
Qwen2.5-Coder is a code-focused large language model (LLM) introduced by the Qwen team at Alibaba Cloud. It represents the latest generation in the Qwen series of open-source code models (formerly known as CodeQwen).
Unlike general-purpose LLMs, Qwen2.5-Coder is purpose-built for programming tasks – it has been trained on an extensive corpus of code and code-related data (over 5.5 trillion tokens of source code, code documentation, synthetic coding problems, etc.). This massive training, combined with advanced model architecture and instruction tuning, gives Qwen2.5-Coder state-of-the-art code generation and reasoning capabilities among open models.
In internal benchmarks it matches or exceeds the coding performance of much larger proprietary models, making it a powerful tool for developers. The Qwen2.5-Coder family includes multiple model sizes (ranging from 0.5B up to 32B parameters) to accommodate different resource constraints. Released under a permissive license (Apache-2.0 for most sizes), it is geared towards real-world use in coding assistants, developer tools, and automation frameworks.
In summary, Qwen2.5-Coder is an advanced open-source coding assistant LLM that produces high-quality code, supports complex reasoning, and integrates flexibly into engineering workflows.
Architecture Overview
At its core, Qwen2.5-Coder uses a Transformer architecture with several modern enhancements for efficiency and performance. It inherits the Qwen2.5 base architecture, which includes features like Rotary Positional Embeddings (RoPE) for handling long sequences, SwiGLU activation units, and RMSNorm normalization for training stability.
The model also employs a biased attention mechanism with Grouped Query/Key-Value heads (e.g. the 32B version has 40 query heads and 8 key-value heads), a technique that reduces memory usage while preserving model expressiveness. These architectural choices are similar to other modern LLMs (inspired by designs like Llama2), enabling Qwen2.5-Coder to scale up efficiently.
Model sizes and context: The Qwen2.5-Coder series spans six parameter scales: 0.5B, 1.5B, 3B, 7B, 14B, and 32B parameters. The largest 32B model has 64 Transformer layers and ~32.5 billion parameters (with ~31B non-embedding params). All model sizes support long input context lengths – smaller models allow up to 32k tokens, while the 7B and above models support contexts up to 128k tokens.
This unprecedented 128K token window (achieved via a RoPE scaling technique called YaRN) means Qwen2.5-Coder can ingest extremely large code files or even multi-file projects in one go. Such a long context is especially useful for analyzing large codebases or maintaining lengthy interactive coding sessions. (By default, the provided configuration is 32k; enabling the full 128k context requires a configuration tweak and specialized inference backend for optimal performance.)
Training and tuning: Qwen2.5-Coder was initialized from the general Qwen2.5 LLM and then further pretrained on code at scale. The pretraining dataset exceeds 5.5 trillion tokens and was carefully curated from public source code repositories (e.g. GitHub) and coding-related text from the web. The data was cleaned of low-quality or duplicate content and balanced across languages (including both widely-used and niche languages). Uniquely, the training strategy combined file-level and repository-level pretraining, meaning the model learned not just isolated code snippets but also how code is organized in larger projects.
After pretraining, the model underwent an instruction-tuning (post-training) phase. It was fine-tuned on a large set of coding problems and solutions, including both real-world examples and synthetic scenarios, to behave as a helpful coding assistant. This tuning teaches the model to follow natural language instructions, engage in dialogue, and perform tasks like explaining or fixing code when prompted. The result is the Instruct variant of Qwen2.5-Coder (Qwen2.5-Coder-32B-Instruct), which is optimized for conversational use and alignment with developer intents. (A Base variant without instruction tuning is also available for researchers who may want to fine-tune on their own data.)
Overall, Qwen2.5-Coder’s architecture and training make it a robust code-focused LLM that not only excels at generating code, but also retains strong general natural language and mathematical reasoning skills. This means it can understand complex programming instructions, reason about algorithms, and even handle logic or math components in code – all within a single model.
Supported Languages & Capabilities
One of Qwen2.5-Coder’s strengths is its broad multi-language support. Thanks to an extensive and balanced training corpus, the model is proficient in 40+ programming languages. It of course handles popular languages like Python, JavaScript, C/C++, Java, Go, and Rust with ease, but it also demonstrates competency in more niche or functional languages such as Haskell, Racket, Ruby, PHP, TypeScript, and many others.
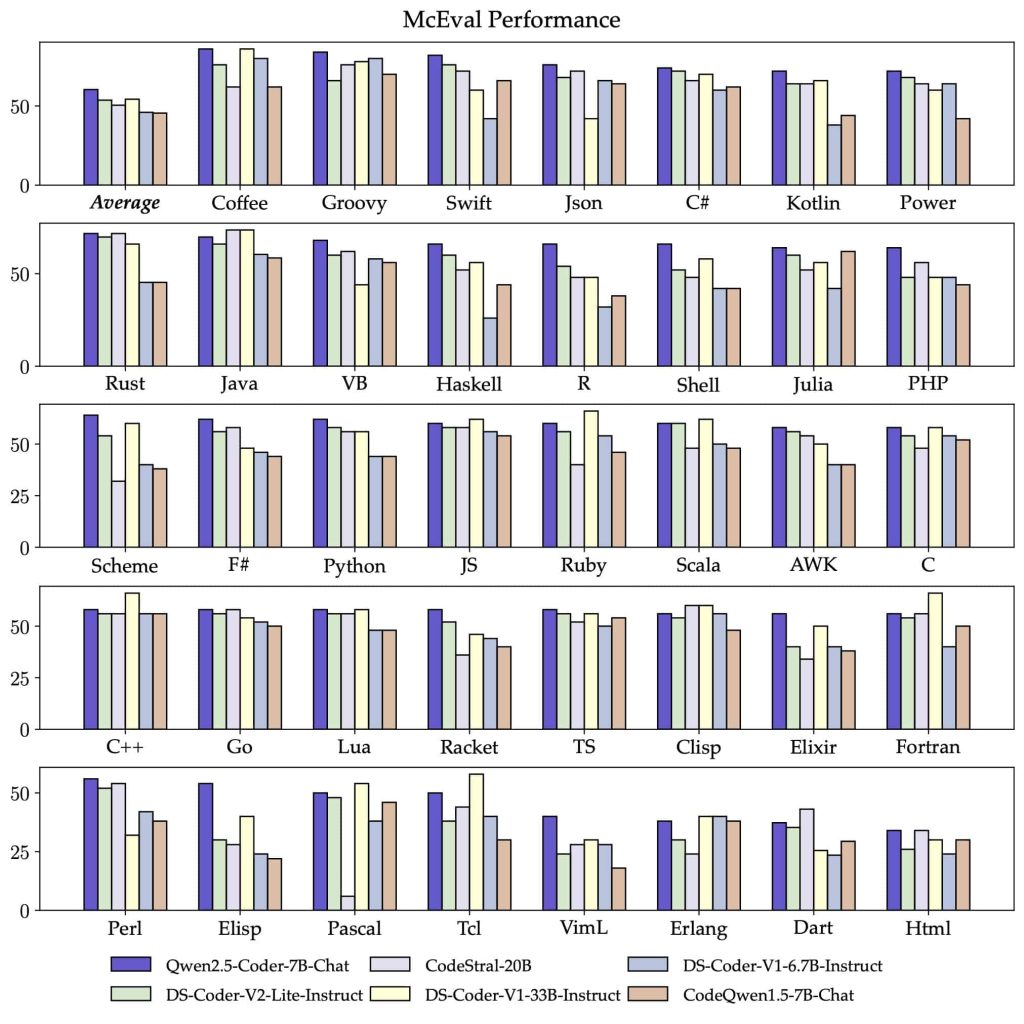
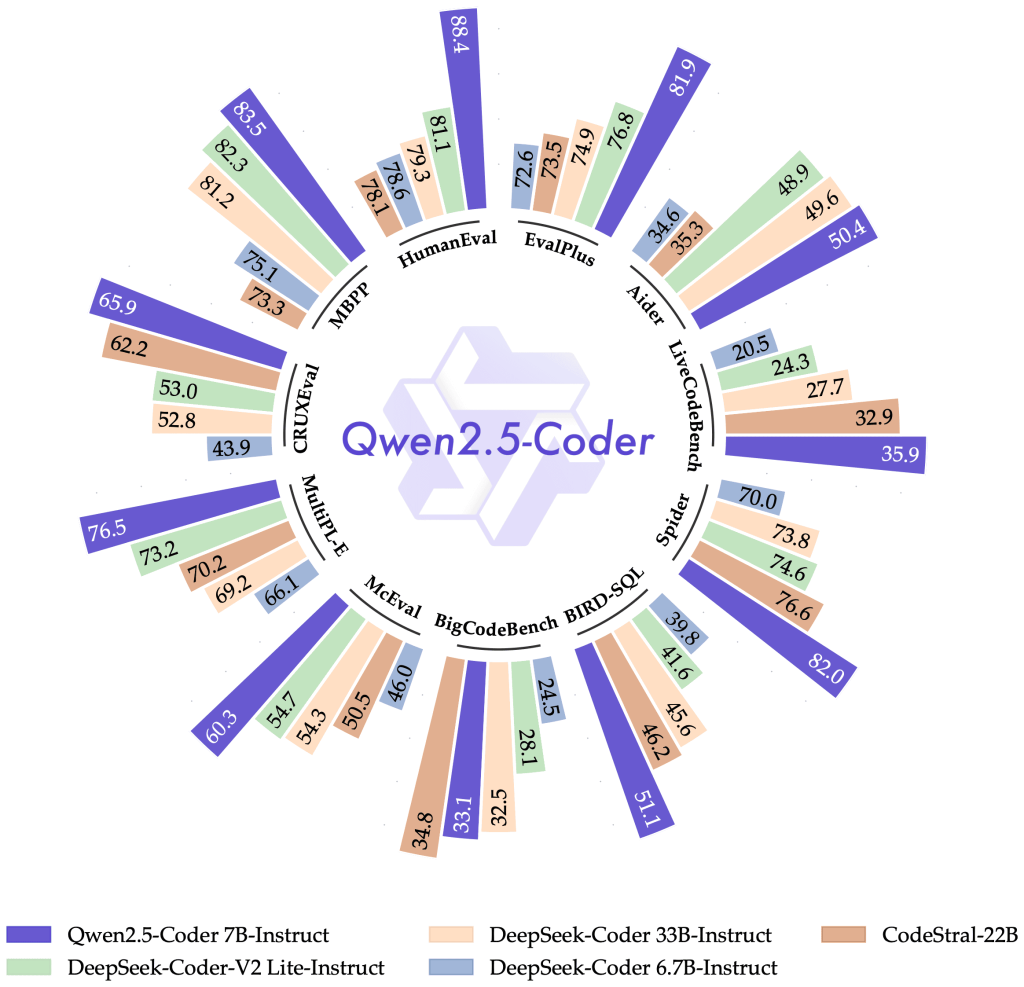
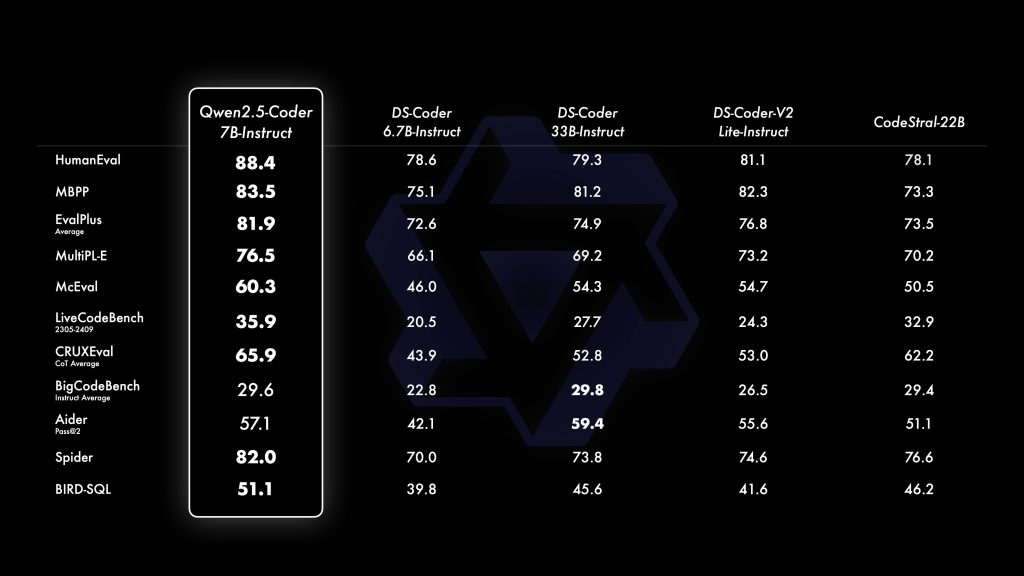
In benchmark tests, the 32B model performed excellently across this wide range of languages – for example, scoring 65.9 on the multi-language code eval suite McEval. This indicates a high accuracy in generating correct solutions in many languages, even those that are less common in typical training data. The team attributes this to careful data cleaning and balancing during pretraining, ensuring that no particular language dominated the corpus.
Importantly, Qwen2.5-Coder is not limited to one language at a time – it can also handle mixed-language contexts. For instance, it can read a codebase containing both Python and SQL files and reason about them together, or convert code from one language to another. This makes it suitable for tasks like cross-language code translation or working on polyglot projects. Additionally, the model retains strong capabilities in general natural language understanding and math.
This means you can intermix documentation or problem descriptions in plain English (or Chinese, etc.) with code, and Qwen will understand both. It can comprehend a user’s intent described in prose and then produce code to implement it, or read a code comment and elaborate on it. The preserved math skills are helpful for algorithmic code challenges or tasks like generating formula-heavy code.
In summary, Qwen2.5-Coder serves as a general-purpose coding assistant across many languages and domains. Whether you need to generate a Python script, debug a C++ snippet, optimize a Rust function, or even write a Haskell one-liner, Qwen is equipped to help. Its multilingual prowess also reduces the need for language-specific models – a single Qwen instance can assist across your entire stack. This versatility is particularly useful for full-stack developers and teams dealing with diverse codebases.
Key Features and Use Cases
Qwen2.5-Coder supports a variety of practical coding tasks out of the box. Below we highlight its key features and real-world use cases, from code generation and completion to debugging and DevOps automation:
Code Generation from Natural Language
General-purpose code generation is Qwen’s flagship capability. Given a description of a desired program or algorithm, Qwen2.5-Coder can produce the corresponding source code in a target language. For example, if you prompt with “Implement a quicksort algorithm in Python”, the model will generate a complete Python function (or even an entire program) that implements quicksort. It excels at translating high-level specs into code. Because it was instruction-tuned on diverse coding problems, it understands typical developer requests ranging from “create a REST API endpoint in Express.js” to “write a binary search in C++”.
The generated code is usually well-structured and commented if asked for. Qwen’s generation is not limited to toy examples – it can scaffold real-world applications (within reason for its context length), produce boilerplate for web frameworks, generate unit test cases, or even write infrastructure-as-code scripts. Many users leverage Qwen2.5-Coder as an AI pair-programmer: you describe the feature or function you need, and Qwen writes the initial draft implementation. This greatly accelerates prototyping and can save time on routine coding tasks.
Notably, Qwen2.5-Coder has demonstrated state-of-the-art performance on code generation benchmarks. It achieved the highest scores among open models on several popular coding challenges (like EvalPlus, LiveCodeBench, BigCodeBench). These benchmarks involve generating correct code for competitive programming problems and real-life coding tasks.
Qwen2.5’s 32B model consistently matched or even approached the solutions quality of top proprietary models. This means its code reasoning accuracy is vastly improved over earlier iterations, thanks to the large training corpus and advanced tuning. In practice, developers find that Qwen’s suggestions often work on the first try or require only minor tweaks – a testament to its code understanding.
Code Completion & Snippet Enhancement
Qwen2.5-Coder can act as an intelligent autocompletion engine, making it ideal for code completion and snippet enhancement. In an IDE setting, you can feed Qwen a partial snippet of code, and it will predict the continuation. Because Qwen is a causal language model, it was trained to predict next tokens in code, allowing it to complete unfinished lines, fill in boilerplate, or suggest the next logical code block. For instance, if you have:
def find_max(numbers):
# find the maximum number in the list
and you ask Qwen to complete it, it might output:
if not numbers:
return None
max_val = numbers[0]
for n in numbers:
if n > max_val:
max_val = n
return max_val
This goes beyond simple text autocompletion – Qwen infers the intent (finding the max in a list) and provides a correct and clean implementation. The model was evaluated on infilling tasks (like HumanEval-Infilling and other fill-in-the-middle challenges) and achieved state-of-the-art accuracy in code completion among open models.
It can perform middle-of-line completions (for example, completing a function call with the correct parameters) as well as multi-line continuations. It even handles the fill-in-the-middle scenario where code needs to be inserted in the middle of an existing file, thanks to training on special datasets for code infilling.
Beyond straightforward completion, Qwen can enhance and expand code snippets. You might provide a skeletal snippet and ask Qwen to “add error handling and comments” or “complete the TODOs”. The model will then generate the additional code to flesh out the snippet (e.g. try/except blocks, logging, etc.) as well as explanatory comments if requested.
This is extremely useful for increasing code quality with minimal effort. Qwen’s awareness of coding best practices means it often completes code in a way that follows typical conventions (like proper indentation, clear naming) without being explicitly told. In summary, Qwen2.5-Coder significantly boosts productivity by acting as a smart code completer – it can turn partial drafts into fully realized code.
Automated Debugging & Error Explanation
Another powerful use case is Qwen’s ability to serve as an automated debugging assistant. When you’re faced with a bug or an error trace, Qwen2.5-Coder can analyze the problematic code and explain what’s wrong, often pinpointing the bug and suggesting a fix. This feature stems from the model’s strong code reasoning and error-correction training.
For example, if you provide a Python function and an error message (say a TypeError or failing test case), you can prompt Qwen with: “The following code is not working as expected, can you find the bug and fix it?”. Qwen will examine the code logic and likely identify the issue (e.g. a wrong loop condition or a variable not initialized) and then output a corrected version of the code along with an explanation of the mistake.
Qwen2.5-Coder was evaluated on code repair benchmarks like Aider (which tests fixing buggy programs) and scored 73.7, performing comparably to top-tier models on automated bug fixing. It has a knack for interpreting stack traces and error logs – if you feed in an exception message and the code, it will explain the cause (for instance, “TypeError: can’t concatenate int to str” would prompt it to say you need to convert the int to string before concatenation).
Qwen can also catch logical bugs that don’t throw explicit errors: by reasoning through the code’s intended behavior, it can spot off-by-one errors, incorrect conditionals, inefficiencies, etc. The model’s responses to debugging queries are typically explanatory: it will list the issues it found, why they are problematic, and how to resolve them (often providing a patched code snippet). An example format might be:
- Bug: The loop never increments the index, causing an infinite loop.
- Impact: This will freeze the program.
- Fix: Increment the index inside the loop (
i += 1).
This structured output (as in the example) can be achieved by prompt engineering to get a list of bugs and fixes. Developers can leverage Qwen in their workflow by pasting a piece of non-working code and simply asking Qwen for help – it’s like having a seasoned engineer over your shoulder to do a quick code review and point out issues. It greatly speeds up troubleshooting and can help less experienced programmers learn why a bug occurred, not just how to fix it.
Code Refactoring and Optimization
Beyond writing and fixing code, Qwen2.5-Coder is also adept at refactoring and improving existing code. You can instruct the model to rewrite a given code segment to achieve certain goals: improve clarity, enhance performance, conform to style guidelines, etc.
Qwen will then output a refactored version of the code, often with changes like better variable names, simplified logic, added comments, or more idiomatic constructs. For example, you might say: “Here’s a function. Refactor it for better readability and efficiency.” – Qwen could respond by breaking down a monolithic function into smaller ones, removing redundant computations, or replacing a slow algorithm with a faster one, all while preserving the function’s behavior.
This capability is extremely useful for code maintenance and review. Qwen can act as a “code quality expert”, pointing out places where the code can be improved and even providing the improved code directly. For instance, it can suggest using list comprehensions to make Python code more concise, or highlight that a piece of code doesn’t follow PEP8 naming conventions.
In one example, a prompt was given to check code against standards (PEP8 compliance, naming, documentation, error handling), and Qwen listed specific violations and corrections for each category. This shows that Qwen not only generates code, but also understands software engineering best practices. It can enforce coding standards or optimize for performance if instructed.
Some practical scenarios include: converting a script into a well-structured module, optimizing a database query code for efficiency, adding docstrings to functions, or porting a snippet to use a different library in a more optimal way. Qwen’s refactoring suggestions often come with explanations (“I renamed variable x to user_count for clarity”, etc.), which is valuable for learning and justification. Of course, as with any automated refactoring tool, a developer should review the changes – but Qwen provides an excellent starting point and can handle the tedious parts of rewriting code according to guidelines.
CI/CD and Pipeline Automation
Qwen2.5-Coder’s utility isn’t limited to application code – it’s equally helpful in generating DevOps scripts, CI/CD configuration, and data pipelines. Many parts of modern software development involve writing YAML/JSON configs, shell scripts, or glue code for infrastructure. Qwen can significantly automate these tasks.
For example, if you need a GitHub Actions workflow for CI, you can prompt Qwen with a description of what you want (e.g. “Set up a CI pipeline that runs tests on Ubuntu latest, builds the Docker image, and deploys on success”). Qwen will produce a YAML configuration for GitHub Actions or a Jenkinsfile, etc., following the specified steps. It knows the syntax and schema of common CI/CD tools, so it can fill in the boilerplate (like triggers, job definitions, environment setup) that you would otherwise have to write manually. This is a huge time-saver for backend engineers setting up continuous integration pipelines.
Similarly, Qwen can generate Dockerfiles, Kubernetes manifests, Terraform scripts, and the like, given a high-level brief. Its knowledge extends to various infrastructure-as-code languages and formats because such files are often found in public repos used in its training. Need a Dockerfile for a Flask app? Describe your app and Qwen will write one, including best practices for layering and a .dockerignore if appropriate. Need a Terraform config for an AWS EC2 and RDS setup? Qwen can draft it out.
For data engineering workflows, Qwen shines in writing data pipeline code. You can ask it to create a Python script that reads from a CSV, transforms data using Pandas, and loads it into a database – Qwen will output a working ETL script. It can also help generate Airflow DAG configurations or SQL queries for data warehousing, etc. Essentially, tasks that involve stitching together different systems with code or config are made easier by Qwen’s broad knowledge.
This automation of boilerplate and configuration code accelerates DevOps cycles and reduces human error in writing these files. Many engineers use Qwen as a quick way to prototype their pipeline logic or config files, then adjust as needed for their environment. By handling the repetitive parts, Qwen lets developers focus on higher-level architecture rather than syntax details of CI/CD files.
Python Examples: Using Qwen2.5-Coder
Let’s look at some concrete Python examples of how to use Qwen2.5-Coder in practice. We will use the Hugging Face Transformers API to load the model and perform generation, completion, and debugging tasks.
Loading the model: First, install the transformers library (ensure version ≥ 4.37 for Qwen support). Then load the model and tokenizer:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-Coder-7B-Instruct" # using the 7B instruct model for example
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name, device_map="auto", torch_dtype="auto"
)
This code downloads the Qwen2.5-Coder model (7B parameter version) from Hugging Face and initializes it on your hardware (using device_map="auto" to spread across available GPUs or CPU automatically). For larger models like 32B, you’ll need a machine with sufficient GPU memory (or use 8-bit quantization to fit in less memory). Now, let’s generate some code.
Example 1: Generating code from a problem description. Suppose we want to generate a Python implementation of quicksort. We can prompt the model accordingly. Qwen’s instruct model expects a chat format with system/user roles, so we’ll prepare the input as a conversation:
prompt = "Write a Python function to perform quicksort on a list."
messages = [
{"role": "system", "content": "You are Qwen, a helpful coding assistant."},
{"role": "user", "content": prompt}
]
# Format the messages for the model (Qwen uses a special chat template)
text_input = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(text_input, return_tensors="pt").to(model.device)
# Generate the completion
output_ids = model.generate(**inputs, max_new_tokens=256)
generated_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print(generated_text)
When you run this, the model will output something like:
def quicksort(arr):
if len(arr) <= 1:
return arr
else:
pivot = arr[len(arr)//2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quicksort(left) + middle + quicksort(right)
It may also include an explanation if the prompt implied it; you can adjust the prompt to ask for only code if desired. In this example, Qwen generated a correct and idiomatic quicksort implementation. We used the system message to prime the model’s behavior (telling it to act as a helpful coding assistant), and the user message to provide our request. The helper apply_chat_template from Qwen’s tokenizer ensures the prompt is formatted with any special tokens the model expects. This is how you typically interact with Qwen2.5-Coder via the Python API for any task – assemble a messages list of the conversation, tokenize it, and call model.generate.
Example 2: Completing a partial code snippet. Let’s say we have started writing a function and want Qwen to complete it. We can do this by including the partial code in our prompt and instructing the model to continue. For instance:
partial_code = """\
def calculate_factorial(n):
# Base case
if n <= 1:
return 1
# Recursive case
"""
messages = [
{"role": "system", "content": "You are an expert Python coder."},
{"role": "user", "content": "Complete the following code:\n" + partial_code}
]
text_input = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = model.generate(**tokenizer(text_input, return_tensors="pt").to(model.device),
max_new_tokens=50)
completion = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(completion)
The model will produce something like:
return n * calculate_factorial(n-1)
This is exactly what we’d expect to complete the factorial function. Qwen looked at the context and continued the code appropriately. If the snippet had multiple TODOs or was more complex, Qwen would generate a longer completion. You can see how this could integrate with an IDE plugin to provide intelligent code autocomplete – Qwen can handle understanding the context (the base case was given, so it wrote the recursive case).
Example 3: Debugging and fixing code via the API. Suppose we have some buggy code and we want Qwen’s help to find the bug. We can include the code and ask for an analysis. For example:
buggy_code = """\
def add_numbers(a, b):
# This function should return the sum of a and b.
print("The sum is: " + a + b)
"""
question = f"Review the following code and identify any bugs:\n```python\n{buggy_code}\n```"
messages = [
{"role": "system", "content": "You are Qwen, a coding assistant who finds bugs."},
{"role": "user", "content": question}
]
text_input = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = model.generate(**tokenizer(text_input, return_tensors="pt").to(model.device),
max_new_tokens=150)
analysis = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(analysis)
The model might respond with an analysis like:
- Bug: The code tries to concatenate a string with integers (
a + b) which will raise a TypeError ifaorbare not strings. - Fix: Convert the numbers to strings or use
print(f"The sum is: {a + b}")for proper numeric addition.
And it could even provide a corrected code snippet:
def add_numbers(a, b):
# This function returns the sum of a and b.
result = a + b
print(f"The sum is: {result}")
return result
This demonstrates how to use Qwen to automate debugging. We simply gave it the code and asked for issues; Qwen’s answer (captured in the analysis string) contains both the identification of the error and a suggestion for fixing it. In practice, you might integrate this into a CI pipeline or a development bot: whenever tests fail or an error is encountered, feed the failing code and error message to Qwen, and get back a explanation or even a patched version of the code.
These examples illustrate basic usage via the Python API. Note that for all generation calls, you can adjust parameters like max_new_tokens (to control output length), temperature and top_p (to control randomness of the output), etc., as you would with any Transformers text generation model. For code tasks, you often want deterministic output, so using temperature=0.0 or a low temperature is recommended to get the most straightforward solution.
REST API Integration Examples
In a production or backend setting, you might not call the model directly from a script or notebook. Instead, you could deploy Qwen2.5-Coder as a service and interact with it via REST API calls. There are a few ways to set this up:
- Using a hosted service or cloud API: For instance, Alibaba Cloud or third-party providers (like Fireworks AI) offer endpoints for Qwen2.5-Coder. You would typically send an HTTP POST request with your prompt and receive the generated code in the response.
- Hosting your own server: You can wrap the Hugging Face pipeline or model in a web server (using FastAPI, Flask, etc.) and expose endpoints to your applications.
Example: Calling a Qwen API via HTTP. Suppose you have Qwen2.5-Coder running behind an API at https://api.mycompany.com/qwen-generate. A typical REST call might look like this (using curl for illustration):
curl -X POST https://api.mycompany.com/qwen-generate \
-H "Content-Type: application/json" \
-d '{
"prompt": "Generate a Python class for a simple HTTP server.",
"max_new_tokens": 200,
"temperature": 0.2
}'
This JSON payload includes the prompt and some generation parameters. The server (backed by Qwen) would return a JSON response containing the generated code, for example:
{
"code": "class SimpleHTTPServer:\n def __init__(self, host=\"localhost\", port=8000):\n ...\n"
}
Your backend application can then parse this JSON and use the "code" field. When designing such an API, it’s a good idea to include fields for the prompt, model options (like temperature, etc.), and to handle streaming if you want partial results.
Example: Building a simple Flask app for Qwen – If you want to self-host, here’s a minimal example of wrapping Qwen in a Flask server:
from flask import Flask, request, jsonify
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load the model and tokenizer globally (do this once to avoid re-loading per request)
model_name = "Qwen/Qwen2.5-Coder-7B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
app = Flask(__name__)
@app.route("/generate", methods=["POST"])
def generate_code():
data = request.get_json()
user_prompt = data.get("prompt", "")
# Format the prompt for Qwen instruct model
messages = [
{"role": "system", "content": "You are a coding assistant."},
{"role": "user", "content": user_prompt}
]
text_input = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(text_input, return_tensors="pt").to(model.device)
# Generate code
outputs = model.generate(**inputs, max_new_tokens=data.get("max_new_tokens", 300),
temperature=data.get("temperature", 0.0))
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
return jsonify({"code": result})
This Flask application exposes a /generate endpoint. A client can POST a JSON with a "prompt" and optional parameters; the app will return a JSON containing the "code" produced by Qwen. In a real setup, you’d want to add authentication and perhaps queueing, but this illustrates the core idea. You could similarly implement this with FastAPI for more robust features or deploy it behind an API gateway. Also consider using efficient inference servers like vLLM or Hugging Face Text Generation Inference for better performance in production (these can serve the model with optimized batching and memory management). The model card documentation notes that using vLLM is recommended for high-throughput long-text generation.
Once deployed, such an API makes it easy to integrate Qwen2.5-Coder into various systems: your IDE can call it for completions, your CI system can call it to auto-fix code, or a web app can call it to provide an “AI coding assistant” feature. The flexibility of a REST interface means any language (not just Python) can use Qwen’s power by making HTTP requests.
Agent-Style Coding and Iterative Workflows
A cutting-edge application of Qwen2.5-Coder is in building agent-style coding systems – autonomous or semi-autonomous agents that can write, execute, and refine code in iterative loops. Qwen’s strong coding capabilities and long context window make it an excellent foundation for such agents. In a typical agent workflow, the model doesn’t just produce code once; it goes through a cycle of generating code, testing it, observing results, and improving the code. This approach can automate tasks like solving competitive programming problems or even developing simple software projects with minimal human intervention.
For example, imagine an agent tasked with “create a function that parses a given log file and extracts error entries.” The agent’s loop might work like this:
- Generate initial solution – Qwen is prompted (with the problem description) to write a Python function for the task. It outputs some code.
- Test the code – The agent runs the generated function on sample input (this requires an execution environment outside the model, e.g. a sandbox or tools integration). Suppose the function crashes or doesn’t produce the expected output. The agent captures the error message or failing output.
- Analyze and refine – The agent then feeds the error information back into Qwen (along with the latest code) with a prompt like “The code didn’t work for X input; here is the error… please fix the code.” Qwen analyzes this and produces a revised code that addresses the issue (it might, for instance, add error handling or correct a logic bug).
- Repeat – The agent runs the new code again. This loop continues until the code works correctly for all tests or meets a certain confidence criterion.
Throughout this process, Qwen is effectively playing the role of both coder and debugger in an automated fashion. The agent part is the orchestration around Qwen: running code, feeding back results, and possibly making decisions on what test to try next. Qwen’s role is to reliably improve the code each iteration based on feedback. Because Qwen can maintain a long conversation (128k tokens context), you can keep the entire history of code versions and error logs in the prompt if needed, which provides context for each refinement step. This is a big advantage – the model can “remember” what was tried before and why it failed, guiding it toward a correct solution.
Additionally, Qwen2.5-Coder can be augmented with tool usage inside such agent frameworks. For instance, you might allow the agent to call a documentation lookup tool or a compiler. Qwen could be prompted to output a special token or command when it wants to use a tool (e.g. “[SEARCH] how to parse date in Python”), the agent intercepts that and performs the search, then feeds the result back into Qwen. This kind of tool integration turns Qwen into a more interactive problem-solver, enabling it to fetch external information or verify outputs. While Qwen doesn’t have built-in function-calling schemas, you can implement a protocol via prompt design (like checking the model’s output for certain markers). This concept is similar to how one might use GPT-style models in an AutoGPT-like setup, but here tailored for coding tasks.
In practical engineering use, agent-style coding can automate things like: generating code and continuously running unit tests until all tests pass, or reading an API spec and iteratively coding against it, debugging each error until success. Alibaba’s team hinted that Qwen2.5-Coder provides “a comprehensive foundation for real-world applications such as Code Agents”, and indeed its performance suggests it can drive such autonomous coding systems. Early experiments by users have shown Qwen-powered agents solving complex programming challenges end-to-end. For developers, this means you can delegate more of the trial-and-error coding process to the AI: rather than manually iterating, you supervise an agent that uses Qwen to do the heavy lifting. Although this field is nascent, Qwen2.5-Coder is an exciting engine to build upon for AI-driven software development.
Prompt Engineering for Coding Tasks
To get the best results from Qwen2.5-Coder, it’s important to craft your prompts effectively, especially for complex coding tasks. Here are some prompt engineering tips and patterns tailored to this model:
Use the system role to set context or persona: Qwen’s instruct models support a system message that influences behavior. For coding tasks, you might set the system prompt to define the assistant’s role, e.g. “You are an expert Python developer and mentor.” This can make the responses more targeted (expert tone, thorough explanations if needed). In a multi-turn session, the system message persists as a guiding context.
Be explicit about the task and format: Clearly ask for what you want. If you need only code, say “provide only the code without explanation.” If you expect an explanation, request it. For debugging, specify the format if needed – for instance, “List each bug with ‘- Bug: … Fix: …’ format” as shown in the earlier example. Qwen will follow structured instructions reliably. If you want a certain output format (like JSON or a markdown table), you can demonstrate or describe it in the prompt, and Qwen will usually comply.
Include relevant code or error messages in the prompt: When asking Qwen to act on existing code (to debug, refactor, review, etc.), always provide that code in the prompt. Use markdown triple backticks “` to encapsulate code; Qwen has likely seen this convention and it helps it distinguish code from description. Also include any error trace or example input/output that illustrates the problem. The more context you give, the better Qwen can reason about it. For instance, “Here is a function and an example where it fails, please fix the bug” works better if you actually show the failing input and output.
Leverage step-by-step reasoning for complex problems: If a coding problem is complex (e.g. algorithmic puzzles), you can prompt Qwen to “think step by step” or first outline a solution approach. This can lead to more coherent solutions. Qwen might first explain its plan (if instructed to show reasoning) and then present the code. This is analogous to prompting chain-of-thought in general LLMs. For example: “Explain your approach, then give the final code” can yield a useful breakdown followed by the code. (Just be mindful to separate explanation from code in the output as needed.)
Few-shot examples: If you have a very particular style or format you want (say a comment style or a certain way to structure answers), you can include a small example in the prompt. For instance: “Here is an example of a documented function:” followed by a short function with a docstring, then “Now document the following function in the same style:” followed by your target function. Qwen will mimic the style from the example. Few-shot prompting can also help in multi-step tasks, like first step output should be pseudo-code, second step actual code, etc., but usually Qwen’s instruction-following is strong enough that one clear instruction suffices.
Control randomness for reliability: As a prompt strategy, remember that setting the model’s generation parameters influences output. For deterministic needs (like getting a single correct solution), use a low temperature (0 to 0.3) and maybe disable sampling. For brainstorming multiple solutions or variations, a higher temperature can be used. This isn’t part of the prompt text per se, but it’s part of prompt configuration. For instance, if you want alternate implementations, you might call the model multiple times with slightly higher temperature or use num_return_sequences to get multiple completions and then choose the best.
Long context handling: If you plan to feed very long code (tens of thousands of tokens) into Qwen, consider chunking it or summarizing parts, because even though the model can handle up to 128k tokens, extremely long prompts may lead to very expensive inference and potential loss of focus. According to the documentation, enabling the long context (via the YaRN rope scaling) might slightly affect performance on shorter prompts. So use the long context mode only when needed. When working with long files, it can help to tell Qwen which part to focus on (e.g., “In the code below, focus on the function foo() and optimize it”).
In practice, Qwen2.5-Coder is quite forgiving – it was tuned on a variety of user instructions, so it often “knows” what you want with minimal prompting. Still, applying these prompt engineering techniques can make a big difference in getting outputs that are directly useful with minimal edits. As you interact, you can refine your prompts based on the model’s responses: if it’s not doing exactly what you want, clarify the instructions or add constraints. Qwen’s ability to have a back-and-forth dialogue means you can also correct it in subsequent turns (e.g. “Oops, that’s not quite right – please do X instead” and it will adjust). Effective prompting, combined with Qwen’s powerful model, gives a very capable coding assistant at your fingertips.
Performance Considerations
When using Qwen2.5-Coder in real projects, you should be mindful of performance in two senses: (1) model quality vs size trade-offs, and (2) computational performance (speed/memory).
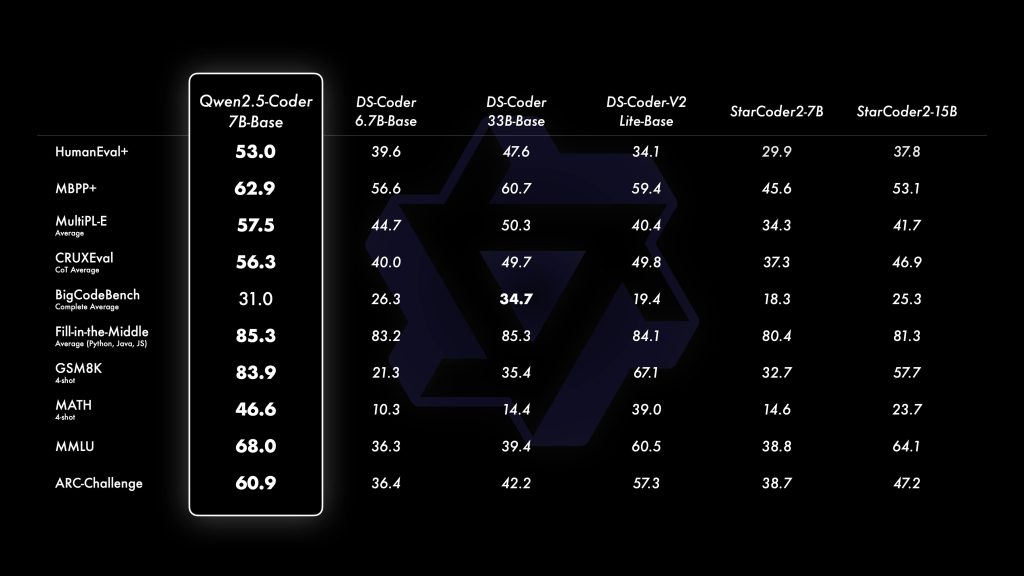
Quality vs model size: As with most model families, larger Qwen2.5-Coder models generally produce better results. The 32B model is the top performer – it has achieved SOTA results across many coding benchmarks and is on par with the best open models to date. The 14B and 7B versions also perform impressively for their size (significantly better than the previous generation CodeQwen1.5 models) but will lag the 32B on very complex tasks. If you need the highest code reasoning ability and can afford the compute, the 32B-Instruct is recommended for production use. However, 32B is resource-heavy (see below), so for prototyping or less demanding tasks you might opt for 7B or 14B. The Qwen team’s results show a clear scaling effect – larger models yield higher accuracy on code tasks across the board. Even the 0.5B and 1.5B models, while much weaker in absolute terms, might be useful in constrained environments or for simple code completions. In summary, choose the model size that balances quality with your deployment constraints. The good news is all sizes share the same architecture and training approach, so you can start with a smaller model and expect similar behavior, then scale up as needed for better results.
Hardware and speed: Running big code models requires serious hardware. The 32B model in full precision can demand ~60GB or more of GPU memory for inference. It’s typically run on at least an A100 80GB GPU or split across multiple GPUs. Fortunately, techniques like 8-bit and 4-bit quantization are supported, which can shrink memory usage substantially with only minor loss in quality. Many practitioners run Qwen2.5-Coder-32B with 4-bit quantization on a 24GB or 32GB GPU. The 7B model is much lighter – it can run on a single consumer GPU (like a 8-12GB GPU, or even on CPU at reduced speed). If you don’t have GPUs, you can still use the smaller Qwen models on CPU, but inference will be slow for large outputs. For instance, generating 100 tokens on the 7B model might take several seconds on CPU.
Throughput and latency: If you are integrating Qwen into interactive applications (like an IDE helper), latency is key. For faster response, prefer smaller models or run the model with optimized inference frameworks. The Qwen docs recommend using vLLM or other optimized servers for serving the model. These can give you near-linear scaling with batch size and better GPU memory utilization (through paged attention, etc.). Another tip is to limit the max_new_tokens to a reasonable length to bound the runtime (don’t always ask for 1000 tokens if you only need 100). Also consider enabling streaming: Qwen can start returning tokens as they are generated, which improves perceived latency for the end-user (the user starts seeing code appear token by token, rather than waiting for the whole completion). Streaming is supported if you build on top of libraries like FastAPI (using server-sent events) or certain cloud inference APIs.
Long context performance: Utilizing the full 128k token context is an amazing feature but comes at a heavy compute cost. The time and memory usage of Transformers scales roughly linearly with sequence length for generation (and quadratically for self-attention in context). Even though Qwen’s architecture is optimized, pushing beyond 32k context will slow things down and may require more GPUs. The usable context in practice might also be less if you expect the model to pay attention to everything – extremely long prompts could dilute focus. One strategy is to use the long context for specialized tasks (like codebase-wide analysis) but not for every request. Also, you might only activate the long context mode when needed (the model card suggests toggling the RoPE scaling config only when processing very long input to avoid small performance hits on shorter prompts). For most use cases, 8k or 32k tokens are plenty, and you’ll rarely need to hit 100k tokens of prompt.
Concurrency and scaling: In a multi-user scenario, you will want to leverage batching (serving multiple requests together) to maximize throughput on the GPU. The Hugging Face text-generation-inference server or vLLM can batch requests so that the GPU processes many in parallel. This keeps the GPU utilization high. If you expect high volume, consider deploying multiple replicas of the model behind a load balancer. Also monitor the token usage – if a particular user sends extremely large prompts frequently, it might affect others (you could set limits or charge more for heavy usage if offering a service).
Fine-tuning and customization: Qwen2.5-Coder supports efficient fine-tuning (the weights are open and models like the 32B allow LoRA fine-tunes). If you fine-tune Qwen on your company’s codebase or style, be aware that it can further improve accuracy on your specific domain, but it requires additional care to not overfit or introduce regressions. The Fireworks platform, for example, allows LoRA fine-tuning on Qwen to personalize it. Performance-wise, a fine-tuned model might require the same inference cost but give better answers in your context, which is a trade-off to consider.
In essence, Qwen2.5-Coder is a heavy-duty model when used at full scale – but with the right optimizations and model size choices, it can be deployed effectively. Always plan your infrastructure according to the model’s demands. The Qwen documentation provides guidance on memory and throughput at different batch sizes and hardware setups. With proper tuning, you can achieve snappy performance for interactive use or high throughput for batch workloads (like processing thousands of code files). Just remember that there’s a cost-quality trade-off: the closer you want to get to the maximal coding ability (32B model, long context), the more resources and time it will consume.
Limitations
While Qwen2.5-Coder is a powerful tool, it’s important to understand its limitations and failure modes to use it responsibly:
- Not guaranteed 100% correct or optimal: Qwen can produce syntactically correct and plausible code that sometimes may not solve the problem perfectly or may have edge-case bugs. It doesn’t perform actual code execution unless you integrate it with an agent. So, always verify the outputs (via tests or review) before deploying code it generates. For critical code (security-sensitive, etc.), thorough testing is essential. The model might also not always pick the most optimal solution (it might write an O(n^2) solution when an O(n) exists, for example, if the prompt doesn’t emphasize optimization).
- Knowledge cutoff and updates: The model’s knowledge comes from its training data (which, as of its release, covers up to 2024 in public code). It might not be aware of the very latest libraries, frameworks, or language changes introduced after that. For instance, if Python 3.12 introduced a new feature and you ask Qwen about it, it might not know it or might hallucinate. Similarly, if you use it to generate code against a cutting-edge API, double-check with official docs. In such cases, you might need to provide context or documentation to the model as part of the prompt.
- Possibility of code plagiarism: Qwen was trained on public GitHub code, which likely includes code under various licenses. The model might sometimes regurgitate snippets of verbatim code that it saw during training (especially for very common algorithms or if prompted with an exact known coding challenge). This can raise license or plagiarism concerns if the snippet is large and uniquely identifiable. The Qwen team did implement decontamination steps to avoid training on solutions of certain benchmark problems, but it’s not foolproof for the entire training set. Developers should be mindful if Qwen outputs a large chunk of well-formatted code instantly – it could be retrieved from memory. To mitigate this, you can ask the model to explain the code or modify it to ensure it’s not just copying blindly.
- Lack of guaranteed safe outputs: Although instruction-tuned, Qwen might not have the same level of reinforcement learning from human feedback (RLHF) as some closed models like ChatGPT. It tries to follow user intent closely. This means if a user asks for something malicious or unsafe (e.g. “write code to exploit X vulnerability”), Qwen might actually comply and produce it, since it doesn’t have a strong content filter publicly noted. Caution is advised to implement your own content filters if deploying publicly, to prevent misuse. On the other hand, Qwen also might occasionally refuse or give a safe completion if it detects something (its behavior on this isn’t fully documented in open source, but generally code models are less filtered than chat models).
- No built-in tool use or function calling: Unlike some chat models that have explicit APIs for tool use or can output function call JSONs, Qwen2.5-Coder doesn’t have a native notion of plugins or function-calling. It will treat everything as text. So any “agent” behavior has to be orchestrated externally (as we discussed in the agent section). It won’t, for example, automatically call an API to get data – it will only suggest code that might call that API. This isn’t really a flaw, but a design aspect to be aware of.
- Potential verbosity or deviation: Sometimes Qwen might include more explanation than you want, or vice versa. For instance, when you ask for code, it might also produce an explanation if not instructed clearly to output only code. This is usually solvable by prompt wording. Similarly, if it’s unsure, it might give multiple suggestions or a more verbose answer. This is part of its helpfulness trait. You may need to trim the response to extract the code if it mixes prose and code.
- Resource intensity: As noted, the largest model is hard to run without strong hardware. This is a practical limitation – not everyone can deploy the 32B model locally. Quantization helps but there’s a trade-off in speed. If using a cloud API, cost might become a factor for large volumes of code generation, since these models consume a lot of compute per token.
- Multi-turn consistency: In longer conversations about code, Qwen generally does well, but there can be instances where it loses track of earlier clarifications. For example, if you discuss a piece of code over 10 turns, you have to ensure each prompt includes the necessary context (the model sees the whole history, but it might prioritize the latest instructions). There’s a chance it might reintroduce an error that was previously fixed if the conversation branches. Keeping an eye on this and reiterating key points in the prompt when needed can help.
In summary, Qwen2.5-Coder is a tool, not a silver bullet. It greatly accelerates coding tasks and can produce impressive results, but it works best with a human in the loop for validation. By understanding its limits – knowledge cutoff, potential for mistakes, and how it should be integrated securely – developers can use Qwen effectively and safely. The open-source nature of Qwen means it’s also evolving; future versions or community fine-tunes might address some limitations (for example, better alignment or updated knowledge). As of now, being aware of these caveats ensures you use Qwen’s power wisely.
Developer-Focused FAQs
Who developed Qwen2.5-Coder and what is its status in the open-source community?
What programming languages and tasks can Qwen handle?
How can I fine-tune or customize Qwen2.5-Coder for my own needs?
peft library or similar. You’ll need a decent GPU setup (for 7B, a single GPU can suffice; for 32B, multiple GPUs or one with very high memory, or use gradient checkpointing). Make sure to have a curated dataset of Q&A or prompt-response pairs focusing on the behaviors you want – e.g., your company’s coding style, or Qwen responding with internal library usage. After fine-tuning, you merge or apply the LoRA weights, and you have a specialized model. Note that the Qwen license allows this and even distribution (just attribute the original model). One thing to keep in mind: the instruct models are already quite good, so fine-tuning might only be needed if you notice consistent deficiencies or if you want to embed proprietary knowledge (like internal API specifics) that the base model wouldn’t know. Always evaluate on a validation set to ensure you’re improving the model and not degrading its general ability. If fine-tuning is too heavy, you can also do prompt tuning or in-context learning – basically feeding some examples each time rather than altering weights. This costs prompt tokens but can sometimes achieve the needed adaptation without any training.What are the memory and compute requirements for running Qwen2.5-Coder?
The 32B model requires on the order of ~30-60 GB of GPU memory to run inference efficiently. In 16-bit precision, it’s at the higher end of that range; in 8-bit mode it comes down to ~35 GB; in 4-bit mode you might get it under ~20 GB. So typically, a single high-end GPU (like NVIDIA A100 40GB/80GB) or a pair of 24GB GPUs is used. In terms of CPU, if you try to run it, you’d need a lot of RAM and it would be extremely slow (not recommended for real use).
The 7B model is much lighter: ~14-16 GB in 16-bit (fits on a 16 GB GPU), and ~8 GB or less in 8-bit quant. This can run on consumer GPUs like an RTX 3090 or even a 3080 (with some layers offloaded). The 7B can also run on CPU for non-real-time use; expect perhaps 1-2 tokens per second on a strong CPU.
Intermediate sizes (14B, 3B, etc.) scale accordingly. The 14B model needs roughly 28-30 GB (fp16) or ~15 GB (8-bit). The 3B and 1.5B models are very small: 3B can run in a few GB of memory, suitable for smaller devices or multiple instances.
In terms of raw compute, Qwen uses standard Transformer computation – the bigger factor is the context length. If you use long contexts (e.g. 32k or more), ensure you have enough memory not just for the model weights but for the attention kv cache which scales with sequence length. Also consider the generation speed: larger models generate slower (more layers to process each token). For instance, 32B might generate ~5-10 tokens/sec on an A100 GPU (just an illustrative figure), whereas 7B might do ~20-50 tokens/sec on the same GPU. These are rough; actual speed depends on implementation optimizations. To improve throughput, using multiple GPUs in parallel (model parallelism) is possible for the largest model – the Hugging Face loader with
device_map="auto" can split layers across GPUs, and frameworks like DeepSpeed can help. Also, using FP16 vs BF16 vs INT8 – BF16/FP16 are similar for modern GPUs, INT8 (8-bit) gives slight speed benefit and big memory save with minimal quality loss, and INT4 gives huge memory save but maybe a tiny quality hit.