while harnessing Qwen2.5-Max’s full power.
Deployment Options
Depending on your requirements, there are several ways to deploy or integrate Qwen2.5 models into your environment:
Alibaba Cloud Model Studio (Managed API): This is the primary way to access Qwen2.5-Max and related models. Using the cloud API (as illustrated above), you get a fully managed experience – no need to worry about provisioning GPUs, loading model weights, or updating to new versions. This option is ideal if you want to quickly integrate the model into an application and are comfortable with a cloud-hosted solution. The service is robust and scalable for enterprise workloads. Notably, Alibaba Cloud also offers other Qwen variants via the same API. For example, Qwen2.5-Plus and Qwen2.5-Turbo are two MoE variants with different parameter scales that are available for use (these are essentially slightly smaller or optimized models that trade off a bit of quality for lower cost or latency). You can select these by specifying their model names in the API. In short, Model Studio lets you treat Qwen2.5-Max as a typical cloud AI service – it’s the simplest path to production deployment, with enterprise support and SLAs available from Alibaba.
Self-Hosting Open Models: Alibaba has open-sourced a range of Qwen2.5 models (with permissible licenses) from 0.5B up to 72B parameters. These include both base (pretrained) models and instruction-tuned models. If your use case or policy demands that no data be sent to an external service, you can opt to deploy one of these models on your own infrastructure. For instance, the Qwen2.5-7B or 14B models can often be run on a single modern GPU (or even on CPU for 7B, using optimized libraries – albeit slowly). The larger 32B and 72B models may require multi-GPU setups or high-memory accelerators. Self-hosting gives you full control: you manage the model weights and the inference pipeline, which means you can ensure data privacy (all inputs stay on your servers), and you can fine-tune these models on your proprietary data if needed. The open models are under Apache 2.0 or similar licenses for the most part, meaning you can use them in commercial products. Keep in mind that Qwen2.5-72B (the largest open one) is extremely powerful – in many benchmarks it’s competitive with some proprietary models well above 100B in size. So, depending on your needs, an open 72B (or a quantized 72B) might suffice without going to the full 325B Max. Many organizations start prototyping with the open models locally, and only call the Max model via API for the most challenging cases.
Hybrid Approaches: You can combine cloud and local deployment to balance performance, cost, and privacy. For example, you might run an on-premises Qwen2.5-14B model for handling sensitive queries entirely in-house, but route more complex queries to the Qwen2.5-Max API to get the best quality. Since the Qwen family models share similar behavior and output style, this hybrid setup can be made seamless to users. Another scenario is using a local smaller model as a fallback if the API is unreachable or if a query exceeds your cost threshold. Qwen’s uniform API and prompt format across variants make it straightforward to switch between model sizes when needed. This approach lets you optimize costs and compliance dynamically – e.g., use the free local model 90% of the time and pay for the API 10% of the time when you really need it.
Community and Third-Party Platforms: Because of Qwen’s open availability (in smaller forms), it’s also supported on various AI platforms and by the community. For example, you’ll find Qwen models on Hugging Face Hub (under the Qwen organization) and they can be deployed with Hugging Face’s Text Generation Inference server or other OSS deployment tools. There are community web UIs (similar to Stable Diffusion’s web UIs) that support Qwen – these can be used for quick demos or internal tools. Additionally, companies like Hugging Face, AWS, etc., might host Qwen2.5 models as part of their managed offerings (for instance, HF Inference Endpoint or Amazon Bedrock might integrate Qwen if not already). Keep an eye on official announcements – the ecosystem around Qwen is growing. The bottom line is, flexibility: you’re not locked into a single way to use Qwen. You can pick the deployment strategy that fits your technical and business needs.
To summarize deployment choices: if you need the absolute highest quality and a plug-and-play solution, the cloud API for Qwen2.5-Max is the best choice. If you have constraints that require keeping everything in-house (or want to avoid token-based costs), the open-source Qwen2.5 models give you a spectrum of options to run locally. Many enterprises might start with the API for convenience and fast iteration, then move to a hybrid or on-prem setup as they scale and productize their solution. The availability of both routes is a major advantage of Qwen – you have a path to gradual adoption, starting from experimentation all the way to scaled deployment, all within the Qwen family.
Current Limitations and Considerations
While Qwen2.5-Max is a cutting-edge model, it’s important to be aware of its limitations and operate with best practices to mitigate them:
Knowledge Cutoff: The model’s training data has a cutoff (likely in 2024 for most content, given the release date). It will not be aware of events, facts, or developments after that cutoff. For example, if asked about a news event from early 2025 that wasn’t in the training data, Qwen2.5-Max might either guess or respond that it doesn’t have information. In production use, this means for any query about recent or real-time information, you should provide that information via context (or use a retrieval mechanism to fetch it). Relying on the model’s internal knowledge alone for up-to-date queries will lead to incorrect or outdated answers.
Hallucinations and Accuracy: Like all large language models, Qwen2.5-Max can sometimes “hallucinate” – i.e., produce factual-sounding statements that are incorrect or entirely fabricated. While its training and RLHF have reduced this tendency (especially when it has relevant context), it is not 100% reliable on factual accuracy. Critical information should be verified by an independent source. When using Qwen for tasks like medical or legal Q&A, it’s advisable to have a human expert in the loop or to constrain the model to provided reference texts. The retrieval-augmented approach can help here: by giving the model sources to draw from, you anchor its answers. But even then, always verify important outputs from the model.
Overconfidence and Subtle Errors: Qwen2.5-Max, by design, often provides answers in a very confident and articulate manner. This is great for user experience, but it also means that when it’s wrong, it may not show much uncertainty. It can make subtle errors (e.g., a slight logical mistake in a long reasoning chain, an off-by-one error in code, a mistranslation of a rare idiom) that are hard to catch without careful review. Users might take its output at face value due to the fluent delivery. To mitigate, consider instructing the model to show reasoning or evidence for critical answers (so that a user or system can double-check them). For coding, always run tests; for math, double-check results with a calculator if possible; for generated content, possibly use another AI or tool to cross-verify key details.
Instruction Adherence vs. Creativity: Qwen2.5-Max has been fine-tuned heavily to follow user instructions and produce relevant, on-point answers. Generally, this is a positive – it means it tries to do exactly what you ask. However, this also means it might be more literal and less “creative” by default than some models in open-ended tasks. For example, if asked to write a story, it will do a good job, but it might stick closely to common tropes or the explicit constraints given, rather than going on wild imaginative tangents. This is usually desirable in enterprise use. But if you want more creativity or randomness, you might need to adjust generation settings (increase temperature, etc.) or explicitly encourage creativity in the prompt. It’s a tunable aspect. Conversely, if you need a very deterministic response (e.g., in a structured format), keep the temperature low and instructions clear – Qwen will generally comply consistently.
Refusal and Content Filters: Qwen2.5-Max has undergone safety training to avoid producing harmful or disallowed content. If a user asks for something clearly against guidelines (extreme hate speech, instructions for wrongdoing, etc.), the model will refuse or respond with a safe completion. In edge cases, it might err on the side of caution – for instance, refusing a request because it might interpret it as disallowed, even if the user had a benign intent. As a developer, be prepared to handle cases where the model responds with a refusal (e.g., a message like “I’m sorry, but I cannot assist with that request”). You might need to rephrase the user’s query or clarify it wasn’t meant to be harmful. Also, note that the public demo (Qwen Chat) may have additional filters that cause disconnections on certain content; the API itself will typically return a polite refusal rather than dropping the connection. The key point: the model will not output certain categories of content, and that’s by design. Make sure this aligns with your use case and provide user guidance if necessary (for example, a usage policy or a note saying the assistant can’t help with certain requests).
Biases: Despite efforts to reduce biases, Qwen2.5-Max, like all LLMs, inherits biases from its training data. This can manifest in subtle ways – e.g., making stereotypical assumptions, or the tone it uses for different demographics or topics. It’s been aligned to avoid blatant issues, but one should be mindful of potential biases, especially in sensitive applications. For example, when generating content about different cultures, genders, or groups, consider prompting it to be respectful and unbiased, or have a review mechanism. If your application domain is sensitive to these concerns (like hiring, admissions, etc.), thorough testing is required. The Apache 2.0 license of smaller Qwen models allows further fine-tuning, so one could fine-tune on a bias-reduction dataset if needed for a specific domain.
Long Context Pitfalls: While Qwen2.5-Max can handle very long contexts, it doesn’t magically solve all issues of long text understanding. The model still has to summarize and prioritize information internally. If you give it a 30-page document and ask a question, it might miss a relevant detail if that detail was very subtle or if the question doesn’t clearly hint at its relevance. Also, very large contexts can introduce a lot of information – sometimes irrelevant – which could confuse the model or dilute its focus. Best practice is to provide well-chosen context. If you feed it entire books, be specific in your question about what to look for, otherwise you get a very general answer. Additionally, extremely large prompts increase the chance of glitches (like earlier parts of the prompt influencing later parts in unexpected ways or the model running out of “attention” for later content if not handled well). Empirically, Qwen2.5 models handle up to 128K context with specially trained versions, but beyond a certain length, you might see diminishing returns. So use the long context ability wisely; it’s powerful, but not infallible.
By keeping these limitations in mind, developers can design their systems to compensate or guard against them. For example, you can integrate verification steps (like have a second model or a set of rules check the first model’s output), use user feedback to catch hallucinations, or break down complex tasks so the model has a better chance of getting each part right. The good news is that Qwen2.5-Max’s combination of size and fine-tuning has mitigated many common issues – it’s more grounded and reliable than smaller or older models – but it’s not perfect. Treat it as a very knowledgeable and skilled assistant, but one that can make mistakes or need guidance, especially on the frontiers of its knowledge.
Frequently Asked Questions (FAQs)
How can I access Qwen2.5-Max right now?
Are the Qwen2.5-Max model weights open-source? Can I self-host it?
What is the context window of Qwen2.5-Max?
What format should prompts be in? Do I always have to use the chat message format?
messages: [ {...}, {...} ]. Even when using the open-source models directly, it’s recommended to format your prompts similarly (there’s a utility to apply the chat template in the Qwen repository). That said, if you use the instruct-tuned open models in transformers, you can often get away with a single plain text prompt (it will assume it’s the user prompt). But the safest approach is: provide a system message for any global instructions or context, then provide the user query. The assistant role will be generated by the model. This structure helps the model understand what part is user input vs. prior context, etc. It also lets you easily add system-level behavior guidelines. So in summary: use the <system>, <user>, <assistant> message paradigm – that’s how Qwen is designed to be used (very much like OpenAI’s chat models).What programming languages does Qwen2.5-Max support for code generation and analysis?
Can I fine-tune Qwen2.5-Max on my own data or instructions?
Does Qwen2.5-Max have multimodal capabilities (vision, audio, etc.) or is it purely text-based?
We introduced Qwen2.5-Max as a powerful general-purpose LLM and covered its architecture, reasoning skills, long context, multilingual support, and integration tips with comprehensive technical depth.
This should equip you to evaluate Qwen2.5-Max for your needs and integrate it effectively into your applications, especially if you’re an AI engineer, developer, or researcher looking for advanced language model solutions.