
Qwen 3 is the latest generation of large language models (LLMs) in the Qwen series, developed by Alibaba Group and released in April 2025. It is an open-source foundation model family (Apache 2.0 license) designed for advanced AI applications, featuring hybrid reasoning capabilities and broad multilingual support across 119 languages and dialects.
Qwen 3 emphasizes technical improvements in architecture and training to achieve state-of-the-art performance on complex tasks such as coding, mathematical reasoning, and agent-driven automation. This article provides a comprehensive, developer-focused overview of Qwen 3 – covering its architecture, key features, multilingual capabilities, benchmark performance, and guidance on integration (with code examples for Python and API usage).
The goal is to help software engineers and AI researchers leverage Qwen 3 effectively for building advanced LLM-powered systems in enterprise settings, without marketing fluff or beginner-level explanations.
Architecture Overview
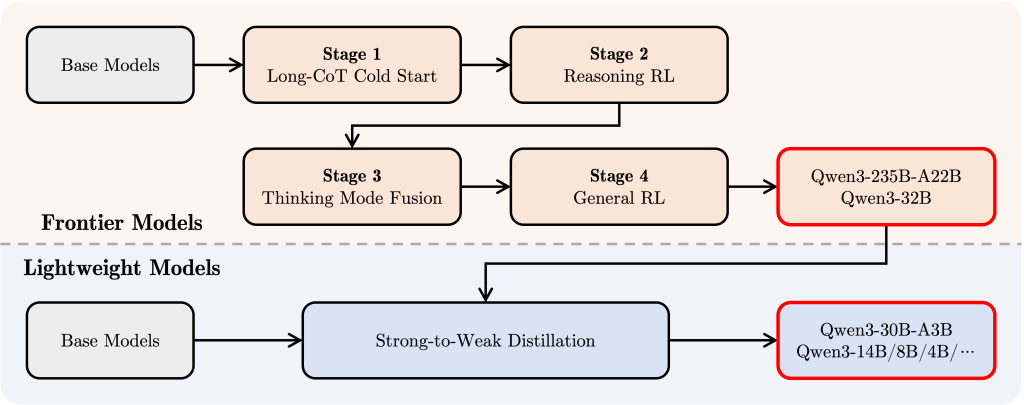
Model Suite: The Qwen 3 release includes a suite of both dense and Mixture-of-Experts (MoE) models, spanning parameter scales from 0.6 billion up to 235 billion. Six dense models (0.6B, 1.7B, 4B, 8B, 14B, 32B) and two MoE models (30B total with ~3B active, and 235B total with ~22B active) are provided.
The flagship Qwen3-235B-A22B model uses an MoE architecture with 235B parameters in total but only ~22B parameters activated per token during inference. This design allows the largest model to achieve high accuracy while keeping runtime costs closer to a 22B model by routing tokens through a subset of experts. All models support long context lengths (most up to 128K tokens natively) to handle very large inputs or documents.
The smaller 0.6B–4B models use a 32K context, whereas 8B and above support 128K tokens via specialized position encoding techniques. Such extended context windows enable processing of lengthy texts (e.g. multi-page documents or code files) within a single prompt.
Transformer Backbone: Qwen 3’s architecture builds on a transformer decoder backbone with several advanced components for performance and stability.
The dense models use Grouped Query Attention (GQA) for efficient scaling of attention heads, SwiGLU activation functions, and Rotary Positional Embeddings (RoPE) for handling long sequences. Layer normalization is done via RMSNorm in a pre-normalization setup. Qwen 3 also introduced QK-Norm in the attention mechanism (replacing Qwen2’s QKV bias) to stabilize training of very deep models. These architectural choices improve training convergence and inference stability for the new models. The MoE variants share the same transformer backbone as the dense models, but incorporate 128 experts per MoE layer (with 8 experts activated per token) using fine-grained expert routing.
Qwen 3’s MoE design removed the shared experts that earlier versions had, and uses a global batch load-balancing loss to encourage each expert to specialize. This results in significant efficiency gains: the MoE models can match or exceed the performance of much larger dense models while using a fraction of the active parameters (≈10% in practice). The variety of model scales and the hybrid dense/MoE approach means developers can choose a Qwen 3 model that fits their task and infrastructure constraints – from lightweight 0.6B models for constrained environments to the 235B MoE model for maximum accuracy.
Hybrid Reasoning Modes: A key innovation in Qwen 3’s architecture is the integration of two reasoning modes – “thinking” mode and “non-thinking” mode – into a single unified model framework. This concept, sometimes called hybrid thinking, allows Qwen 3 to dynamically switch between a step-by-step reasoning process and a fast intuitive response process depending on the query. In Thinking Mode, the model internally produces a chain-of-thought (detailed reasoning steps) before the final answer, which improves performance on complex, multi-step problems (e.g. math proofs, code generation) at the cost of extra compute time.
In Non-Thinking Mode, the model skips the lengthy reasoning and responds immediately based on context, which is ideal for straightforward queries or casual dialogue where speed is paramount. Crucially, both modes live within the same model weights – there is no need to swap to a different “reasoning-specialized” model for complex tasks, unlike prior setups (which might use one model for chat and another for reasoning). Qwen 3 uses a special token-based mechanism to delineate the internal reasoning content (enclosed in <think>...</think> tags) and the final answer in its outputs. This unified architecture with dynamic mode switching means the model can adapt its thought process on the fly per query or even per turn in a conversation.
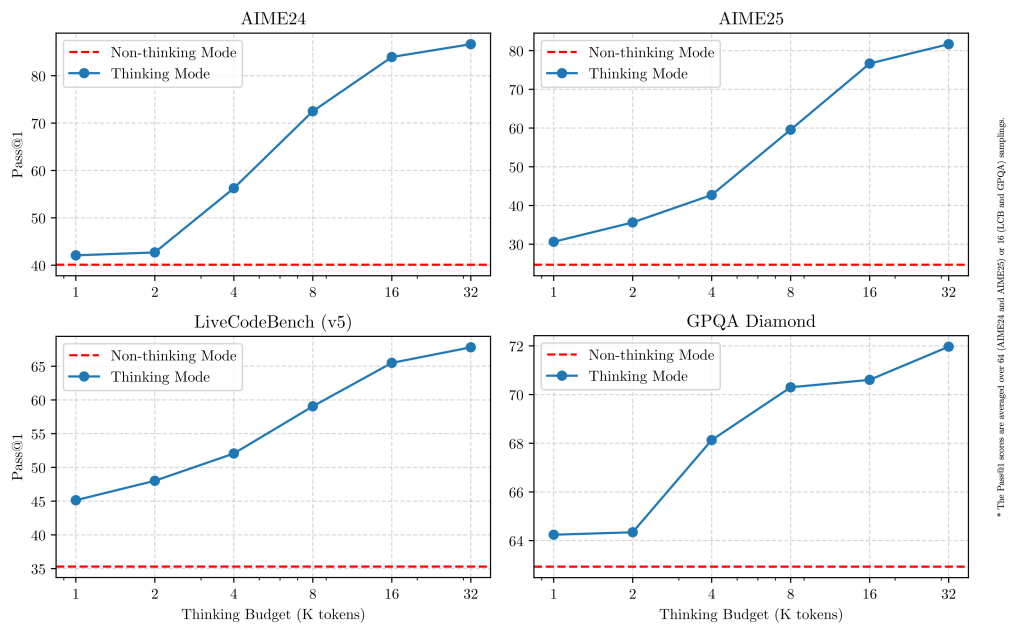
Thinking Budget Mechanism: Along with hybrid modes, Qwen 3 introduces a thinking budget feature that gives developers granular control over the amount of reasoning the model performs. Essentially, the model (or user) can allocate a certain budget of computation or reasoning steps for a query. A higher thinking budget allows deeper reasoning (engaging the thinking mode for more tokens), improving accuracy on complex tasks, whereas a lower budget yields faster, shorter responses. This mechanism helps balance latency vs. performance.
For instance, in production one might set a low budget (or disable thinking) for simple interactive prompts to ensure quick responses, but allow an expanded budget for particularly difficult questions or offline analyses. Empirical tests show that increasing the thinking budget consistently improves task performance, albeit with diminishing returns and increased inference time. The ability to adjust this at inference time is a novel feature – it provides a knob to trade-off speed and accuracy dynamically based on application requirements.
In summary, Qwen 3’s architecture is engineered for flexibility and efficiency: it offers a wide range of model sizes, supports extremely long contexts, combines MoE scalability with dense-model simplicity, and uniquely merges dual reasoning paradigms in one model. These advances collectively allow developers to deploy Qwen 3 in various scenarios without having to maintain multiple specialized models.
Model Features & Improvements
Qwen 3 brings significant new features and improvements over previous generations, targeted at enhancing reasoning capability, usability, and multi-domain performance. Key advancements include:
- Unified Reasoning Modes: As described above, Qwen 3 can seamlessly operate in both an analytical thinking mode and a fast non-thinking mode within a single model. This hybrid approach is unique in open-source LLMs – it enables optimal performance across scenarios by using deep reasoning only when necessary. Developers can explicitly toggle the mode or let the model decide based on the prompt (more on control in later sections). This design eliminates the need for separate models for complex reasoning versus casual dialogue, simplifying the deployment stack.
- Enhanced Reasoning & Performance: The reasoning capabilities of Qwen 3 are significantly enhanced through its training pipeline and architecture. In thinking mode, it surpasses prior specialized reasoning models on tasks involving math, logic, and code solutions. In non-thinking mode (general instruct/chat style), it also improves over the previous generation in following instructions and producing coherent answers. Thanks to extensive fine-tuning (including chain-of-thought datasets and reinforcement learning), Qwen 3 achieves strong results on challenging benchmarks that test problem-solving. It excelled in official evaluations for coding, mathematical problem solving, and agent planning tasks, often reaching state-of-the-art levels for an open model. Another area of improvement is human alignment – Qwen 3 was optimized with human preference data to produce more helpful and natural conversational responses in multi-turn dialogues, creative writing, and role-playing contexts. This means developers can expect more user-friendly outputs out-of-the-box, without sacrificing the model’s core reasoning power.
- Agentic Tool Use: The Qwen 3 models are explicitly tuned for agent behavior and tool integration. They demonstrate advanced “agentic” capabilities, meaning the model can plan actions, call external tools or APIs, and incorporate the results into its answers. The Qwen team has strengthened support for the Model Context Protocol (MCP) in this generation, which is a standardized way for the model to interact with external tool plugins via a defined interface. This makes it easier and more reliable to build AI agents that use Qwen 3 as the brain: for example, the model can decide to use a calculator tool for a math query, or call a web search API when asked a factual question. Compared to naive prompt-and-parse methods, MCP provides a robust channel for tool usage, reducing the brittleness of parsing model outputs to trigger actions. In practice, Qwen 3 (especially the instruct variants) can generate a JSON-like invocation for a tool when needed, and handle the tool’s response in a secure, structured way. These capabilities allow Qwen 3 to achieve leading performance among open-source models on complex agent-based tasks, as noted by the Qwen team. Developers building autonomous agents, RPA (robotic process automation), or other AI assistants will benefit from Qwen 3’s native tool-use skills and the official Qwen-Agent framework (discussed later) that wraps these abilities with convenient APIs.
- Extended Context and Memory: Most Qwen 3 models support a 128,000 token context window, dramatically higher than the typical 2K–32K contexts of many LLMs. This allows the model to attend to very large inputs or conversation histories. For example, Qwen 3 can ingest long technical documents, multi-chapter books, or months of chat history and still produce coherent responses that consider the entire context. The model uses efficient positional encoding (like segmented RoPE with extrapolation) to maintain performance at these lengths. In tests, Qwen 3 was able to process and summarize documents tens of thousands of tokens long, which is highly beneficial for enterprise use cases like analyzing lengthy reports or logs. Additionally, the architecture improvements (like removing context-length biases and using QK-normalization) help maintain stable behavior even as the sequence length grows, avoiding the degradation some models face with very long input.
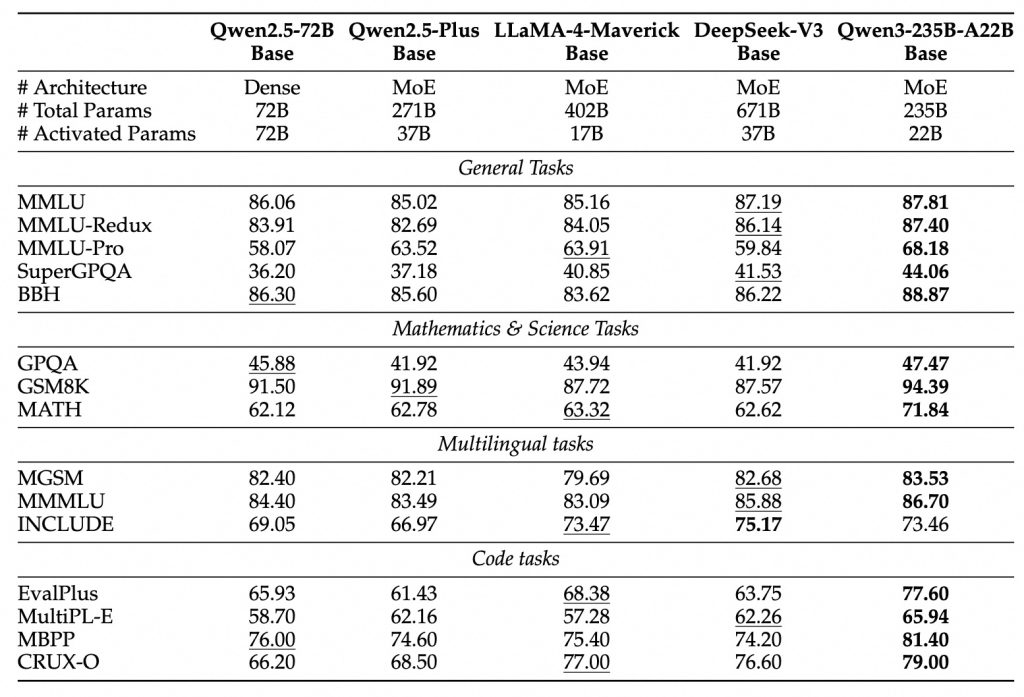
- Efficiency and Smaller Models: Although Qwen 3 introduced very large models, it also focused on efficiency gains so that smaller models perform better relative to their size. Through knowledge distillation from the flagship models and more effective training, the Qwen 3 base models match or exceed the performance of much larger Qwen 2.x models. For instance, the 4B parameter Qwen3 can rival the capabilities of a previous 30B+ model on many tasks. Similarly, the 30B MoE model (with 3B active) outperforms a dense 32B model that uses ~10× more active parameters. These improvements mean developers with limited compute can utilize Qwen 3’s smaller variants and still get strong results. All Qwen 3 model weights are publicly available, enabling the community to run and fine-tune even the largest models on high-end GPUs or multi-GPU setups, while smaller ones can run on a single modern GPU.
Overall, Qwen 3 delivers a professional-grade model with a rich feature set: it marries deep reasoning and speed, has built-in tool use proficiency, handles many languages and long texts, and is optimized for real-world application needs (robustness, alignment, efficiency). Next, we delve deeper into two critical aspects – its multilingual capabilities and the benchmark results demonstrating its reasoning performance.
Multilingual Capabilities
One of the standout features of Qwen 3 is its extensive multilingual support. The model was trained on a corpus covering 119 languages and dialects, a huge leap from the ~30 languages covered by its predecessor. This expansion was achieved by nearly doubling the training data to 36 trillion tokens and incorporating diverse sources in many languages. As a result, Qwen 3 possesses a strong understanding of languages spanning dozens of language families.
For example, it can comprehend and generate text in major Indo-European languages (English, Spanish, French, German, Russian, Hindi, etc.), Sino-Tibetan languages (Simplified and Traditional Chinese, Cantonese, Burmese), Afro-Asiatic languages (Arabic dialects, Hebrew), Austronesian languages (Indonesian, Malay, Filipino Tagalog), as well as Japanese, Korean, and many others. This broad coverage includes not just high-resource languages but also many low-resource or regional dialects, making Qwen 3 a truly global model.
In practical terms, Qwen 3 can be used for multilingual tasks such as translation, cross-lingual question answering, or content generation in the user’s native language. During fine-tuning, special attention was paid to improving cross-lingual understanding and generation, so the model can often transfer knowledge between languages effectively. For instance, you could prompt Qwen 3 in English to explain a concept and then ask it to provide the answer in Spanish or Chinese, and it will reliably do so.
It also supports mixed-language inputs and code-switching scenarios. The model’s instruction-following abilities extend to multiple languages – it was aligned on multilingual instruction data so that it can follow user directions in languages other than English fluently. Official evaluations have shown Qwen 3 performing strongly on multilingual benchmarks and translation tasks (it can serve as a general-purpose translation system across its supported languages).
For developers, this wide multilingual capacity means Qwen 3 can power applications for international user bases out of the box. Whether it’s building a customer support chatbot that understands users from different regions, or summarizing documents in various languages, Qwen 3 reduces the need for separate language-specific models. All supported languages share a single tokenizer (with a 151k vocabulary using byte-level BPE encoding), which efficiently handles different scripts (Latin, Chinese characters, Arabic script, Cyrillic, etc.). The model’s training on PDF and web data from many languages also gives it exposure to diverse formats and content styles.
That said, the quality will vary by language – generally very high for languages with abundant data (English, Chinese, etc.), and still decent for many others thanks to the large-scale data augmentation. Developers should keep in mind any language-specific nuances or formatting; for best results, instructions and context should be given in the same language as the desired output when possible.
In summary, Qwen 3 is a truly multilingual LLM. It enables advanced NLP applications across different locales without requiring separate models. This capability is especially valuable in enterprise settings where data and users may be spread globally – Qwen 3 can unify these use cases with one model that understands them all.
Performance & Reasoning Benchmarks
The Qwen 3 models have been tested on a wide range of standard benchmarks, and the results show state-of-the-art performance among open-source LLMs in many categories. Thanks to its hybrid reasoning training (and massive token budget during training), Qwen 3 demonstrates strong capabilities in code generation, mathematical reasoning, logical inference, and complex planning tasks.
According to the official technical report, the flagship Qwen3-235B achieves top-tier results that are competitive with much larger proprietary models. Notably, Qwen 3 excels at:
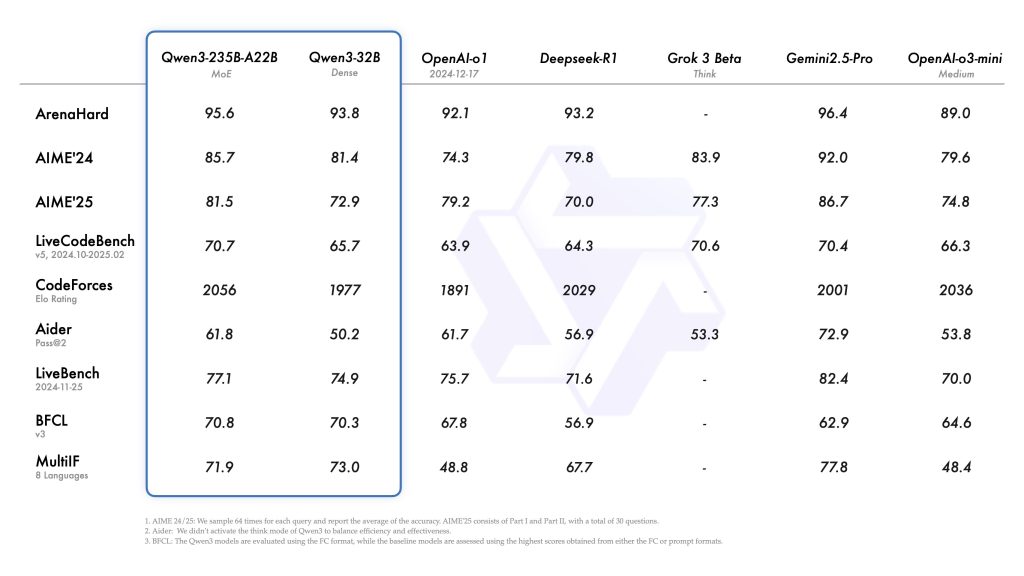
Coding Tasks: On code generation and programming challenges, Qwen 3 is one of the leading open models. For example, it scored 70.7 on the LiveCodeBench v5 coding benchmark and solved problems achieving a score of 2056 on the CodeForces programming competition evaluation. These scores indicate a very high competency in generating correct code and solving algorithmic problems. Qwen 3’s performance on coding benchmarks is close to specialized code models, making it suitable as a general-purpose coding assistant or for backend code generation services.
Mathematical & Logical Reasoning: Qwen 3 also ranks highly on math reasoning benchmarks. The flagship model achieved 85.7 on AIME’24 and 81.5 on AIME’25, which are competition-level math exam datasets. These results are on par with or better than many models solely optimized for math. The model’s chain-of-thought abilities allow it to break down complex problems (like multi-step arithmetic or logical puzzles) effectively. In commonsense and logical reasoning tests (e.g. puzzles, deductive reasoning tasks), Qwen 3 similarly shows excellent performance, often outperforming earlier open models.
Agent and Planning Tasks: By integrating agentic behavior into training, Qwen 3 performs very well on benchmarks designed for tool use and decision-making. Internal evaluations cited in the technical report indicate it outperforms other open-source LLMs on complex agent tasks, especially when allowed to use its thinking mode and tool-calling abilities. This includes tasks like interactive decision-making games, question answering with retrieval, and multi-step tool-using challenges. Essentially, Qwen 3 can “think” through multi-turn tasks and decide on actions nearly as well as some proprietary agent models. This makes it a great choice for building autonomous agents that need high success rates on benchmarks and real-world scenarios.
Perhaps more impressively, the smaller Qwen 3 models also show strong results relative to their size. The 30B-MoE model, for instance, was reported to outperform a dense 30B model and even rival a 60-70B class model on various tasks despite using far fewer active parameters. Even the tiny Qwen3-4B can match or beat older 7B–13B models on many benchmarks. This speaks to the efficiency of the new architecture and training regimen. For developers, it means if deploying the largest model is impractical, one of the mid-sized models (e.g. 14B or 8B) might still give excellent performance for your needs.
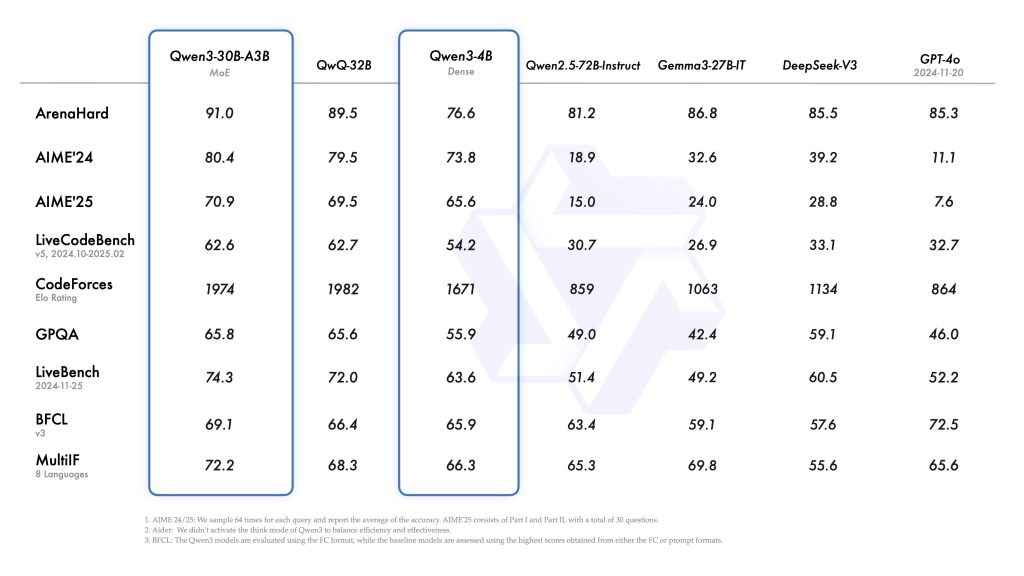
It’s important to use the official benchmarks as a guide to what tasks Qwen 3 is strongest in. In summary, those are code, math/STEM reasoning, multilingual QA, and agentic tasks. The model is also very capable at general NLP benchmarks (Summarization, open-domain QA, etc.), often ranking at or near the top among open models in 2025. When considering Qwen 3 for an application, reviewing these benchmarks can help set expectations. Of course, real-world performance will depend on prompt design and whether the model’s training covered the domain sufficiently, but the benchmark excellence is a promising indicator.
Supported Use Cases and Workflows
Given its capabilities, Qwen 3 is suitable for a wide spectrum of enterprise-grade use cases. Below we highlight several categories of applications and how Qwen 3 can be leveraged in each:
- Intelligent Agents & Automation: Qwen 3 shines in building AI agents that can automate tasks by interacting with tools and services. Using the Qwen-Agent framework (which wraps Qwen 3’s tool use abilities), developers can create agents for tasks like IT automation, data retrieval, or customer service. For example, an agent built on Qwen 3 could take a user request, decide to call internal APIs or run database queries (via tools) to gather information, and then return a synthesized answer. The Model Context Protocol (MCP) integration means such an agent can robustly call tools with standardized requests. In a business setting, you might deploy a Qwen 3 agent to handle routine support tickets by consulting knowledge bases (RAG workflow with retrieval), or to monitor and respond to events (taking actions through provided tool plugins). The combination of strong reasoning and tool skills allows Qwen 3 to perform multi-step workflows autonomously – essentially functioning as the “brain” in an RPA pipeline or an AI assistant that can act on the user’s behalf. Early adopters have noted that Qwen 3’s native tool usage (with proper prompting or the agent API) is much cleaner and more reliable than manually parsing model outputs for tool calls. This makes Qwen 3 a compelling choice for complex automation tasks that require both natural language understanding and backend integration.
- Backend AI Services (NLU/NLG): Qwen 3 can be deployed as a general-purpose AI service in backend systems, providing advanced natural language understanding (NLU) and natural language generation (NLG) capabilities. Because it’s open-source and can be self-hosted, enterprises can run Qwen 3 on-premises (ensuring data privacy) and use it for tasks like document analysis, report generation, or internal knowledge-base Q&A. For instance, an enterprise might use Qwen 3 to power an internal chatbot that answers employees’ questions by analyzing internal documents (using Retrieval-Augmented Generation to fetch relevant text). Qwen 3’s long context window is advantageous here – it can take in a long policy document or a large set of logs and produce a concise summary or answer queries about them. Unlike smaller models, Qwen 3 might not need an external summarization step for moderately large inputs due to the 128K token capacity. Additionally, its multilingual understanding allows a single deployment to service queries in multiple languages, which is useful for multinational companies. The Apache 2.0 license permits commercial use and modification, so enterprises can integrate Qwen 3 freely into their products or workflows without licensing concerns.
- Code Assistance and Data Processing: With its strong coding abilities, Qwen 3 can serve as a AI coding assistant or code generation service. It can help developers by generating code snippets, debugging, explaining code, or even writing simple programs given a description. Qwen 3 was tuned on a large volume of code (including synthetic code data generated by a code-specialized model), so it knows multiple programming languages and can adhere to typical coding styles. Integrating Qwen 3 into IDE plugins or devops tools could automate parts of the development process (similar to how GitHub Copilot works, but with an open model you can host yourself). Beyond code, Qwen 3’s multi-step reasoning is great for data processing tasks – for example, you can prompt it to analyze a dataset (provided as text or CSV content within the context) and it can compute summaries or transformations. It can also function as a conversational data analyst: with the help of a code interpreter tool (available via Qwen-Agent), the model could generate and execute Python code for data analysis and then explain the results. This opens up use cases like interactive data exploration in natural language or automating report generation from raw data. The Qwen ecosystem even provides a Code Interpreter tool plugin that the model can invoke to run code safely and return results. Combining Qwen 3 with such tools yields a powerful setup for enterprise data teams to query and analyze data using plain language.
- Knowledge Management and RAG: Qwen 3 is very well-suited to Retrieval-Augmented Generation (RAG) workflows, where the model is provided with relevant external text (retrieved from a database or search engine) to ground its answers. Because Qwen 3 can handle long contexts, you can feed it larger retrieved passages or even entire documents as context. Tools like LlamaIndex or LangChain can be used to integrate Qwen 3 as the LLM in a RAG system – e.g., indexing company documents and then retrieving snippets to answer a specific question. The Qwen team has example integrations for Qwen 2.5 with LlamaIndex (to be updated for Qwen 3) that demonstrate how to do this. In practice, a RAG pipeline with Qwen 3 might involve: embedding documents with a vector store, retrieving top matches for a query, and prompting Qwen 3 with those matches plus the query to get a well-informed answer. Since the model was trained on a lot of text including knowledge-intensive content, it can effectively synthesize information from the provided context and its own prior knowledge. This is valuable for building systems like enterprise search assistants, research assistants, or any application where factual accuracy and citing sources is important (the retrieved text helps keep the model grounded). Qwen 3’s output can be further instructed to quote from the context or follow a certain format, given its strong instruction-following tuning.
In all these use cases, Qwen 3’s open-source nature and flexibility stand out. Developers can deploy it within secure environments, customize it via fine-tuning or prompt engineering, and integrate it with existing tools and databases. Whether you need an AI to automate workflows, assist in coding, converse with users in any language, or crunch through large documents, Qwen 3 provides the core language intelligence to do so. By leveraging its special features (like reasoning modes or tool usage), you can build solutions that were previously challenging to implement with a single unified model.
Running Qwen 3: Python Quickstart Example
To get started with Qwen 3 in your own environment, you can use the Hugging Face Transformers integration or ModelScope. Qwen 3’s weights are hosted on Hugging Face Hub, and support was added in Transformers v4.51.0 and above (older versions will not recognize the qwen3 model type). Below is a quick Python example showing how to load a Qwen 3 model and generate text:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-8B" # Example model variant (8B parameters)
# Load tokenizer and model (will download weights if not cached)
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name, torch_dtype="auto", device_map="auto"
)
# Prepare a chat prompt with the Qwen chat format
prompt = "How does Qwen 3 integrate thinking mode and what is its benefit?"
messages = [
{"role": "user", "content": prompt}
]
# Format the conversation for Qwen 3 (includes special tokens and optional mode flag)
text_input = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True, enable_thinking=True
)
inputs = tokenizer(text_input, return_tensors="pt").to(model.device)
# Generate a response
output_ids = model.generate(**inputs, max_new_tokens=512)[0]
output_tokens = output_ids[len(inputs.input_ids[0]):] # new tokens generated
response_text = tokenizer.decode(output_tokens, skip_special_tokens=True)
print(response_text)
Running the above code will produce a response from the model. We enabled enable_thinking=True in the apply_chat_template call, which means Qwen 3 will likely engage its chain-of-thought for this question. The raw output may include a <think>...</think> section containing the model’s reasoning steps, followed by the final answer. In the code above, we simply decoded the entire assistant response. If you want to separate the reasoning from the answer, you could search the output for the special </think> token (as done in official examples). By default, however, the reasoning content is not printed with special tokens skipped, so response_text will usually just contain the answer.
A few notes on this example:
- We used the 8B parameter dense model for illustration. If you have more GPU memory, you can try larger variants (e.g.,
"Qwen/Qwen3-14B"or the MoE"Qwen/Qwen3-30B-A3B"). Keep in mind the 30B-A3B MoE model will require theparallelformersor ModelScope backend to run efficiently due to its mixture-of-experts layers. - The input was formatted as a conversation with roles (
{"role": "user", "content": ...}), which is the expected format for Qwen’s chat models. Theapply_chat_templateutility inserts necessary system tokens and ensures the prompt is in the right format for Qwen 3’s dialog training. You can also prepend a system message if needed (e.g., a role withsystemto set the assistant’s persona or instructions). - We set
device_map="auto"which will load the model across available GPUs (or CPU if none). For smaller models you can also specifyto(model.device)as above to use one GPU. - The output length is limited by
max_new_tokens. Qwen 3 can generate very long outputs (even beyond 10k tokens) if you allow, but be mindful of your memory and the thinking mode producing a lot of tokens in<think>for complex problems. You can adjust decoding parameters viamodel.generatekwargs or use the default generation config included with the model (which sets sensible defaults like temperature and top-p).
With the above code, you have a basic Qwen 3 inference loop. The model can now be used for interactive prompts, or integrated into a larger application (e.g., wrapped in an API server, or used within a conversation loop as shown in advanced examples).
Using Qwen 3 via REST API (Deployment Example)
In many cases, you might want to deploy Qwen 3 as a service and consume it via a RESTful API. Qwen 3 supports this through frameworks like SGLang and vLLM, which can serve the model with an OpenAI-compatible API endpoint. This means you can use standard Chat Completion API calls (as if talking to OpenAI’s API) but hitting your own Qwen 3 server.
For example, after installing sglang or vllm, you can launch a server for Qwen3-8B as follows (these commands start a local web server on port 8000):
# Using SGLang to host Qwen3 with reasoning support
python -m sglang.launch_server --model-path Qwen/Qwen3-8B --reasoning-parser qwen3
# Alternatively, using vLLM to host an OpenAI-like API (enable reasoning mode)
vllm serve Qwen/Qwen3-8B --enable-reasoning --reasoning-parser deepseek_r1
The above will spin up an API endpoint at http://localhost:8000/v1 by default, which accepts the same schema as OpenAI’s chat API (with the model, messages, etc.). Once the server is running, you can send a chat completion request. For example, using curl:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3-8b",
"messages": [{"role": "user", "content": "Hello, Qwen3. Can you summarize your features?"}],
"max_tokens": 300,
"temperature": 0.7
}'
This will return a JSON response with the assistant’s reply, analogous to OpenAI’s API format (the exact fields may include choices with the message content). You could also use OpenAI’s Python SDK by pointing openai.api_base to your local server.
Deployment Note: The benefit of this approach is that you can easily integrate Qwen 3 into existing applications that expect an OpenAI API. It also allows scaling – for instance, vLLM can utilize continuous batching for high-throughput serving of the model. Ensure you have sufficient hardware for the model variant you host. The 8B model can run on a single GPU (e.g., 16GB memory), whereas the 32B or 30B MoE might require multiple GPUs or 64+ GB of RAM. Quantization can help reduce memory usage (the Qwen documentation provides quantized model performance stats and methods like GPTQ and AWQ for 4-bit running).
By deploying Qwen 3 in this manner, you create a private, customizable chatGPT-like service. Enterprises can host it on cloud instances or on-prem servers to power their applications via API, without sending data to third-party services. This approach also makes it easy to swap in updated model versions or run multiple model instances for different tasks.
Prompt Engineering and Integration Tips
Working with Qwen 3 in development, there are some best practices and tips to get the most out of the model:
- Controlling Reasoning Modes: Use the
enable_thinkingparameter or special commands to control Qwen 3’s reasoning mode. By default, most Qwen 3 chat models have thinking mode enabled, meaning they will produce<think>content internally. If you want strictly fast responses with no chain-of-thought (for instance, in a real-time application), you can disable thinking mode globally by callingtokenizer.apply_chat_template(..., enable_thinking=False). This ensures the model behaves like a standard instruct model (similar to Qwen2.5-Instruct) with minimal reasoning overhead. Alternatively, Qwen 3 offers a soft switch mechanism: when thinking is enabled generally, you can include the token/no_thinkin a user prompt to request that the model not do detailed reasoning for that query. Conversely, you can use/thinkto force a thorough reasoning on a particular query in a multi-turn conversation. This flexibility allows fine-grained prompt control – for example, an agent application might switch the mode off for simple user requests to save time, and switch it on for a complicated analytical question. - Prompt Structure: Qwen 3 was trained with a ChatML-like format (role-based conversation). When using the Transformers API, always format your prompts as a series of messages with roles (
system,user,assistant). Thetokenizer.apply_chat_templatemethod helps with this by converting a list of{"role": ..., "content": ...}into the concatenated text with special tokens. If constructing prompts manually (or using other libraries), ensure you include the proper separators. Typically, Qwen’s format uses tags like<|im_start|>userand<|im_end|>around each message, similar to how OpenAI models delineate roles. Starting a conversation with a system message that sets context (e.g., a persona or instructions) can guide the model’s behavior. Keep the system message concise and relevant, as it counts toward the context length. For multi-turn dialogues, include the recent history messages in each new prompt (Qwen 3 can handle long histories, but you may truncate older turns if hitting the context limit). Maintaining a runninghistoryarray of messages, as illustrated in Qwen’s documentation, is a good pattern for chat interactions. - Generation Settings: Qwen 3’s generation hyperparameters may need tuning depending on the mode. The developers advise against greedy decoding for thinking mode, because it can cause repetitive loops. Instead, use a moderate temperature and nucleus/top-K sampling to keep the reasoning process creative enough to explore solutions. The default config for Qwen 3 sets temperature ~0.6, top-p 0.95 in thinking mode, which is a good balance for quality. In non-thinking mode (quick answers), a slightly higher temperature (0.7) and lower top-p (~0.8) is suggested to maintain some variability without straying off-track. You can experiment with these parameters (and
max_new_tokens) based on your task. If you notice the model repeating itself or not finishing its thought, you might need to adjust the sampling or impose a stop sequence (like a token limit for<think>). Also note that when thinking mode is on, the model generates the<think>content first, then the answer; ensure your application either filters out the<think>text before presenting to end-users, or uses it for logging/analysis as needed. - Tool Use Integration: To use Qwen 3’s agentic abilities, consider incorporating the Qwen-Agent library or following its patterns. Qwen-Agent provides built-in tool calling templates and parsing logic so you don’t have to craft complicated prompts to invoke tools. For example, if you want Qwen 3 to use a calculator or make web requests, Qwen-Agent allows you to define those tools in a config (even pointing to MCP servers for standardized tools) and the model will know how to call them. If you prefer a lighter-weight approach, you can also use the function calling style that other LLMs use: e.g., instruct the model that a certain JSON format corresponds to a function call. Qwen 3 was not explicitly mentioned to have OpenAI-style function-calling out-of-the-box, but its robust few-shot capability means you can prompt it accordingly. For retrieval augmentation, you should provide the retrieved text in the prompt (perhaps prefaced with a system note like “Knowledge: …”) and ask the model to ground its answer in that. Qwen 3, when properly prompted, will use the provided context effectively since it was trained on similar patterns (and the data labeling for knowledge domain might help here). The main tip is: the more explicit and structured your prompt, the better Qwen 3 will handle complex interactions. Take advantage of its multi-turn memory by breaking tasks into steps or turns if needed.
- Fine-tuning and Customization: While Qwen 3’s default model is quite powerful, you may consider fine-tuning it on domain-specific data or instructions for even better performance in a niche domain. Because Qwen 3 is open, you can use libraries like Hugging Face’s
PEFT(for parameter-efficient fine-tuning) or frameworks like Axolotl to fine-tune on your data (the Qwen docs mention some tooling for this). For example, you could fine-tune a Qwen3-8B model on your company’s internal Q&A pairs to specialize it. If fine-tuning the full model is too expensive, methods like LoRA can train small adapter weights. Always adhere to the Apache 2.0 license and any usage policies. Also, keep in mind fine-tuning may degrade some of the balanced behavior if not done carefully – you might lose some multilingual ability or tool-use skill if your fine-tune data is narrow. It might be preferable to use prompt engineering and retrieval to handle domain knowledge before resorting to fine-tuning.
By following these tips, developers can effectively harness Qwen 3’s capabilities while avoiding common pitfalls. The model is complex, but its design (thinking mode, etc.) gives you a lot of control if you choose to use it. When in doubt, refer to the official Qwen documentation and model card for guidance on usage patterns and parameters. The community around Qwen (GitHub, forums) is also growing, so one can find best practices shared by others for prompt techniques or integration patterns.
Deployment Options
One major advantage of Qwen 3 being open-source is the flexibility in deployment. Depending on your requirements and resources, you can deploy Qwen 3 in various environments:
- Local/On-Premises GPU Deployment: Qwen 3 can be run on local machines or on-prem servers equipped with GPUs. For development or smaller-scale use, you might run the 7B or 14B models on a single high-memory GPU (e.g., a 24GB RTX 4090 can handle the 14B model in 16-bit precision). The largest 32B dense model or the 30B MoE may require multiple GPUs or 8-bit quantization to fit on a single device. Tools like Hugging Face Transformers with
device_map="auto"can automatically shard the model layers across available GPUs. Alternatively, you can use optimized runtimes: the Qwen team recommends Ollama, LMStudio, llama.cpp, and KTransformers for local inference, as these have added support for Qwen 3 models. For example, you can useollamaCLI to run Qwen 3 with one command (it handles downloading and running a quantized model), or use llama.cpp for CPU inference of smaller Qwen variants. These local deployments are great for testing and for use cases where data can’t leave your environment (since everything runs locally). Keep in mind that running Qwen 3 at full 128K context or with thinking mode on can be slow on CPUs – for best performance, use GPUs and consider truncating context or disabling thinking for latency-sensitive scenarios. - Cloud Deployment: If you need to serve Qwen 3 at scale, deploying on cloud infrastructure (AWS, Azure, Alibaba Cloud, etc.) with GPU instances is a viable option. You can containerize the model using Docker and perhaps the Transformers REST API or FastAPI to handle requests. Another approach is using vLLM or Text Generation Inference (TGI) from Hugging Face, which are optimized model servers. vLLM, for instance, supports continuous batching and paged attention to serve many requests efficiently from a single model instance. SGLang (an Alibaba open-source project) is another serving framework optimized for serving Qwen and similar models with reasoning support. The Qwen documentation provides examples for deploying with SkyPilot (for multi-node scaling) and dstack/OpenLLM. There’s also DashScope, Alibaba Cloud’s API service, which likely offers hosted Qwen 3 endpoints if you prefer not to manage infrastructure. When deploying in cloud, ensure you allocate enough GPU memory – the 235B MoE model is extremely large (though only 22B active, it still has 235B total weights which might be split across many GPUs). The 30B-A3B model (3B active) is much more tractable, potentially running on 2–4 16GB GPUs or a single 80GB A100 with the proper optimizations.
- Quantization for Efficiency: To make deployment easier, you can use quantized versions of Qwen 3. Quantization reduces the precision of model weights (e.g., 8-bit or 4-bit) to significantly cut memory usage and sometimes even speed up inference. The Qwen team has tested AWQ and GPTQ quantization on Qwen 3 models and provided benchmarks and quantized weight files. For instance, a 4-bit quantized Qwen3-14B can potentially run on a single 12GB GPU, albeit with a small drop in accuracy. If your use case can tolerate a minor quality trade-off, quantization is a practical way to deploy larger Qwen models on limited hardware. Libraries like
transformers(withbitsandbytes) orllama.cppcan load quantized weights. Always measure the accuracy on your tasks after quantization, since certain tasks (especially coding or math) might degrade more than others with lower precision. - Integration with Existing Systems: Thanks to the OpenAI API compatibility via vLLM/SGLang, you can integrate Qwen 3 into systems that were originally built for GPT-4/GPT-3.5. For example, if you have an application using OpenAI’s API, you can switch the endpoint to your deployed Qwen 3 and get similar JSON responses. There are also connectors for platforms like LangChain and LlamaIndex to use Qwen as the LLM backend. This means you can quickly plug Qwen 3 into chain-of-thought reasoning pipelines, retrieval augmentation systems, or agent frameworks provided by those libraries. Using LangChain’s
LLMChainwith Qwen or LlamaIndex’sServiceContextwith Qwen is usually just a matter of specifying the model name and endpoint. The Qwen docs indicate that LangChain integration is supported, which should ease the process of building applications like chatbots with memory or tools (LangChain can call Qwen-Agent tools as well).
In summary, Qwen 3 is flexible to deploy: whether on a single laptop for prototyping or on a distributed cluster for a production service. Always consider the scale of usage (number of concurrent requests, latency requirements) and pick the appropriate model size and optimization (quantization or not). The fact that Qwen 3 provides a range of model sizes and an open license means you have the freedom to experiment and scale without the typical constraints of proprietary models. If you encounter issues, the open-source community (GitHub discussions, Hugging Face forums) is a good resource, as many others will be deploying Qwen 3 and sharing tips.
Limitations and Considerations
While Qwen 3 is a powerful and versatile LLM, developers should be aware of its limitations and use it thoughtfully:
Inference Cost and Latency: Especially in thinking mode, Qwen 3 can be computationally expensive. Generating a chain-of-thought consumes additional tokens and time. For instance, solving a complex math problem might involve the model generating hundreds or thousands of <think> tokens, which takes longer than a direct answer. The thinking budget helps manage this, but it requires careful tuning per use case. If low latency is critical (e.g. user-facing real-time applications), you may need to disable thinking mode or use a smaller model to meet response time targets. The largest models (32B, 235B) also require significant hardware – the 235B MoE model, while optimized, still needs multiple high-memory GPUs and optimized inference engines to run in a reasonable time (the context switching between experts can add overhead). Always test the model’s speed in your environment and consider batch processing for throughput if needed.
Knowledge Cutoff and Accuracy: As of its release in early 2025, Qwen 3’s training data includes a vast range of information, but it will have a knowledge cutoff (likely sometime in 2024 given the data collection timeline). It may not know about events or facts occurring after its training cutoff. Unlike closed models with plug-in live search, Qwen 3 out-of-the-box won’t have updated knowledge unless you explicitly feed it via retrieval. This is a general LLM limitation – Qwen 3 might confidently answer questions about recent events incorrectly because it doesn’t have that information. For mission-critical factual tasks, always use Retrieval-Augmented Generation with up-to-date data rather than relying on the model’s memory.
Hallucination and Reliability: Qwen 3, like other large language models, can sometimes generate hallucinated outputs – that is, plausible-sounding but incorrect information. Its strong training and reasoning reduce this compared to smaller models, but it is not immune. In testing, Qwen 3 might fabricate a source or assume facts if asked something it doesn’t know and not instructed properly. Mitigation strategies include: providing context documents via RAG, asking the model to show its reasoning (so you can inspect if it made a bad assumption), and using the thinking mode which often actually reduces superficial answers. Additionally, the alignment tuning helps it refuse or warn when it’s unsure, but it’s not perfect. Therefore, for applications in domains like healthcare, finance, or legal, you should have human oversight or additional verification of Qwen’s outputs. Implement guardrails and validate critical information from the model before acting on it in an automated fashion.
Bias and Toxicity: The training data for Qwen 3 is vast and likely contains the biases present in internet and literature sources. The Qwen team did perform safety-oriented data filtering and final reinforcement learning to curb harmful outputs, but some bias or inappropriate content may still leak through, especially in languages or topics that were less covered by the safety tuning. Developers should keep this in mind and possibly use a moderation filter on Qwen’s outputs if deploying in production (just as one would with other LLMs). Because Qwen 3 is open, you can also fine-tune or prompt it on extra safety guidelines if needed for your domain.
Memory and Context Handling: Although Qwen 3 has a huge context window, feeding extremely large contexts (e.g., near 100K tokens) can be tricky. The model’s attention mechanism will handle it, but performance may degrade if much of that context is irrelevant. It’s still good practice to provide only relevant information in the prompt – e.g., don’t blindly stuff the maximum context if not necessary. Additionally, using the full 128K context requires certain configurations (like using the YaRN approach mentioned, which may not be default in the transformer code). Ensure your version of the software and model supports the extended context, or you might be effectively limited to 32K. Monitor the model’s output length as well; generating extremely long answers (tens of thousands of tokens) could hit memory or time limits.
MoE Model Complexity: If you choose an MoE variant (30B-A3B or 235B-A22B), note that mixture-of-experts models are more complex to serve. They may not be fully supported by all standard frameworks without some modifications. The Hugging Face Transformers integration (via ModelScope backend) does support Qwen 3 MoE, but performance might be lower if not using specialized inference optimizations. You might need to use DeepSpeed’s Mixture of Experts support or the recommended frameworks (SGLang) which know how to handle MoE routing efficiently. The MoE models also consume more CPU for routing, which can become a bottleneck at scale. So while MoE provides great efficiency in training and potentially inference, be prepared for some engineering effort to deploy them optimally.
In conclusion on limitations: Qwen 3 is a cutting-edge model, but it’s not a magic bullet. Treat it as a powerful component that still needs the usual engineering checks around it. By understanding these considerations – inference cost, knowledge limits, potential for error – you can design your system to mitigate issues (for example, by limiting the domain of queries, using additional verification, or scaling out resources). The Qwen team’s documentation and community feedback are valuable resources if you encounter specific problems. With careful deployment, Qwen 3 can be an incredibly effective tool, delivering top-notch AI capabilities with the transparency and control that come from it being open source.
Developer-Focused FAQs
What model variants of Qwen 3 are available and how do they differ?
How do I switch Qwen 3 between “thinking” mode and “non-thinking” mode?
enable_thinking=True or False. If True (default), the model will engage thinking mode and output a <think>…</think> block internally. If False, the model will behave like a standard instruct model (no chain-of-thought, just direct answer). The second way is by using special tokens in the prompt: when enable_thinking is on, you can insert /think in a user message or system message to request thinking mode for that turn, or /no_think to request it to skip reasoning. The model will obey the latest such directive in a multi-turn chat. Note that if enable_thinking=False globally, the /think or /no_think tags won’t have any effect – the model is locked in fast mode in that case. So for dynamic per-query control, keep thinking enabled and use the tags as needed. Also, if you want the reasoning content, you’ll have to parse out the <think> text from the raw output. The Hugging Face example code demonstrates how to find the special token ID that marks the end of the think block. Many developers simply ignore the think content for end-users, but logging it can be very helpful for debugging and auditing the model’s decision process.Can Qwen 3 be used for Retrieval-Augmented Generation (RAG) and does it support external knowledge?
qwen-agent[rag]) which might streamline some of this process. In summary, Qwen 3 is an excellent choice for RAG because of the amount of knowledge it can take in through prompts. Ensure your retrieval chunks are not too large individually (e.g., splitting documents into passages ~1000 tokens) to allow the model to focus on the most relevant parts. With well-prepared context, Qwen 3 can generate answers that are grounded in the external data, reducing hallucination and improving factual accuracy for domain-specific queries.What are the best ways to deploy Qwen 3 in a production environment?
Is Qwen 3 completely open for commercial use, and how does its license compare to others?
LICENSE file) and ensure compliance (for example, if you redistribute Qwen 3 weights, you need to include the Apache license file). Overall, Alibaba has made Qwen 3 very accessible to the community, which encourages adoption in both research and industry.Conclusion
Qwen 3 represents a significant advancement in open large-language models, bringing together a powerful architecture (with mixture-of-experts and innovative reasoning modes) and practical features tailored for developers. Its state-of-the-art performance on coding, math, and reasoning benchmarks, combined with support for 100+ languages and tool integration, make it a compelling platform for building next-generation AI applications. In this article, we reviewed Qwen 3’s design, capabilities, and usage – from the hybrid thinking vs. non-thinking mode system to hands-on examples of how to deploy and integrate the model. For AI engineers and researchers, Qwen 3 offers the opportunity to experiment with cutting-edge techniques (like dynamic reasoning budgets and agent frameworks) all within an open-source package. Enterprise developers can leverage Qwen 3 to power a range of use cases – intelligent assistants, automated workflows, coding copilots, and more – with the confidence of owning the model and customizing it to their needs.
As with any sophisticated model, maximizing Qwen 3’s potential requires understanding its knobs and levers (we highlighted many of these, such as prompt strategies and deployment considerations). Fortunately, the Qwen community and documentation provide a wealth of information to get started. The release of Qwen 3 under Apache 2.0 also invites the community to contribute and improve it further. We can expect to see continued developments – perhaps distilled smaller versions, or enhanced fine-tuned variants – building on Qwen 3’s foundation.
If you’re building advanced LLM applications and need a powerful, flexible model you can run yourself, Qwen 3 is definitely worth trying. Its blend of efficiency and capability (think deeper, act faster!) has already set a new bar for open models. By following the guidance and examples above, developers should be well-equipped to harness Qwen 3 effectively. Happy hacking with Qwen 3, and welcome to a new era of intelligent, developer-friendly AI models!