
Qwen2.5 is the latest series of large language models (LLMs) released by Alibaba’s Qwen team, representing a significant upgrade over earlier Qwen generations. It is a family of dense, decoder-only Transformer models ranging from 0.5 billion to 72 billion parameters, making it one of the most extensive open-source LLM releases to date.
Qwen2.5 models have been pretrained on a massive dataset of up to 18 trillion tokens, endowing them with substantially more knowledge and improved capabilities in coding and mathematics compared to previous versions. All the base models (except a few largest variants) are open-source under permissive licenses, enabling developers to freely download and deploy them in their own applications.
Qwen2.5 delivers a more knowledgeable, efficient, and stable LLM platform for developers, with specialized variants targeting coding, math, and even multimodal tasks.
Architecture Overview
At a high level, Qwen2.5 follows a Transformer decoder-only architecture typical of modern LLMs. The models are dense (no mixture-of-experts for the open versions) and feature state-of-the-art design choices to boost performance and training stability.
For example, Qwen2.5 uses Rotary Position Embedding (RoPE) for flexible position encoding, SwiGLU activation functions in the feed-forward layers, RMSNorm normalization, and a bias in the attention mechanism’s QKV projections. These architectural components are similar to those used in recent top-tier LLMs and contribute to better training convergence and inference quality.
The model is purely decoder-based, meaning it generates text autoregressively and is well-suited for text generation and chat completion tasks.
Parameter Sizes and Context Window: Qwen2.5 is offered in multiple parameter scales – 0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B – to cater to different deployment needs. Smaller models (3B and below) are even optimized for mobile or edge use, while the largest 72B model provides maximum accuracy. All models support very large context lengths: up to 128K tokens of context in the mid-to-large variants, and 32K tokens in the smallest ones. This is orders of magnitude beyond the context window of most previous-generation open models. Qwen2.5 achieves this by using advanced position scaling techniques (internally utilizing the YaRN method to extrapolate RoPE embeddings) to handle long sequences. By default, the configuration is set to 32K, but developers can enable the extended 128K context mode when needed. This architectural ability allows Qwen2.5 to ingest extremely long inputs – such as lengthy documents or multi-turn dialogues – without running out of context.
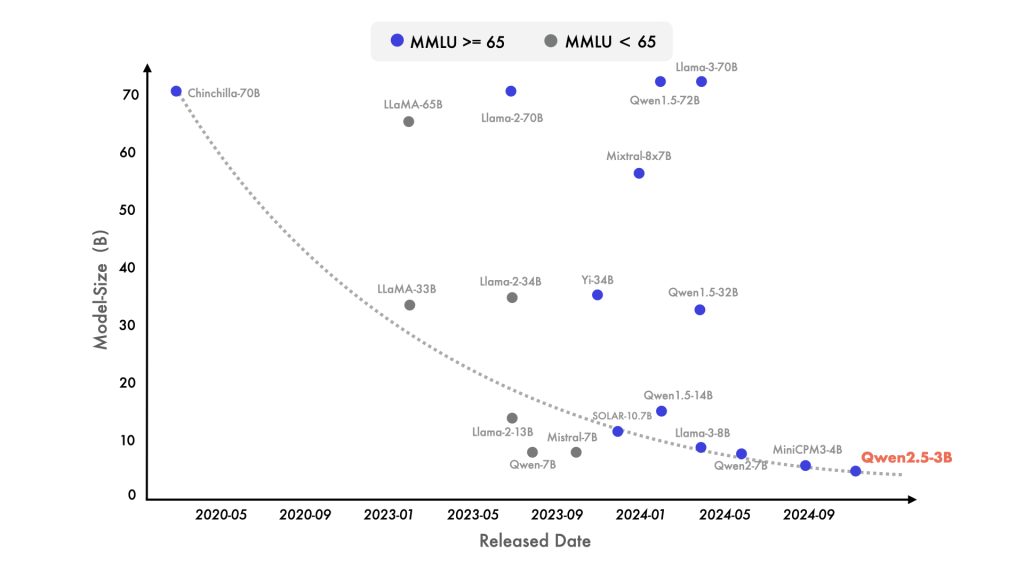
Training Enhancements and Alignment: The Qwen2.5 models underwent rigorous training regimes to improve their knowledge and reasoning stability. The pretraining corpus (multilingual and multimodal) was expanded from 7 trillion tokens in Qwen2 to 18 trillion in Qwen2.5, significantly increasing the knowledge captured in the model. In addition, Qwen2.5 models were post-trained on high-quality instruction-following data to better align with human preferences and conversational use. According to the Qwen team, the new models show major gains in instruction following, long-form text generation, and structured output formatting (like producing JSON or tables). Notably, Qwen2.5’s training strategy incorporated techniques to stabilize complex reasoning: for example, the specialized math model was trained with Chain-of-Thought (CoT), Program-of-Thought (PoT), and Tool-Integrated Reasoning (TIR) methods to improve step-by-step problem solving. This means the model is more likely to work through problems methodically (and even utilize external tools or calculations when appropriate), resulting in more reliable reasoning and fewer hallucinations on complex queries. Overall, the architecture and training enhancements of Qwen2.5 translate into a model that is more robust, knowledgeable, and controllable in practical deployments.
Performance and Benchmarks
Qwen2.5’s performance on official benchmarks places it among the top-performing open models in 2024-2025. The largest model Qwen2.5-72B achieves state-of-the-art results across a broad range of evaluations. For instance, on the academic knowledge test MMLU, Qwen2.5-72B scores over 85 (expert-level), a jump from ~70 in the previous generation and indicating a substantially broader knowledge base.
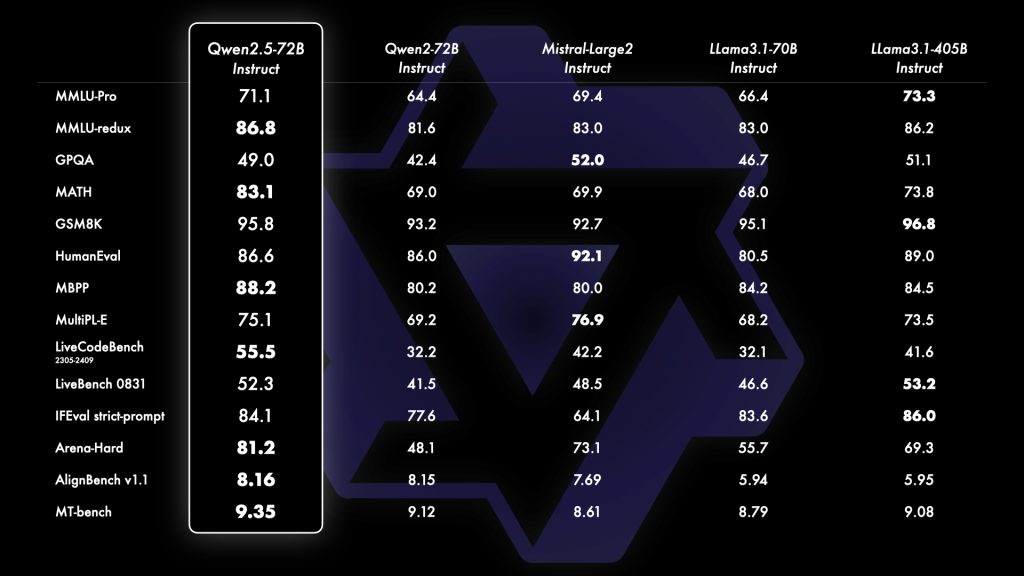
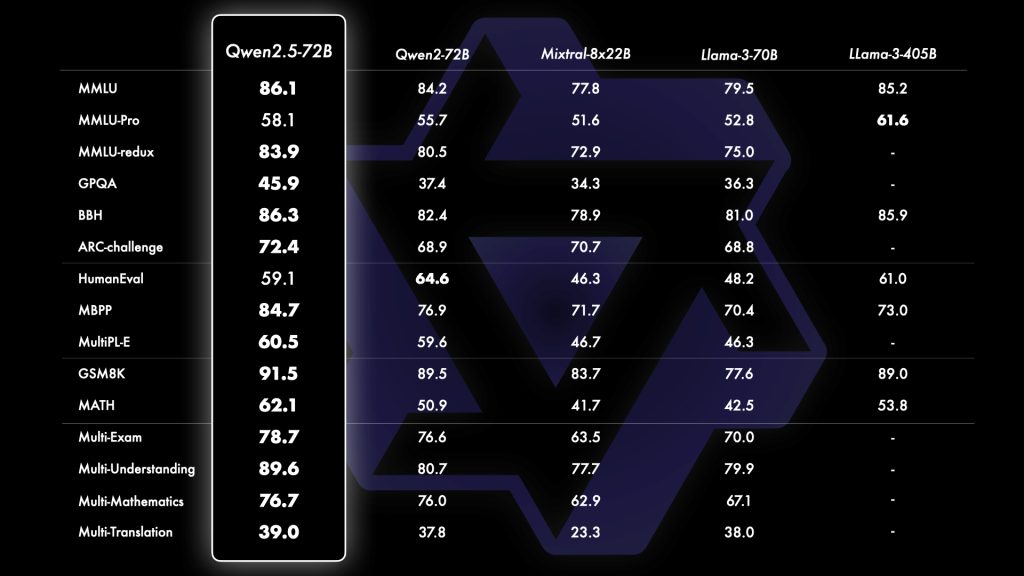
Its coding prowess is similarly impressive: Qwen2.5’s instruction-tuned model records HumanEval scores above 85% (solving the majority of programming tasks), which is a dramatic improvement attributed to the new coding-focused training. Mathematical reasoning, measured by the MATH benchmark, is another area of advancement with Qwen2.5 reaching ~80% accuracy, reflecting the benefit of the integrated math reasoning techniques.
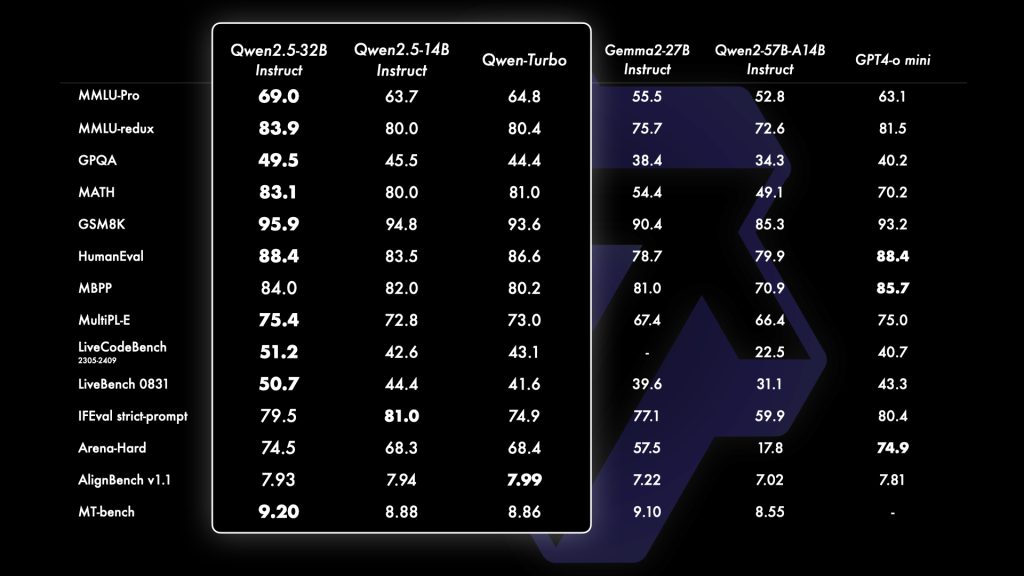
Even the mid-sized Qwen2.5 models are strong performers. For example, the 14B and 32B variants are reported to outperform much larger models from the previous Qwen2 series in the team’s internal evaluations.
In terms of human-aligned dialogue quality, the Qwen team noted that human preference scores (like Arena benchmark) for Qwen2.5 have surged – the 72B model’s helpfulness rating almost doubled compared to its predecessor. This indicates that Qwen2.5 not only excels in raw problem-solving, but also in producing answers that humans find coherent and useful in a chat setting.
Importantly, all these performance claims come from official benchmarks and evaluations released by the Qwen developers, giving a reliable picture of its capabilities. Qwen2.5-72B’s results are competitive with or superior to other leading open-source LLMs in the same size class on tasks covering knowledge, reasoning, coding, and multilingual understanding.
In summary, Qwen2.5 delivers top-tier accuracy on benchmark tests, especially in knowledge recall, code generation, and math reasoning – matching the needs of advanced AI applications.
Long-Context Handling and Multilingual Support
One of the standout features of Qwen2.5 is its ability to handle very long contexts. Most Qwen2.5 models (7B and above) support context windows up to 128,000 tokens. In practical terms, this means you could prompt the model with hundreds of pages of text or a lengthy transcript and still get a coherent analysis or continuation.
Such long-context handling is enabled by Qwen’s use of the YaRN scaling for RoPE embeddings, which allows the self-attention mechanism to effectively attend over long sequences without forgetting earlier parts. The model can also generate very long outputs (up to 8K tokens in one go), useful for tasks like writing extensive reports or multi-chapter stories in a single run. Developers can leverage this capability for tasks such as processing entire documents, multi-turn dialogues that span many interactions, or retrieval-augmented generation where many pages of reference text are included in the prompt.
In addition to long text, Qwen2.5 is inherently multilingual, supporting 29+ languages including English, Chinese, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more. The training data was multilingual, enabling the model to understand and generate text in these languages with strong competency. This makes Qwen2.5 suitable for global applications and cross-lingual tasks (such as translating a query in one language and answering in another, or summarizing a document written in a non-English language).
Notably, the specialized Qwen2.5-Math model supports both Chinese and English problem solving seamlessly, illustrating how multilingual support is integrated even in domain-specific variants. For developers, this means you can present prompts or questions in various languages and expect Qwen2.5 to respond appropriately, or build assistants that switch languages according to user needs – all without needing separate models for each language. Overall, Qwen2.5’s long context and multilingual features greatly expand the range of tasks and use cases that can be tackled within a single unified model.
Qwen2.5 Model Variants and Specializations
The Qwen2.5 release is not a single model but a family of related models, each tailored to specific use cases. All share the same underlying architecture but differ in fine-tuning or modality. Here’s an overview of the key Qwen2.5 variants and what they offer:
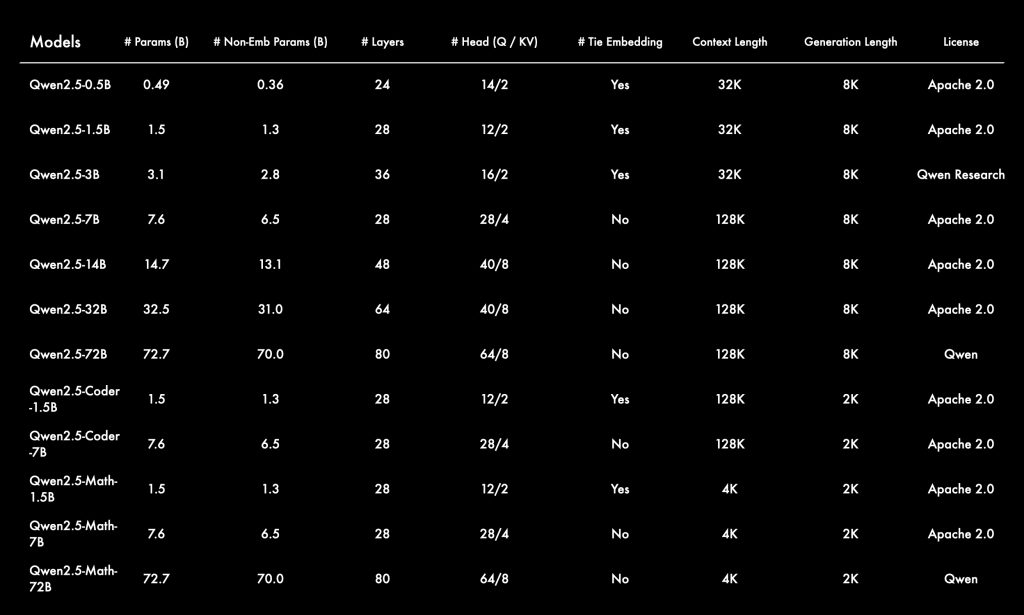
- Base and Instruct Models (Text & Chat): The core Qwen2.5 models are trained as general-purpose LLMs for text generation. The base models are pretrained on large text corpora (up to 18T tokens) without instruction fine-tuning, useful if you plan to further fine-tune on custom data. The instruction-tuned models (sometimes referred to as “Chat” models) have been post-trained on conversational and instructional data to behave helpfully and safely in dialogue. These instruct models (
Qwen2.5-7B-Instruct) are ideal for direct use in chatbots, Q&A systems, and interactive applications since they follow user prompts and system directives well out-of-the-box. They support role-based prompting (system/user/assistant) and are aligned for polite, helpful responses. In sizes from 0.5B up to 72B, developers can choose a model that fits their resource constraints while still benefiting from Qwen2.5’s core capabilities. - Qwen2.5-Coder (Code Specialist): Qwen2.5-Coder is a specialized version aimed at programming and software development tasks. It was trained on 5.5 trillion tokens of code-related data, spanning over 40 programming languages. This extensive coding corpus means the model has learned programming syntax, libraries, and problem-solving patterns, making it perform exceptionally well on coding benchmarks. Even relatively small Qwen2.5-Coder models can compete with larger general models in code generation and comprehension tasks. Developers can use Qwen2.5-Coder for tasks like writing functions or classes given a specification, generating algorithmic solutions, debugging code by describing errors, or even converting code from one language to another. The model is also effective in code understanding – explaining code, generating comments, or summarizing code behavior – which can aid in code review automation. Qwen2.5-Coder is available in parameter sizes geared toward practicality (e.g. 7B and 32B) so that it can be deployed with moderate hardware while providing high coding accuracy.
- Qwen2.5-Math (Math & Reasoning Expert): Qwen2.5-Math is a variant fine-tuned for complex mathematical reasoning and problem-solving. It integrates techniques like Chain-of-Thought (stepwise reasoning), Program-of-Thought (executing code for computation), and Tool-Integrated Reasoning to solve math problems that typically stump standard LLMs. The math expert model can tackle tasks such as solving advanced algebra or calculus problems, performing multi-step logical reasoning puzzles, and handling math word problems. It supports both English and Chinese problem formulations, reflecting a diverse training set. For developers building applications like tutoring systems, math question answering, or scientific research assistants, Qwen2.5-Math provides enhanced reliability in mathematical correctness. It’s available in select sizes (for example, 7B and a large 72B version) to balance reasoning quality with inference cost.
- Qwen2.5-VL (Vision-Language Model): Moving beyond text, Qwen2.5-VL is a multimodal model that extends Qwen’s capabilities to images (and even videos). The “VL” models can accept image inputs (or image+text combos) and produce text outputs describing or analyzing the visuals. According to the Qwen team, Qwen2.5-VL can parse image files, understand video content, count objects in images, and perform document analysis from scans. For example, it can analyze a chart or graphic and explain the data, extract information from a photographed invoice or form, or answer questions about a video clip. Impressively, the largest Qwen2.5-VL (72B) can comprehend videos over 20 minutes long and handle multi-image inputs. This model was also demonstrated controlling a PC and mobile device in an agent-like fashion (interpreting a user request and taking actions like opening apps) in research demos, showing the potential for tool use and automation with multimodal understanding. Qwen2.5-VL models are available for download (e.g. 7B, 32B, 72B instruct versions on Hugging Face) for developers who want to build vision-enabled assistants or image analysis tools. Keep in mind that using these requires handling image data and possibly more GPU memory, but they unlock tasks like image captioning, visual QA, and integrating text+image reasoning in one model.
- Qwen2.5-Omni (All-in-One Multimodal 7B): An interesting addition to the family is Qwen2.5-Omni-7B, a smaller end-to-end multimodal model. The Omni variant is designed to process diverse inputs – text, images, audio, and video – and generate multi-format outputs including text and even speech. Essentially, it’s a compact model that can “see, hear, and speak,” intended for devices or scenarios where a single lightweight model needs to handle various modalities. For instance, Omni-7B could take an audio query, transcribe it, reason about it, and respond with a spoken answer; or take an image and a question about it and then speak out the answer. While being only 7B parameters, Qwen2.5-Omni has been optimized for operability on limited hardware (there are quantized versions and techniques to run it on GPUs with constrained memory). This model ranked highly on multimodal understanding benchmarks (e.g. spoken language understanding) among open-source models. Developers interested in building mobile AI assistants or IoT applications might find Omni-7B particularly useful, as it brings a wide range of capabilities in a small footprint.
In addition to the above, Alibaba provides proprietary enhanced models like Qwen-Plus and Qwen-Turbo via their cloud API. These are fine-tuned, possibly larger or RLHF-optimized versions intended for enterprise use through services (they are not open-weight downloads). They generally offer even better performance and more guardrails, but require using Alibaba Cloud’s endpoints. For most open-source development needs, however, the Qwen2.5 open models (base or instruct) and their code/math/multimodal variants will cover a broad spectrum of use cases.
Core Developer Use Cases for Qwen2.5
With its versatile models and strong technical profile, Qwen2.5 can be integrated into many AI application scenarios. Below are key use cases, from retrieval-augmented QA to autonomous agents, where developers can leverage Qwen2.5 effectively:
Retrieval-Augmented Generation (RAG)
One prime use of Qwen2.5 is in building systems that augment the LLM with external knowledge. In a RAG setup, you combine Qwen’s generative abilities with a knowledge base or search engine. For example, when a user asks a domain-specific question, you can fetch relevant documents (from a vector database or enterprise knowledge source) and provide those as part of the prompt to Qwen2.5. Thanks to its long 128K token context, Qwen2.5 can easily ingest large retrieved documents or multiple pieces of evidence and then generate a consolidated answer.
Its strong language understanding (MMLU 85+ level knowledge) means it can accurately incorporate factual content from the retrieved text. Developers can use libraries like LlamaIndex or LangChain (which Qwen is compatible with) to manage the retrieval and prompt assembly. Qwen2.5’s improved structured output abilities also help in RAG flows – for instance, you can prompt it to output an answer with citations or in a JSON format combining information from multiple sources. Overall, Qwen2.5 serves as a powerful engine for knowledge-grounded QA, enterprise document assistants, and any application where up-to-date or proprietary information needs to be woven into an LLM’s response.
AI Agents and Tool Use
Qwen2.5 can function as the “brain” of an AI agent, deciding actions to take and interfacing with tools. The Qwen team has demonstrated that these models are capable of tool use and even controlling software: for example, Qwen2.5-VL can interpret a user request and then manipulate a GUI (opening apps, clicking buttons) to fulfill a task. Developers can replicate such capabilities by using frameworks and giving Qwen structured prompts. Qwen2.5 supports an openAI function calling-like paradigm (the Qwen documentation provides a function calling interface), meaning you can define a set of tools or API functions and the model will output a JSON indicating which function to call with what arguments – essentially enabling it to act as an agent that can use calculators, databases, or other APIs.
Additionally, integration with LangChain is supported, so you can use Qwen as the LLM in a LangChain agent that decides to perform search queries, calculations, or other operations in a conversational loop. When building agents, the reliability and reasoning improvements in Qwen2.5 pay off: it’s more likely to follow the designed plan and less prone to hallucinate tool names or instructions. Use cases here include chatbots that can browse data or control IoT devices, virtual assistants that automate tasks (scheduling meetings, sending emails on command), or robotic process automation where an LLM drives software workflows. Qwen2.5 provides the intelligence and language understanding, while external tools provide the actuators – together enabling complex autonomous behavior in applications.
Backend Automation and Data Processing
Beyond user-facing chat, Qwen2.5 can be used in back-end systems to automate and orchestrate various tasks. Thanks to its capability to understand instructions and produce structured output, it can serve as a natural language interface for backend workflows. For example, a developer might use Qwen2.5 to parse incoming customer support emails and route them or draft replies; or to analyze logs and generate a summary report of system anomalies. In data pipelines, Qwen2.5 can be prompted to transform data descriptions into SQL queries, interpret the results, or even generate code snippets for ETL jobs. With its strong JSON output formatting skill, Qwen2.5 can act as a translator between unstructured text and structured data.
An enterprise workflow could involve Qwen reading a free-form requirement (“We need a weekly summary of sales grouped by region”) and producing a JSON or script that fulfills the request. Moreover, Qwen’s long-form generation allows it to produce detailed documents or reports, which can be used to automate report writing or documentation tasks on the backend. Essentially, any scenario where you have textual or semi-structured input and need an automated but intelligent response or transformation, Qwen2.5 can be a component in the pipeline – reducing the need for complex rule-based systems and allowing more natural instruction-driven automation.
Code Generation and Software Development
With the Qwen2.5-Coder model and the base model’s coding improvements, a clear use case is in software development and DevOps automation. Developers can integrate Qwen2.5 into IDEs or code review tools to assist with writing functions, documenting code, generating unit tests, and even diagnosing bugs. For instance, given a description of a desired function, Qwen2.5-Coder can generate Python (or other language) code implementing it, often correctly and following best practices. The model understands a wide variety of programming languages (40+ languages tested), so it can help with polyglot codebases or translating code from one language to another. It also excels at explaining code – you could paste a snippet and ask Qwen “What does this code do?” and get a coherent explanation, which is valuable for onboarding or debugging.
Integration examples include using Qwen in a pull request bot that comments on potential issues or improvements in code, or a chatbot that developers can ask “How do I do X in framework Y?” and get code suggestions. Qwen2.5’s coding capabilities mean it can serve as a powerful AI pair programmer or a backend service that auto-generates scripts/configurations based on high-level instructions. Its high HumanEval benchmark (~85%+) indicates a reliability in generating syntactically correct and logically sound code for many standard problems. While one should always test and review AI-generated code, Qwen2.5 can drastically speed up the development cycle by handling boilerplate and offering intelligent suggestions.
Enterprise AI Workflows
Many enterprises are looking to deploy AI assistants and analytics internally, and Qwen2.5 is well-suited for these enterprise AI workflows. Because most Qwen2.5 models are open-source (Apache 2.0 for the majority), companies can self-host these models, ensuring data privacy and compliance – a critical requirement for sensitive business data. Use cases here include: an internal knowledge base chatbot that employees query for company policies or technical documentation (leveraging RAG with Qwen to provide accurate answers from internal data); a report generation assistant that managers use by giving a few prompts (Qwen can populate templates or write narratives from data); or an AI customer support agent that is fine-tuned on company-specific support tickets and can draft responses or help human agents.
The availability of various model sizes means enterprises can choose a smaller model for lightweight tasks or real-time interaction, and a larger model for tasks demanding higher accuracy or deep reasoning. Qwen2.5’s multilingual capability is a boon in multinational corporations – a single model can handle inquiries in multiple languages from different regions, maintaining consistency in quality. Moreover, Qwen’s support for quantized models and efficient inference means that even smaller organizations can deploy the model on affordable hardware (or use Alibaba Cloud’s service for scaling as needed). In short, Qwen2.5 empowers enterprises to build custom AI solutions in-house – from intelligent document processing to conversational assistants – with the flexibility of an open model and the backing of a robust technical foundation.
Integration Examples
To help you get started, here are some examples of how to integrate Qwen2.5 into your development workflow. We’ll look at using Qwen2.5 via the Hugging Face Transformers library in Python, as well as calling Qwen2.5 through a RESTful API. We’ll also discuss sample prompts and outputs for different tasks (reasoning, coding, long-context) to illustrate best practices.
Using Qwen2.5 with Hugging Face (Python Library)
One convenient way to use Qwen2.5 models is through Hugging Face transformers, as the Qwen team has published model weights and configurations there. Below is a Python code snippet that demonstrates loading an instruction-tuned Qwen2.5 model and generating a completion for a simple prompt:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-7B-Instruct" # 7B chat-tuned model
# Load the model and tokenizer (ensure using transformers >= 4.37)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Example prompt: Using Qwen2.5 in a chat format with system and user roles
messages = [
{"role": "system", "content": "You are Qwen, a large language model created by Alibaba Cloud. You answer with helpful and accurate information."},
{"role": "user", "content": "Give me a short introduction to large language models."}
]
# Convert messages to model input using Qwen's chat template
text_input = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text_input], return_tensors="pt").to(model.device)
# Generate a response
output_ids = model.generate(**model_inputs, max_new_tokens=256)
generated_tokens = output_ids[0][model_inputs['input_ids'].shape[1]:] # trim prompt tokens
response = tokenizer.decode(generated_tokens, skip_special_tokens=True)
print(response)
In this example, we use the 7B Instruct variant of Qwen2.5. We formulate the input as a list of messages with roles: a system prompt to establish the assistant’s persona or rules, and a user prompt asking a question. The tokenizer.apply_chat_template function (provided in Qwen’s Hugging Face implementation) formats these into the model’s expected conversational text format. Then we generate up to 256 new tokens as the answer. The output response will contain Qwen’s answer, for example it might produce a short paragraph explaining what large language models are.
This code can run on a GPU (the device_map="auto" will distribute model layers to available GPUs). Make sure to use an updated transformers version, as Qwen integration (identified by model type "qwen2") was added in recent versions.
For handling long contexts in Python, Qwen2.5 uses a technique called YaRN for length extrapolation. By default, the model config might be set to 32k. If you need to process extremely long text (e.g. tens of thousands of tokens), you can enable Rope scaling in the model config. For example, you can adjust the config to include:
"rope_scaling": {
"type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
This would extend a 32k model to ~131k context length by scaling RoPE frequencies. The Qwen documentation recommends only turning this on when needed for very long texts, as it may slightly affect performance on shorter inputs. In practice, libraries like vLLM or HuggingFace’s text-generation-webui can handle these settings. With this capability, you could, for instance, tokenize an entire book as input and ask Qwen2.5 for an analysis or summary, which is not feasible with typical 4k or 8k context models.
Sample Prompt and Output (Reasoning): To illustrate Qwen2.5’s reasoning ability, you might give it a prompt like:
User: “Evaluate the integral from 0 to 1 of 3x^2 dx, and explain each step.”
Using the Qwen2.5-Math model, the assistant would likely output a step-by-step solution, e.g.:
Assistant: “First, we find the antiderivative of 3x^2, which is x^3. Then we evaluate this antiderivative from 0 to 1: 13−03=1−0=1.1^3 – 0^3 = 1 – 0 = 1.13−03=1−0=1. So, the value of the integral is 1.”
Notice how the model can follow the chain-of-thought style explanation. The math-specialized model is adept at providing the reasoning along with the answer, which is very useful for domains that require transparency in how the answer was obtained.
Sample Prompt and Output (Coding): Using Qwen2.5-Coder, a prompt could be:
User: “Write a Python function that checks if a number is prime.”
Assistant: (Qwen2.5-Coder might respond with a well-formatted code block)
def is_prime(n: int) -> bool:
\"\"\"Return True if n is a prime number, else False.\"\"\"
if n < 2:
return False
if n % 2 == 0:
return n == 2
# Check odd factors up to sqrt(n)
import math
limit = int(math.sqrt(n)) + 1
for factor in range(3, limit, 2):
if n % factor == 0:
return False
return True
And perhaps a brief explanation after the code. The Coder model is tuned to produce exactly such functional code answers with comments and standard optimizations (like checking 2 separately, using sqrt for loop limit, etc.), as it has seen a lot of coding examples. This makes it extremely handy for code generation tasks.
Using Qwen2.5 via REST API (Alibaba Cloud Service)
If you prefer to use Qwen2.5 as a managed service or integrate it into a backend via HTTP calls, Alibaba Cloud provides a Model Studio API for Qwen. The Qwen API is designed to be OpenAI API compatible, meaning you can use the same request format as you would with OpenAI’s GPT endpoints – just pointing to Alibaba’s endpoint with the appropriate model name and key. This is very convenient for developers who have used OpenAI’s services, as you can repurpose the same client libraries.
For example, using OpenAI’s Python client library to call Qwen2.5-Max (one of the Qwen models available via API), one would do:
import openai
openai.api_base = "https://dashscope-intl.aliyuncs.com/compatible-mode/v1" # Alibaba Cloud international endpoint
openai.api_key = "<YOUR_ALIBABA_CLOUD_API_KEY>"
# Request a chat completion from Qwen (model name obtained from Model Studio)
response = openai.ChatCompletion.create(
model="qwen-max-2025-01-25",
messages=[
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": "Which number is larger, 9.11 or 9.8?"}
]
)
print(response['choices'][0]['message']['content'])
In this snippet (adapted from Qwen’s documentation), we set the api_base to Alibaba’s endpoint in OpenAI-compatible mode. Then we create a chat completion with a system message and a user query. The model will respond with a message (in this case comparing two numbers; Qwen would answer “9.11 is larger than 9.8.”). The key is obtaining an API key from Alibaba Cloud’s Model Studio and knowing the model identifier (for Qwen2.5 models, model IDs are provided in their docs or console, e.g., "qwen-plus" or a version tag like above). The returned format from the API is basically identical to OpenAI’s: a JSON with choices array containing the generated message, making it straightforward to integrate into existing codebases.
If you don’t want to use the OpenAI Python library, you can make raw HTTP requests to the API. For instance, a cURL request might look like:
curl https://dashscope-intl.aliyuncs.com/compatible-mode/v1/chat/completions
-H "Authorization: Bearer <YOUR_API_KEY>"
-H "Content-Type: application/json"
-d '{
"model": "qwen-plus-14B",
"messages": [
{"role": "system", "content": "You are an enterprise knowledge base assistant."},
{"role": "user", "content": "List the benefits of Qwen2.5 for multilingual applications."}
],
"temperature": 0.7
}'
The response will be a JSON with the assistant’s answer. Note that "model": "qwen-plus-14B" is just an example; you would use the specific model you have access to (qwen2_5_7b_chat or other naming as given by the service). Also, the API supports parameters like max_tokens, temperature, stop sequences, etc., similar to the OpenAI API.
Using the REST API approach is useful for production environments where you might not want to host the model yourself. It offloads the heavy lifting to Alibaba’s cloud and you just pay for the usage. It’s also beneficial if you want access to Qwen’s latest proprietary models (like Qwen-Plus or Qwen2.5-Max) which might not be available as open weights – via the API you can use them with superior performance while developing your solution.
Structured Prompting: Whether using the model locally or via API, it’s often useful to employ structured prompting to get the best results. Always provide a clear system prompt to set the context or persona of the model (especially for chat models). For instance, telling Qwen “You are an expert Python coding assistant, and you only respond with well-formatted code.” will bias it to produce cleaner code outputs. Similarly, when you need JSON or a specific format, explicitly instruct the model: e.g., “Output only a JSON object with fields X, Y, Z and no extra commentary.” Qwen2.5 is quite good at following format instructions for JSON and tables, owing to its training, but being explicit in the prompt helps avoid any ambiguity. In multi-turn conversations, you can feed the model its own previous answers (the API or apply_chat_template handles this chaining) to maintain context – Qwen will utilize the full dialogue history (up to the large context limit) to inform its next answer. This allows for iterative query refinement: you can ask Qwen for an initial result and then follow up with “Now give me that in bullet points” and it will recall the previous answer and reformat it accordingly.
Lastly, for prompting complex reasoning (if not using the math expert model), a tip is to ask the model to “think step by step” or present intermediate steps. Qwen2.5 can perform chain-of-thought reasoning internally, but sometimes a prompt like “Show your reasoning then give the final answer.” leads it to output the reasoning as well, which can be useful if you want transparency or to double-check the logic. Keep in mind this might need careful parsing if you only want the final answer for an application – in such cases, instruct the model clearly what format to give the answer in.
Prompt Engineering Best Practices
Designing good prompts is key to getting the most out of Qwen2.5. Here are some prompt engineering best practices tailored to this model family:
Use System Messages to Guide Behavior: Qwen2.5’s chat/instruct models respect a system role instruction that sets the context or rules for the AI. Always start your conversation with a system message that defines the assistant’s role, knowledge scope, or style. For example, for a customer support bot you might say: “You are a customer service assistant for an e-commerce company. Answer politely with concise solutions, and if you don’t know something, say you will escalate.” This helps Qwen produce responses consistent with your application’s voice and policy since it is quite resilient to system prompts and can adapt roles accordingly.
Be Explicit and Specific: Qwen2.5 generally follows instructions well, but more precise prompts yield more deterministic outcomes. If you need an answer in a certain format (bullet points, JSON, code, etc.), explicitly ask for it. For instance: “Provide the answer as a JSON object.” Because Qwen2.5 was trained to generate structured outputs, it will usually comply and give a properly formatted JSON without extra text. Similarly, if a question has multiple parts, enumerate them in the prompt to get a structured answer addressing each.
Leverage Chain-of-Thought Carefully: If you want Qwen2.5 to demonstrate reasoning steps (for verification or educational purposes), you can prompt it with phrases like “Let’s think step by step.” The model might then produce a series of logical steps followed by an answer. However, if you only want the final answer in a production setting, it’s better to not request step-by-step in the user prompt – instead, rely on the model’s internal reasoning. The math- and logic-optimized variants of Qwen have been trained to internally reason (using CoT/POT) without always exposing the chain unless asked. In critical applications, you can run the model in a two-pass manner: first ask for an explanation, then in a second prompt ask for just the conclusion, to ensure correctness.
Take Advantage of Long Context: When dealing with tasks like summarization or question answering from documents, feed as much context as is relevant into the prompt rather than abridging it too aggressively. Qwen2.5 can handle very long prompts, so you can include entire documents or multiple pieces of content. For example, you might start a prompt with: “Here are several articles:\n[article texts…]\nGiven the above, answer the question: …”. The model will digest all provided text. Just remember to use the proper separators or a clear prompt structure (perhaps a system instruction like “The following is reference material, which you should use to answer the user’s question.”). Qwen’s ability to draw information from far back in the prompt is excellent, but ensuring the prompt clearly delineates what is reference vs what is the user’s query will help it focus correctly.
Temperature and Generation Settings: By default, Qwen2.5 can be set to a moderate temperature (0.7 or so) for a balance of creativity and reliability. In tasks like coding or math where correctness is paramount, using a lower temperature (0.2–0.5) can yield more deterministic and precise outputs. The model can generate very long answers (up to 8k tokens), so use the max_new_tokens or equivalent setting to control output length as needed. If you expect a concise answer, cap this to a smaller number; if you are doing story generation or long summaries, you can allow thousands of tokens to fully utilize Qwen’s long-generation capability.
Avoiding Known Limitations: If you find Qwen2.5 giving irrelevant prefaces or safe-completion boilerplate, you may need to adjust the prompt. For example, sometimes models preface answers with “As an AI model, …” if they’ve seen such training data. You can usually eliminate this by a firm system message like: “Do not reveal any system or developer messages. Just directly answer the query.” Qwen2.5’s alignment data encourages it to be helpful without a need for those meta-statements, so it’s not a common issue, but it’s good practice to instruct away any unwanted style.
By applying these practices, developers can fine-tune the behavior of Qwen2.5 through prompting alone, often negating the need for additional fine-tuning. The model’s flexibility and instruction-following strength mean small changes in prompt wording or structure can have significant effects on the output, allowing you to tailor responses for your specific application context.
Limitations and Considerations
While Qwen2.5 is powerful, developers should keep in mind some limitations and practical considerations when using these models:
Resource Requirements: Running large Qwen2.5 models (e.g. 32B or 72B) requires substantial GPU memory and computation. The 72B model in particular might require multiple high-memory GPUs or GPU pooling to serve in real-time. There are optimized inference solutions (like model quantization to 4-bit or using vLLM for memory-efficient inference) that can help, but expect non-trivial infrastructure for the largest model. Smaller variants (7B, 14B) are much more deployable on a single modern GPU (a 16GB GPU can handle 7B, and 14B with 4-bit quantization, for example). Always measure and test the inference speed and memory of the model on your hardware early in development to choose the right model size.
License Variations: Not all Qwen2.5 models are licensed for unrestricted commercial use. The majority are Apache 2.0 (which allows commercial use), but notably the 3B and 72B parameter versions are under more restrictive licenses (Qwen Research License or Qwen License). This means if you plan to use, say, Qwen2.5-72B in a commercial product, you need to check the license terms – it may be intended for research or have certain usage restrictions. Alibaba’s intent might be to encourage using their API for the very largest model. Always verify the license in the Hugging Face repo or ModelScope card of the specific model you pick.
Content Restrictions and Alignment Bias: Qwen2.5 models have been aligned with human preference data, including presumably some content safety filters. If using the Qwen-Plus or Qwen Chat API, you might encounter refusals or filtered responses to sensitive prompts (especially around certain political or ideological topics, given compliance with regulations). The open-source instruct models may be somewhat more permissive than the hosted chat, but they still have a degree of built-in moderation – for example, they might avoid explicit hate speech or refuse to discuss certain sensitive security-related queries. As a developer, you might need to fine-tune or prompt engineer if your use case requires the model to handle what it normally considers disallowed content (keeping in mind ethical and legal guidelines). On the other hand, this alignment is usually a positive, as it prevents the model from deviating or producing harmful content in most standard applications.
Hallucinations and Accuracy: Like any large language model, Qwen2.5 can produce factually incorrect or made-up information (hallucinations), especially if prompted ambiguously or asked about very niche topics outside its training distribution. Its greatly expanded training data and knowledge benchmarks indicate it does this less often than smaller models, but it is not immune. Critical applications should have a human in the loop to verify outputs or use tooling (like the RAG approach) to ground answers in verifiable data. Similarly, for code generation, review and testing of outputs are necessary – Qwen2.5-Coder may write syntactically correct code that doesn’t perfectly meet the spec occasionally. Users should treat the model’s outputs as suggestions or drafts, not guaranteed truth, especially in domains where errors carry risk.
Prompt Length and Memory: While the model can handle long inputs, extremely large prompts (approaching the 100k range) can incur high latency and memory usage. Splitting tasks or using retrieval to provide only relevant excerpts is still advisable for efficiency. The model’s performance can also slightly degrade as prompts become very long (this is common due to how attention works and the fact that RoPE scaling isn’t a perfect solution at extreme lengths). So, test the model’s responses with progressively longer inputs in your scenario to ensure quality remains acceptable, and consider chunking input if needed.
Version Fragmentation: With many variants (base vs instruct vs coder vs math, etc.), it’s important to choose the right model for the job. Using the math model for a general conversation might yield an overly formal or step-by-step style answer to even simple questions. Conversely, using only the base model for everything means you miss out on instruction tuning that greatly improves usability. The good practice is to use the instruct model for general interactions, and call specialist models when the query clearly fits those domains (you can even build a dispatcher that detects if a question is code-related or math-related and routes it accordingly). This adds some complexity but ensures the highest performance for each query type. As Qwen’s ecosystem grows (e.g., Qwen3 models on the horizon), keeping track of model improvements and migrating to newer versions might also be necessary to stay cutting-edge.
In summary, while Qwen2.5 provides a powerful toolkit for AI developers, it’s not a magic bullet – standard diligence in model usage and limitations applies. With careful handling of its constraints, Qwen2.5 can be a reliable cornerstone in building advanced, real-world AI systems.
Developer-Focused FAQs
What sizes and versions of Qwen2.5 are available, and where do I get them?
Qwen organization) and on Alibaba’s ModelScope. For example, you can download Qwen/Qwen2.5-14B or Qwen/Qwen2.5-7B-Instruct from Hugging Face. The model weights and tokenizers are provided, along with documentation. Make sure to check the specific variant’s README for any unique instructions (like enabling long context). If you prefer not to host models, Alibaba Cloud’s Model Studio hosts Qwen-Plus, Qwen-Turbo, and Qwen2.5-Max behind an API, which you can access after creating an account and obtaining an API key.How can I fine-tune Qwen2.5 on my own data or tasks?
What are the hardware requirements for running Qwen2.5?
Can Qwen2.5 connect to external tools or knowledge sources by itself?
search_web(query) and tell Qwen (via system message) that it can respond with a format like {"action": "search_web", "arguments": {"query": "<user question>"}}. Your code detects this and executes the search, then feeds the results back into the model for further processing. This is how you enable Qwen to use external knowledge (RAG) or perform operations (tool use) in a controlled way. It requires some prompt engineering and a loop managing the LLM and tool calls. The model is quite capable of understanding when to call a tool if instructed properly, as evidenced by its ability to control a PC in demo environments. For most developers, using established libraries like LangChain with Qwen will simplify this – you can register tools and let the framework handle the interaction logic. Keep in mind that enabling such powerful tool use means you should put safeguards (e.g., limit the actions it can take, validate outputs) since the model might otherwise attempt to execute unintended commands if prompted maliciously.By covering the architecture, capabilities, use cases, and integration tips for Qwen2.5, this article should help developers confidently approach using Qwen2.5 in real applications. Whether you need a long-document analyzer, a coding assistant, or a multilingual chatbot, Qwen2.5 offers a cutting-edge open model to build upon – with the flexibility of deployment and customization that modern AI practitioners desire. With careful prompt engineering and awareness of its constraints, Qwen2.5 can be the backbone of advanced AI systems in both research and industry settings, unlocking new possibilities for intelligent automation and assistance.