
Qwen2-VL is Alibaba’s next-generation multimodal large language model that combines vision and language understanding. As an advanced Qwen vision model, it can accept both text and visual inputs (images – and even videos – alongside prompts) and generate detailed textual responses. This model is the successor to the original Qwen-VL and brings significant improvements in image understanding and multilingual OCR, extended video analysis, and even the ability to act as an “agent” by interpreting visual scenes and executing commands.
Qwen2-VL was open-sourced in 2024 with 7B and 2B parameter versions available under Apache 2.0 (suitable for self-hosting), while a powerful 72B version is offered via API. This deep dive will explore Qwen2-VL’s high-level architecture, supported input types, core capabilities, developer workflows, integration examples in Python (Transformers and vLLM), real use cases, performance considerations, and more – providing a comprehensive guide for engineers and researchers building multimodal applications.
Architecture Overview of Qwen2-VL
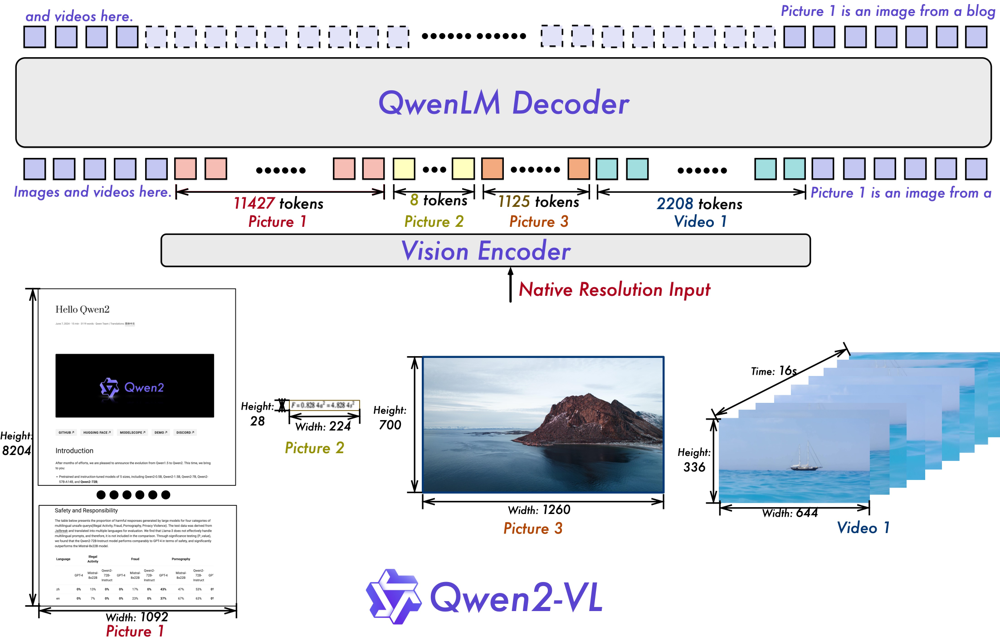
At its core, Qwen2-VL follows a typical encoder–decoder vision-language architecture: a dedicated vision encoder extracts visual features which are then fed into a large language model (the Qwen2 LLM) that generates the textual output. The vision encoder is a 600-million-parameter Vision Transformer (ViT) that has been fine-tuned from scratch (not a frozen CLIP encoder) to handle both image and video inputs. The text decoder is based on the Qwen2 LLM (available in 2B, 7B, or 72B parameter scales), which attends to both textual and visual tokens to produce coherent responses.
Key architectural innovations in Qwen2-VL include:
- Naive Dynamic Resolution (NDR): Unlike many vision-language models that require resizing images to a fixed resolution (e.g. 224×224), Qwen2-VL can handle arbitrary image resolutions by mapping each image into a dynamic number of visual tokens. In practice, this means a large, high-detail image will produce more patch tokens than a small image, preserving information that would be lost by downsampling. This dynamic tokenization ensures the model input reflects the true content of the image at native clarity, enabling human-like perception of both small and large images. For example, an extremely tall document image might yield thousands of tokens, whereas a thumbnail yields just a handful – Qwen2-VL can flexibly accommodate both.
- Multimodal Rotary Position Embedding (M-ROPE): Qwen2-VL introduces an extended positional encoding scheme to handle visual and temporal dimensions. Standard Transformers use 1D RoPE for token positions; Qwen2-VL’s M-ROPE splits position embeddings into three components (for text sequence, image height×width grid, and video time frames). This allows the model to concurrently capture 1D textual order, 2D spatial locations within an image, and 3D spatiotemporal positions for video frames. In effect, the model better understands where an object is in an image and when in a video sequence an event happens, improving coherence for video and multi-image inputs.
Under the hood, images or video frames are encoded as patches (with an adaptive number of patches due to NDR) and then projected into token embeddings. These visual tokens are concatenated with text tokens and processed by the Qwen2 decoder’s self-attention layers, enabling cross-modal interactions. This architecture enables multi-image and video support in a unified manner – multiple images can be provided in a single prompt (each image yielding its own set of tokens), and video is essentially treated as a series of image frames with temporal order preserved by M-ROPE. The unified design keeps the pipeline simple: whether it’s one image, a batch of images, or a long video, the model encodes them through the same vision transformer and feeds the tokens into the LLM for joint reasoning.
Supported context lengths: The Qwen2 text decoder supports large context windows for combining long textual prompts with visual inputs. In practice, Qwen2-VL can handle at least 8K tokens of text (and in newer Qwen2.5 versions, up to 32K or more), which is plenty for detailed image descriptions or multi-turn dialogues. Each image contributes visual tokens (the model allows between 4 and 16,384 visual tokens per image by default), meaning extremely high-resolution images (millions of pixels) are supported. Videos are processed frame-by-frame up to substantial lengths – the Qwen team demonstrated understanding of videos over 20 minutes long.
There is a practical file size limit around 150 MB per video, and frames are downsampled if needed to about 600k pixels each for efficient processing. Accepted image formats include standard types like PNG or JPEG (and common video file formats such as MP4, AVI, MKV, etc., via the vision encoder). The open-source 7B and 2B models readily support single images or multi-image prompts out-of-the-box, while video support may require using the 72B model via API or custom pipelines (as of late 2024, the open 7B model can technically handle video frames, but deploying full video QA may need further engineering).
In summary, the architecture of this multimodal LLM (Qwen2-VL) allows a flexible intake of visual information at high fidelity, fused with text, all processed by a powerful decoder model. Next, let’s explore what capabilities this design unlocks.
Core Multimodal Capabilities
Thanks to its robust architecture and training, Qwen2-VL demonstrates a wide range of vision-language capabilities. The model achieves state-of-the-art performance across many benchmark tasks, from reading documents to answering complex visual questions. Here are the core capabilities:
Image Understanding and Captioning: Qwen2-VL can analyze an image in detail and produce a descriptive caption or summary. It recognizes objects, scenery, people, and other elements in images with high accuracy. It goes beyond simple one-sentence captions – the model can generate rich, context-aware descriptions. For instance, given a photo, it can not only name visible objects but also describe their relationships or actions. It even excelled at multi-object scenes: an example from the Qwen team shows it identifying a stack of colored blocks with numbers, listing each block’s color and number in order. This indicates the model’s ability to both detect multiple objects and organize information clearly.
Visual Question Answering (VQA): The model can answer questions about an image. You can ask things like “What is happening in this picture?”, “How many people are in the photo?”, or “What is the color of the car?” and Qwen2-VL will analyze the image to provide an answer. It handles complex reasoning on images, not just factual identification. For example, it can infer relationships (“Is the person happy or sad?”), count objects, and solve visual puzzles. The Qwen2-VL technical report notes improved visual reasoning for real-world problems – it can even solve math or logic questions presented in images, such as geometry problems on a diagram or analyzing data from a chart. This indicates Qwen2-VL’s blend of vision with general reasoning (leveraging the LLM’s strengths). The model’s enhanced reasoning is evident in tasks like chart analysis – it can interpret charts/graphs and extract insights, and in solving multi-step problems like reading a diagram and performing calculations.
OCR and Document Comprehension: One of Qwen2-VL’s standout strengths is reading and interpreting text within images. It has multilingual OCR capability that covers English, Chinese, and most European languages, as well as Japanese, Korean, Arabic, Vietnamese, and more. It also improved significantly on handwritten text recognition. This means you can feed it a picture of a document, a form, a screenshot of a webpage, or even a photo of handwriting, and Qwen2-VL can extract and reason about the text. It achieved state-of-the-art on benchmarks like DocVQA (document visual QA). The model can answer questions about a document image or even convert an image of text into another format. For example, given an image containing dense mathematical formulas, Qwen2-VL successfully converted the content into Markdown (retaining the LaTeX equations) – showcasing precise parsing of complex printed text. It can also return structured data from images: another demo had the model read a screenshot of Linux kernel version info and output a JSON list of versions and release dates. Similarly, it can create tables from an image with tabular data (e.g. extracting a weather chart into a neat table). These examples show that Qwen2-VL isn’t just doing raw OCR, but understanding and organizing the extracted text according to instructions.
Multilingual Image-Text Reasoning: Since Qwen2-VL supports multiple languages in images, you can ask questions or get answers across languages. For example, it can read Chinese text in an image and then answer a question about it in English, effectively translating and explaining. The model topped the MTVQA benchmark (Multilingual Text+Vision QA) with strong performance. This is valuable for global applications – e.g., analyzing a French document and responding in English. The training included diverse languages, so Qwen2-VL can be used for cross-lingual visual tasks out-of-the-box.
Video Understanding and Temporal Reasoning: Extending image capabilities to video, Qwen2-VL can process video clips (as a sequence of frames) and answer questions or summarize content. It was designed so that even the 7B model retains video comprehension abilities. For example, you could give it a video and ask “What happens in this video?” or “Describe the events between 10s and 20s.” The model will analyze frames and form a coherent narrative. A demo in the Qwen blog shows Qwen2-VL summarizing a space station video in detail, then answering follow-up questions about specifics (like the color of the astronauts’ clothes). Impressively, Qwen2-VL can maintain context across a video and a multi-turn conversation – essentially “chatting” about the video as it plays, as shown in an example where a user and Qwen2-VL discuss a video of someone cleaning a floor over multiple turns. This live video chat ability opens up use cases in surveillance analysis, media content understanding, or personal assistants that can watch videos with you. Note: In the current open release, video support might require the larger model (72B via API) as the 7B open model’s public demos focus mostly on image tasks. However, the underlying architecture is ready for video, and updates to tooling (e.g., in vLLM or Transformers) are bringing full video input support to developers.
Agent and Tool-Use Capabilities: An exciting aspect of Qwen2-VL is its agentic abilities. Because it can interpret visual inputs and has strong reasoning, it can serve as a vision-based AI assistant that not only describes what it sees but also decides on actions. The model supports function calling where it looks at an image (or video frame) and can trigger external tools or APIs based on instructions. For example, it could see an interface and call a function to click a button, or read a flight ticket image and call an API to check flight status. Qwen2-VL demonstrates UI understanding (looking at screenshots of a mobile phone or computer UI and operating them) – essentially performing tasks like a human looking at the screen would. The Qwen team showed examples of the model controlling a mobile phone interface, playing a game based on on-screen info, or even directing a robotic arm after “seeing” its camera feed. These abilities are early-stage but point towards visual-action agents: imagine giving Qwen2-VL a view from a robot and a command, and it generates a plan or directly calls control functions. In practical developer terms, this means Qwen2-VL can be integrated with tool APIs: e.g., feed it an image of a weather radar and let it call a weather API if needed, or show it a webpage screenshot and have it simulate clicking or data entry via function calls.
Complex Reasoning and Coding from Visual Inputs: Qwen2-VL has also been enhanced in tasks that combine vision with math or programming. It can solve math problems given in images (like geometry diagrams or algebra written out) by logically working through the steps. It can read code from an image (like a screenshot of code) and even generate new code in response – for instance, one example had it solve an algorithmic puzzle “Snake in a Matrix” by reading the problem from an image of a webpage and then outputting a step-by-step solution with actual Python code. This demonstrates that Qwen2-VL isn’t limited to passive description; it can produce tangible outputs (like code or calculations) grounded in visual input. For developers, this suggests you could present a diagram or a code snippet image to Qwen2-VL and get useful transformations (e.g., explain this code, fix the bug, implement the formula from the image, etc.).
In summary, Qwen2-VL is a general-purpose multimodal AI: from describing photos and answering visual questions, to reading documents, translating text in images, analyzing charts, summarizing videos, and interacting with visual environments. It sets a new state-of-the-art on many open benchmarks, often on par with or surpassing much larger proprietary models in specialized tasks (especially document understanding). Now, let’s explore some concrete use cases and how developers can leverage these capabilities in real scenarios.
Developer Use Cases and Applications
With its broad skillset, Qwen2-VL unlocks a range of practical applications for software developers, ML engineers, and enterprises looking to infuse vision intelligence into their products. Here we outline several high-impact use cases and how Qwen2-VL can be applied:
Document Understanding and Data Extraction
Qwen2-VL’s strong OCR and document reasoning make it ideal for document automation tasks. For example, a developer can build a service where users upload scanned documents (contracts, forms, invoices, handwritten notes) and Qwen2-VL parses them into structured text. The model can answer questions about a document (e.g., “Who is the recipient of this letter?” given an image of a letter) or convert an image of a table into CSV/JSON. It shines at tasks like DocVQA – answering queries based on PDFs or scans – and even handles multilingual documents and tricky cases like poor handwriting.
An enterprise could use Qwen2-VL to process historical archives, extract fields from forms (like IDs or receipts), or summarize lengthy reports that are only available as images. Because Qwen2-VL can output structured formats on request (as shown when it returned JSON from an image), developers can prompt it to directly give machine-readable outputs, making it easier to integrate into pipelines. This opens opportunities in RPA (Robotic Process Automation) and back-office automation, where a lot of information still comes in via scanned images or PDFs.
Multimodal Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation typically involves fetching relevant text from a knowledge base to help an LLM answer a question. With Qwen2-VL, we can extend RAG to the visual domain. Imagine a support chatbot where a user can send a picture (say, of a product or error screen) along with their question – Qwen2-VL could interpret the image, and meanwhile a retrieval system fetches relevant textual data (like product specs or troubleshooting guides). The model can then weave together the image understanding and the retrieved text to give a rich answer. For instance, a user asks “How do I fix this part?” with a photo of a broken appliance; Qwen2-VL identifies the part in the image and the RAG component provides repair manual text, resulting in a detailed step-by-step answer.
This image-grounded QA approach could greatly enhance customer support and knowledge bots. Another scenario: indexing a collection of technical diagrams or charts along with text descriptions – a query can trigger both text and image retrieval, and Qwen2-VL can synthesize information from both modalities. Essentially, Qwen2-VL enables a new kind of RAG where images are first-class citizens in the context window. Developers can implement this by encoding images and text as part of the prompt (for example, include a relevant figure image plus retrieved text paragraphs in the message content). Because Qwen2-VL can handle multiple images and lots of text, it’s well-suited to these compound informational tasks.
Chart and Data Visualization Analysis
In data-heavy fields, we often have charts, graphs, or tables as images that need interpretation. Qwen2-VL’s ability to do chart reasoning means it can look at a plot or bar chart and explain the key insights. A developer could feed a chart image to Qwen2-VL and prompt: “Explain this chart” – the model might respond with something like “This line chart shows sales over 12 months, with a peak in December and a drop in February…”. It can also extract specific data points from charts on request. Additionally, for tables in images, Qwen2-VL can read them and allow queries.
For example, show it a screenshot of an Excel table and ask “What was the highest value in the last column?”. This could be integrated into analytics dashboards or BI tools: whenever a user encounters a visual graph, Qwen2-VL can act as an on-demand analyst to summarize or answer natural language questions about the visualization. It reduces the friction of manually eyeballing charts for insights. The earlier example of converting a weather infographic to a table demonstrates how well it can organize visual data – think of applying that to financial charts, scientific plots, or UI dashboards.
E-commerce and Product Recognition
Qwen2-VL offers powerful capabilities for the e-commerce domain. It can serve as the engine behind visual search: a user can upload an image of a product they like (say a particular dress or gadget), and Qwen2-VL can identify the product or find similar items by generating descriptive attributes. Its object recognition is robust – beyond just labels, it understands colors, shapes, and relationships (e.g., it could look at a furniture image and describe style and material). Online retailers could use it to automate product tagging and captioning: Qwen2-VL can generate descriptive captions for product images, highlighting features and even inferring uses. These captions improve SEO and user engagement by providing rich, human-like descriptions instead of terse bullet points.
Moreover, with its multi-lingual abilities, the model can generate product descriptions in multiple languages easily, aiding international e-commerce. Another use is virtual try-on or fit assistants – a customer uploads a photo of themselves and an item, and Qwen2-VL could answer questions like “How would this jacket look with jeans?” or provide suggestions (this is speculative, but within the model’s ability to describe and compare). On the customer support side, as noted, visual QA can help resolve issues: customers can send a photo of a damaged product or an error message, and the model can analyze it and either give troubleshooting steps or route it appropriately. All told, Qwen2-VL can improve the product discovery and customer interaction in retail by making sense of image data automatically.
Interactive Assistants and Robotics
For teams working on robotics, AR, or any AI that needs to operate in the real world, Qwen2-VL can be a game-changer. Its visual agent capabilities mean it can form the “brain” of an assistant that sees and acts. For example, imagine smart glasses with a camera – Qwen2-VL could run on-device (using the 2B model for efficiency) to interpret what the wearer sees and whisper helpful info (like identifying landmarks, translating signs, or advising during tasks). In robotics, a robot equipped with a camera could feed frames to Qwen2-VL and get high-level interpretations (“I see an obstacle to the left, it looks like a chair”) and even decisions (“navigate around the chair”).
Because Qwen2-VL can follow instructions and combine them with visual input, developers can design prompt-based control schemes. The function-calling aspect is particularly useful: the model could decide when to call navigation or manipulation functions based on visual context. While still early, this technology hints at autonomous agents that use natural language to reason about visual scenes and execute code – effectively bridging vision, language, and action. Enterprise tech teams can also use this in less physical ways: e.g., an automated UI testing tool that visually scans an app interface and uses Qwen2-VL to decide where to click or how to fill forms, simulating a human tester.
These are just a few examples – virtually any scenario where understanding images or video is required can benefit from Qwen2-VL’s capabilities. Now that we’ve covered what it can do, let’s get practical and see how to use Qwen2-VL in code.
Python Quickstart: Using Qwen2-VL with Hugging Face Transformers
One of the advantages of Qwen2-VL is that the 2B and 7B models are openly available on Hugging Face, making it straightforward for developers to download and use them in Python. The model has been integrated into the Hugging Face Transformers library (you may need a recent version, as support was added in late 2024). Below is an example of loading the Qwen2-VL model and running a multimodal prompt.
First, install the required packages (from the terminal):
pip install git+https://github.com/huggingface/transformers # latest transformers for Qwen2-VL
pip install qwen-vl-utils # utility for processing image/video inputs
Now a Python example: we will load the 7B instruct-tuned Qwen2-VL model and ask it a question about an image. For demonstration, let’s say we have an image file "demo.png" that shows a bar chart, and we want to ask: “What is the highest bar in this chart?”.
from transformers import AutoProcessor, Qwen2VLForConditionalGeneration
from qwen_vl_utils import process_vision_info
# Load the Qwen2-VL model and processor
model = Qwen2VLForConditionalGeneration.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", device_map="auto")
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")
# Prepare the multimodal input message
image_path = "demo.png" # path to your image file (or use a URL)
user_prompt = "What is the highest bar in this chart?"
# The message content includes the image and the question text
messages = [
{"role": "user", "content": [
{"type": "image", "image": image_path},
{"type": "text", "text": user_prompt}
]}
]
# Process the message into model inputs
text_input = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=[text_input], images=image_inputs, videos=video_inputs, return_tensors="pt")
inputs = inputs.to(model.device) # move inputs to the same device as model
# Generate the answer
outputs = model.generate(**inputs, max_new_tokens=128)
answer = processor.batch_decode(outputs, skip_special_tokens=True)[0]
print("Model answer:", answer)
Let’s break down what’s happening in this code:
- We use
AutoProcessorandQwen2VLForConditionalGenerationto load the tokenizer/processor and the model. The instruct model is chat-optimized, meaning it expects a conversation format (with roles like"user"and content comprising text and images). We specifydevice_map="auto"to load across available GPUs (or CPU if none, though 7B model on CPU will be slow). Make sure you have enough GPU memory (the 7B model typically requires ~14GB in 16-bit; usingtorch_dtype=torch.bfloat16or 8-bit quantization can reduce memory). - We construct a
messageslist following Qwen’s input format: Each message is a dict with a role and a content list. The content list can mix images and text segments in order. Here we put one image followed by one text question, all as the user message. You could prepend a system message with instructions if desired (e.g., a role “system” with content like{"type": "text", "text": "You are a helpful vision assistant."}to guide the tone). - We then call
processor.apply_chat_templatewhich formats the text for the model (Qwen2-VL uses a special chat format under the hood).process_vision_infohandles loading the image and preparing it as tensors. The processor then tokenizes text and prepares the final tensors, including image pixel values, ready for the model. - We call
model.generateto produce an answer, then decode it back to text. The output in this case might be something like: “The highest bar in the chart is the one labeled 2023 with a value around 50.”, depending on the chart image content.
This example demonstrates a Qwen2-VL Python usage where we pass an image+question and get a textual answer – essentially Visual QA. We can easily adapt this for other tasks:
- Image captioning: Simply use a prompt like “Describe this image.” with the image.
- OCR extraction: e.g., “Read all the text in this image.” – Qwen2-VL will output the text it sees.
- Structured output: You can instruct the model to format the answer, e.g., “List the items in the image as JSON.” and it will attempt to follow suit (as shown in earlier examples).
- Multi-image: Include multiple
{"type": "image", ...}entries in the content list (and perhaps intermix with explanatory text). Qwen2-VL can handle multiple images – for instance, comparing two images or referencing one image’s content in relation to another. - Video (frames): If using the API or an environment that supports video input, you would include
{"type": "video", "video": video_path}similarly. In open-source usage, you might manually break a video into frames and supply a subset of important frames as multiple images for a summary task.
Note: Ensure you have the latest transformers version (the Qwen2-VL code was merged around late 2024, so older versions may not have the model code, yielding a KeyError: 'qwen2_vl'). Installing from source or a version >= 4.33 is recommended. Also install qwen-vl-utils as shown, which conveniently handles various input types (base64 images, URL images, etc.).
For performance, you might enable FlashAttention 2 if available – Qwen’s team suggests this can accelerate inference and save memory, especially with multi-image or video input. In code, that means loading the model with attn_implementation="flash_attention_2" (and ensuring you have a compatible GPU and the flash-attn package).
Fast Deployment with vLLM for Qwen2-VL
When serving Qwen2-VL in a production or multi-user setting, vLLM is a great option for optimized inference. vLLM is a high-throughput serving engine that can significantly speed up generation and handle many requests via continuous batching. The Qwen2-VL models are integrated with vLLM, allowing you to host an OpenAI-compatible API for Qwen2-VL easily.
To use Qwen2-VL with vLLM, ensure you have vLLM v0.6.1 or above (which added support for multimodal inputs). Here’s a quick guide:
Install vLLM (and other dependencies): in addition to transformers and qwen-vl-utils, install vLLM:
pip install vllm==0.6.1 accelerate # specify CUDA extra-index if needed as per vLLM docsLaunch the vLLM server with Qwen2-VL:
python -m vllm.entrypoints.openai.api_server --model Qwen/Qwen2-VL-7B-Instruct --served-model-name Qwen2-VL-7B-Instruct --port 8000This command starts a local server on port 8000 that exposes an OpenAI-like /v1/chat/completions endpoint. The --served-model-name is how the model is identified via the API (here we keep it the same as the model name for clarity). You can also add --limit-mm-per-prompt image=5 (for example) to allow up to 5 images per prompt. By default, vLLM might allow only 1 image if not specified.
Send requests to this API. You can use the OpenAI Python client by pointing it to your local server:
import openai
openai.api_key = "EMPTY" # vLLM doesn’t require a key by default
openai.api_base = "http://localhost:8000/v1"
response = openai.ChatCompletion.create(
model="Qwen2-VL-7B-Instruct",
messages=[
{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": "https://example.com/image.png"}},
{"type": "text", "text": "Your question about the image?"}
]}
]
)
print(response['choices'][0]['message']['content'])Notice that when using the OpenAI API format, we represent images by providing a URL or base64 data URI in the message content with "type": "image_url". The above example passes an image by URL; for a local image, you can base64-encode it and use a data:image/png;base64,... URI as shown in the OpenAI protocol. The response will come back in the same structure as an OpenAI chat completion, containing the assistant’s message.
Using vLLM, you get the benefit of faster inference (through optimized GPU memory management and batching) and the convenience of a standard API. In a production environment, you might containerize this (the Qwen team provides an official Docker image as well) and deploy on a GPU server to serve client requests. Do note a couple of current limitations: the vLLM OpenAI server mode does not yet support video input (in development), and setting custom min_pixels/max_pixels per request isn’t supported via the API call (though you can adjust the defaults in the model’s config as a workaround). Despite that, for image-based use cases vLLM works seamlessly.
Alternatively, vLLM also provides a Python API (vllm.LLM) that allows you to generate from the model in-process with high efficiency. For example:
from vllm import LLM, SamplingParams
from transformers import AutoProcessor
from qwen_vl_utils import process_vision_info
llm = LLM(model="Qwen/Qwen2-VL-7B-Instruct", limit_mm_per_prompt={"image": 10})
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")
messages = [{"role": "user", "content": [...]}] # similar to earlier format
text_input = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=[text_input], images=image_inputs, videos=video_inputs, return_tensors="pt")
sampling_params = SamplingParams(max_tokens=200, temperature=0.7, top_p=0.8)
outputs = llm.generate(inputs, sampling_params)
print(outputs[0].outputs[0].text)
This approach is a bit lower-level but avoids the overhead of HTTP calls. In summary, vLLM gives you the flexibility to serve Qwen2-VL as a fast API endpoint or use it as a library for optimized local inference.
Prompt Engineering for Multimodal Tasks
Interacting with a multimodal model like Qwen2-VL introduces new considerations in prompt design. Here are some tips for effective prompt engineering with Qwen2-VL:
Use Clear Instructions for Visual Tasks: Just as with text-only LLMs, explicitly instructing the model will yield better results. For instance, if you want a summary of an image, prompt with “Describe the image in detail.” or “Summarize what’s happening in this picture.” If you need specific information, ask directly: “What is the text on the sign in the image?” or “Count the number of people in the photo.” Qwen2-VL is instruction-tuned, so it will follow these cues closely. The more precise you are, the more targeted the answer – e.g., “List the items visible on the desk along with their colors.” will make it output a list of objects and colors, whereas just “What’s on the desk?” might produce a narrative description.
Leverage Multi-Turn Dialogues: You can have iterative conversations about an image or video. For example, you might first ask “Who is in this image?”, get an answer, then follow up with “What is that person doing?”. Qwen2-VL is capable of maintaining context across turns (especially with the full 32K context support on larger models). To use this effectively, include the image again in subsequent turns if needed or rely on the conversational memory. The format for additional turns would omit the image if continuing on the same visual context, as the model will remember what it saw (up to context length limits). If the conversation gets lengthy or you switch images, re-provide images as necessary.
System Prompts for Role Behavior: You can guide the model’s behavior with a system message (the first message with role “system”). For example, if you want answers in a particular format or style, you can say: “You are an assistant that provides concise answers. If the user asks for a list, respond in bullet points.” This can enforce consistency, which is useful in applications (like always returning JSON or always being terse, etc.). In a developer setting, system prompts can also preload instructions like “When given an image of a document, extract key fields in JSON.” – then no matter how the user formulates the request, the assistant will aim to do that extraction.
Structured Output Prompts: As shown earlier, Qwen2-VL can output tables, JSON, or code if asked. Use phrases like “Give the answer in JSON format.”, “Convert the image content to Markdown.”, or “Provide the result as a Python dictionary.” The model has training data for following formatting instructions (especially the instruct version), so it often succeeds in producing valid JSON or markdown. Always validate the outputs though, as there might be minor formatting issues. For critical applications, you might combine this with post-processing or have the model validate its own output by adding a follow-up system check.
Combining Text and Images in Prompt: You can supply additional text context alongside an image. For example, you might input an image of a product and also add a text snippet like “Product name: XYZ. Known issues: overheating.” and then ask a question that requires both the image and text. Qwen2-VL will treat the text in the prompt just as it would in a text-only LLM, while also looking at the image. This is powerful for context-setting – e.g., providing a short background or partial information and letting the model fill in the rest from the image. Ensure that any text you include that is not meant to be seen by the user (like metadata) is put either in a system message or clearly separated, to avoid it mixing with user-visible content.
Handling Errors or Ambiguity: If the model is unsure (say the image is unclear or the question ambiguous), Qwen2-VL might respond with its best guess or ask for clarification. In a user-facing app, you might want to detect uncertainty. One strategy is to instruct the model, “If you are not sure, say you are not sure.” in the system prompt, to discourage hallucinated answers about an image. You can also ask the model to show its reasoning (chain-of-thought) by prompting “Explain step by step how you arrived at the answer.” – though in most cases you’d only want the final answer for end users.
In general, most best practices from prompt engineering for LLMs apply here, with the added dimension of describing what to do with image/video content. Qwen2-VL’s instruction tuning means it is quite good at following prompt directives, making it relatively straightforward to get the desired output style with a bit of experimentation.
Performance and Deployment Considerations
When bringing Qwen2-VL into real-world projects, developers should consider resource requirements, latency, and deployment architecture:
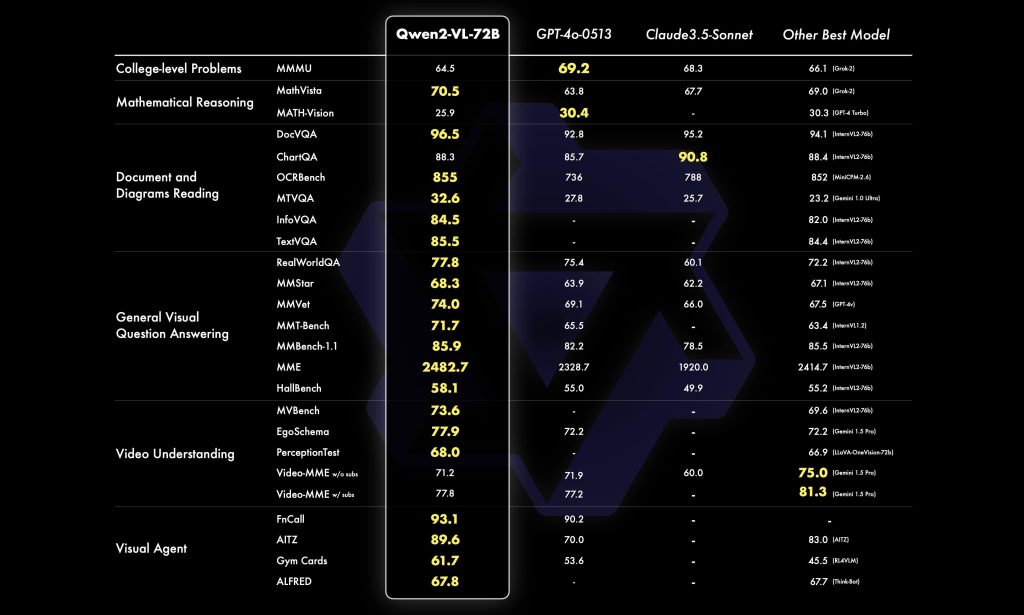
Model Size vs Performance: Qwen2-VL comes in different sizes – the 2B, 7B (open) and a much larger 72B (closed or limited release) model. The 7B model offers a sweet spot for many, achieving strong results on vision tasks while being feasible to run on a single high-end GPU. The 7B actually includes the 600M vision encoder + ~6.5B language decoder. Running it in 16-bit precision typically requires around 14–16 GB of GPU memory. With memory optimization (bf16, weight offloading) or 8-bit quantization, it can fit on a 12GB GPU, though with slower generation.
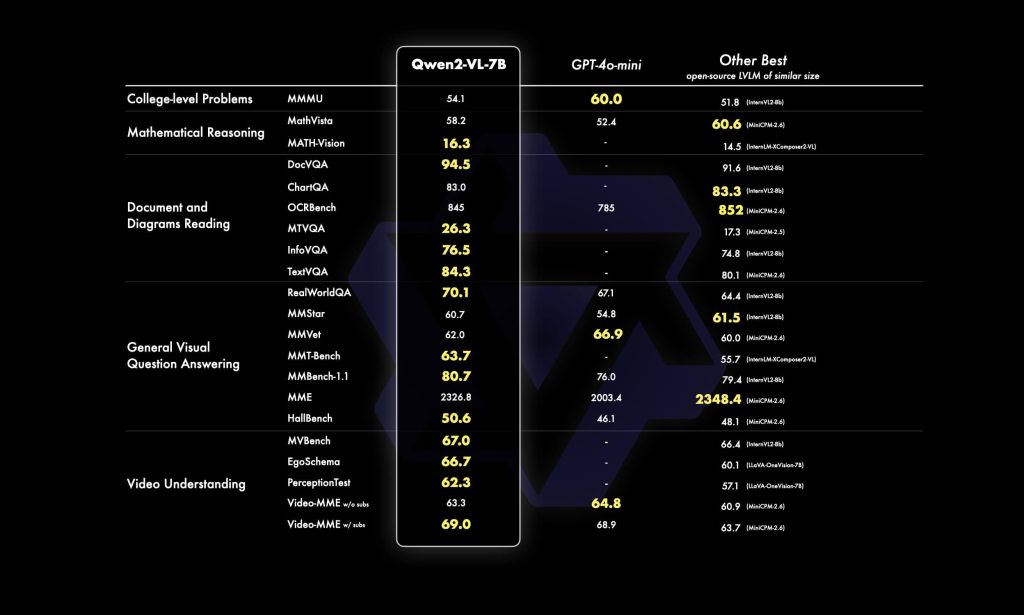
The 2B model is even lighter – ~2.6B total with vision encoder – and was optimized for potential mobile or edge deployment. It can run on smaller GPUs (maybe 4–6GB) or even on CPU in a pinch (with acceleration libraries). Its performance is lower than 7B but still “strong in image, video, and multilingual comprehension” for its size, making it useful for low-power scenarios. The 72B model (often referred to as Qwen2-VL-Max) delivers the highest accuracy (rivaling top proprietary models in many benchmarks), but it’s extremely demanding – essentially requiring cluster-scale memory (several 80GB GPUs). Most developers will use the 72B via Alibaba’s cloud API unless they have significant infrastructure.
Latency: Inference speed will depend on model size and input length. For an image + question prompt of moderate length, the 7B model can respond in a few seconds on a single GPU (with newer GPUs using FlashAttention and optimized kernels, responses <5s are achievable for short answers). If the prompt includes a very large image (lots of visual tokens) or the answer is long, it will take longer.
Multi-image and video (multiple frames) increase the token count proportionally, which can linearly affect compute time. The 2B model will be roughly 3x faster than 7B, so it’s great for real-time or high-throughput needs, at the cost of some accuracy. Techniques like quantization can also improve throughput: Qwen2-VL has compatible quantized versions (e.g., 4-bit or 8-bit weights via GPTQ or AWQ) which significantly reduce memory and can increase speed on CPU-bound deployments. Quantization may incur a small drop in quality, but often worth it for deployment.
Memory and GPU considerations: If you want to handle multiple concurrent requests, you might choose vLLM or Hugging Face’s Text Generation Inference (TGI) to serve the model efficiently. These frameworks can batch requests and stream outputs. Streaming is useful for long answers – you can start sending tokens to the user as they are generated (Qwen2-VL supports streaming generation). For GPU memory, you can also use techniques like multi-GPU sharding (HuggingFace device_map={"": "balanced"} can split the model across two GPUs, for example).
The vision encoder part (600M) is relatively small, so the bulk is the language model. Also note that high-res images will temporarily use more memory for the visual embeddings (e.g., a 16384 visual token image will produce that many embedding vectors). You can limit the resolution processed by setting max_pixels in the AutoProcessor (as shown earlier) to trade off detail for speed. For instance, setting max_pixels = 1280*28*28 limits images to around 1280 tokens (downsampled if larger) which can help keep memory in check for super high-res inputs.
Deployment Options – Cloud vs Edge: For easy integration, you might use Alibaba’s official API (DashScope) which provides hosted access to Qwen2-VL-72B (the code snippet in the Qwen blog shows how to call it via an OpenAI-like client). This is convenient if top accuracy is needed and you don’t mind using a paid API. However, many will opt to self-host the open 7B model for cost and data privacy reasons. Self-hosting can be done on cloud VMs with GPUs (e.g., an EC2 instance with an NVIDIA A10G or better for the 7B).
If targeting edge devices or on-prem, the 2B model is the candidate – it might even run on certain mobile chipsets or NVIDIA Jetson-class devices with optimization. The Apache 2.0 license allows commercial use, so integrating it into a product is permissible (do check the license of any training data or specific terms in the model card for details, but generally Qwen models are designed for wide use). Edge deployment might also involve distillation or pruning for efficiency, though there’s no official distilled version at the moment.
Scaling and Multi-modal Infrastructure: If your application involves heavy image or video throughput, consider a pipeline where image pre-processing (like resizing, format conversion) is done asynchronously. For example, you could have a service that takes raw images, compresses or converts them to a suitable size, and then calls Qwen2-VL. Also, if using the model for video, you may not need to feed every single frame; sampling one frame per second or key frames might give sufficient context and save compute.
The Naive Dynamic Resolution means even large frames are handled, but you should still be mindful of extremely high resolutions – after a point, adding more pixels yields diminishing returns in understanding versus the cost. The open model defaults to ~16k visual tokens max, which is a huge capacity (roughly equivalent to a 1024×1024 image patch grid). In practice, resolutions up to ~2K on a side can be ingested without issue; beyond that, consider downscaling unless the task truly demands it.
Monitoring and Logging: As with any LLM deployment, capturing the model’s inputs and outputs (especially images and the model’s descriptions of them) is important for debugging and improvement. One challenge in multimodal models is evaluating accuracy – e.g., was the model’s answer about an image correct? You might need human verification for critical tasks or use automated checks (like comparing OCR text to known ground truth if available).
Pay attention to cases where the model might hallucinate about an image (less common than text hallucination, but possible if the image is ambiguous or if the model over-interprets). Implementing confidence measures or fallback logic (perhaps if the answer is below a certain length or contains uncertain language) can improve reliability in a system.
In summary, match the model size to your use case constraints (2B for lightweight tasks/edge, 7B for general use with a GPU, 72B for max accuracy via cloud or heavy server), use optimization techniques to reduce latency (quantization, flash attention, batching via vLLM), and be mindful of how visual input size impacts performance. With proper deployment planning, Qwen2-VL can run efficiently and serve responses in near real-time for many applications, all while providing cutting-edge multimodal understanding.
Limitations and Challenges
While Qwen2-VL is a powerful vision-language model, it’s not without limitations. Developers should be aware of the following when using the model:
Knowledge Cutoff: The model’s training data only goes up to mid-2023 (June 2023). This means it will not know about events, people, or changes that happened after that date. It might also miss very recent product names or new logos in images, etc. If asked about something very current visible in an image (say a brand-new car model released in 2024), it may not recognize it or might guess based on similar known items. Integrating an updated knowledge base via RAG could help in those cases.
Accuracy in Complex Scenes: Although Qwen2-VL improved multi-object understanding, it can still struggle with very crowded or complex scenes. For example, accurately counting a large number of objects (it’s noted the model can be relatively weak in tasks involving precise counting). It might give an approximate count if the number is large. Similarly, while it can do OCR, if the text is extremely small, curved, or stylized, there’s a chance of errors – they mention it’s still not perfect at fine character recognition (despite big gains in multilingual text reading). For critical use, a dedicated OCR might sometimes outperform it on pure text accuracy, but Qwen2-VL adds interpretation on top of OCR.
3D Spatial Reasoning: The model has limited ability to infer 3D structures from images. It might not understand depth or physical occlusions perfectly. For instance, questions like “Is object A in front of object B?” can be tricky if not obvious. It doesn’t have a true 3D model of the world; it relies on learned correlations. So tasks needing precise spatial awareness (e.g., counting layers in an X-ray image or understanding a 3D maze) might be challenging.
No Audio or Speech: Qwen2-VL currently does not handle audio – even if the input is a video with sound, it only “sees” the frames. It won’t transcribe or consider spoken words in a video. So if your use case involves multimedia with sound, you’d need an extra step (like automatic speech recognition) and then possibly feed the transcript as text. The model also doesn’t generate audio – it’s purely text output. If you need voice, that would be a separate text-to-speech system.
Biases and Errors: Like all AI models trained on web data, Qwen2-VL can exhibit biases or inappropriate outputs. It might, for example, make assumptions about people in images that reflect societal biases. Alibaba likely put in some alignment and filtering (especially for the instruct model), but one should still monitor for any offensive or biased interpretations of images. Moreover, the model might sometimes be overly confident in a wrong answer – e.g., misidentifying a rare animal as a common one and stating it as fact. For high-stakes use (medical images, legal documents), human oversight is advised.
Prompt Sensitivity: Multimodal models add complexity in prompt formatting. If the prompt JSON is not structured exactly as expected, the model might ignore the image or get confused. This is more of an integration limitation – e.g., forgetting to include "type": "image" might cause the image to be treated as text gibberish. Also, very long or complex prompts with many images and text pieces might hit the context limit or lead to the model losing track if not organized well. It’s wise to test prompts and see how the model responds, and incrementally build up complexity.
Resource Intensive: As discussed, running Qwen2-VL, especially for video, is computationally heavy. This isn’t a limitation of the model’s capabilities per se, but a practical constraint. If you attempt to give a full 20-minute HD video to the model, processing it frame by frame will be slow and memory-hungry. The current open version doesn’t magically solve the inherent cost of analyzing thousands of frames – it provides the ability, but developers must still optimize (by sampling frames, etc.). So, ensure that your usage of the model is feasible within your infrastructure. The 72B model in particular is out of reach for most local setups.
Despite these limitations, Qwen2-VL is a major step forward in open multimodal AI. Many of the challenges (like audio support or even better counting) are active areas of research, and future versions (Qwen3-VL, etc.) may overcome them. For now, being aware of these limits allows you to design your application to mitigate them – e.g., incorporate fallback rules if the model’s answer seems uncertain, use additional tools for things like counting or OCR if absolute precision is needed, and constrain the problem to what the model handles well.
Developer FAQs
What input types and formats does Qwen2-VL support?
Can Qwen2-VL read text inside images?
How do I integrate Qwen2-VL into my application or workflow?
Via Hugging Face Transformers: as shown in the Python example, you can load the model and run it in your environment. This is great for prototyping and offline use. You’ll need a suitable GPU and enough memory. This approach gives you full control – you can modify the model, fine-tune it, etc.
Using vLLM or TGI for serving: if you need to serve the model as an API (for a web service or multi-user app), deploying with vLLM (for optimized inference) or Hugging Face’s Text Generation Inference (which also supports multi-client serving) is recommended. These let you host a persistent model and get results via HTTP or a client SDK, which is more production-friendly. Qwen2-VL is already compatible with these frameworks.
Cloud API: Alibaba offers the Qwen-VL-72B via an API (and possibly smaller models too) through their DashScope service. You would call it similarly to how you call OpenAI’s API. This is convenient if you don’t want to manage infrastructure – just be mindful of cost and data privacy (as your images will be sent to their cloud).
ModelScope or Azure: Qwen2-VL is also available on ModelScope (Alibaba’s AI model hub) and has entries in Azure’s model catalog. If you are in those ecosystems, you might directly instantiate the model from there. For instance, Azure AI Foundry provides Qwen2-VL-7B for use with their inference endpoints.
In all cases, ensure you respect the model’s license (Apache-2.0 for 2B/7B – very permissive). Integration is largely about picking the right hosting method for your needs (offline vs cloud, single-user vs multi-user).
What hardware do I need to run Qwen2-VL?
Is fine-tuning Qwen2-VL on custom data possible?
What are the licensing and usage terms?
Conclusion
Qwen2-VL represents a significant leap in open-source AI, bringing vision and language together in one powerful package. Its high-level architecture – combining a flexible ViT encoder with a potent LLM decoder – allows it to perceive the world through images and videos and discuss it with us through natural language.
We’ve seen how it can perform an array of tasks: describing images, answering visual questions, reading and translating text from pictures, solving problems with diagrams, analyzing videos, and even interacting with user interfaces or tools based on visual cues. These capabilities unlock new possibilities for developers across industries, from e-commerce and education to robotics and enterprise automation.
Technically, Qwen2-VL is accessible and fairly easy to integrate: the 7B and 2B models can be loaded with standard libraries, and solutions like vLLM make deployment efficient for real applications. The inclusion of Python examples and an active open-source community around Qwen (with ongoing improvements like Qwen2.5 and beyond) means developers are empowered to experiment and build with this model right away. Whether you need to build a smart document assistant, a visually-aware chatbot, or a system that combines text and imagery for better answers, Qwen2-VL provides a foundation that’s both cutting-edge and within reach.
As with any AI, using Qwen2-VL responsibly is key – understanding its limitations and ensuring oversight for critical tasks. But overall, it pushes the envelope for what an open multimodal model can do, matching some of the best closed models on many fronts. The future likely holds even more advanced versions (with audio, more modalities, even larger scales), but Qwen2-VL is already a milestone towards truly omniscient AI systems that see and speak.
Harnessing Qwen2-VL, developers can create more intuitive and powerful applications that understand our visual world. We hope this deep dive has given you a comprehensive understanding of Qwen2-VL’s design and how to use it. Now it’s up to you to build something amazing with it!