
Qwen QwQ is a large language model from Alibaba’s Qwen series, fine-tuned for high-level reasoning and rich conversational abilities. It is a 32-billion-parameter transformer model that “thinks” through problems and dialogs using chain-of-thought reasoning. Unlike a generic chat model, QwQ was post-trained with supervised instruction tuning and scaled Reinforcement Learning (RL) techniques to push its intelligence beyond conventional methods.
The result is a system that excels at complex dialogue tasks, combining logical reasoning with human-like alignment. QwQ can carry on extended multi-turn conversations, maintain a persona or role consistently, and generate responses with nuanced emotional and stylistic tone on demand. Importantly, QwQ is open-source (Apache 2.0 license) and available for both local deployment and via cloud APIs – making it accessible for developers to integrate into their own applications.
High-Level Training & Fine-Tuning Approach
Foundation & Architecture: QwQ-32B is built on the Qwen-2.5 model architecture (32B parameters). It uses a transformer with advanced features like Rotary Position Embeddings (RoPE) for handling long sequences, SwiGLU feed-forwards, and multi-head attention optimizations. The base model was pretrained on a massive multilingual corpus, giving QwQ broad knowledge and multilingual abilities (Qwen models support dozens of languages natively). On top of this foundation, QwQ underwent intensive fine-tuning to specialize in reasoning and dialog.
Reinforcement Learning (RL) at Scale: A key differentiator of QwQ is its multi-stage RL fine-tuning pipeline. In the first stage, the Qwen team applied RL with outcome-based rewards focused on math and coding problems. Instead of using a static reward model alone, QwQ was trained with programmatic verifiers – e.g. a math accuracy checker to reward correct solutions, and a code execution service to reward code that passes test cases. This significantly sharpened its step-by-step problem-solving skills. In a second stage, a more general RLHF (RL from human feedback) was performed using a broad reward model and rule-based rewards. This stage improved the model’s instruction following, alignment with human preferences, and “agent” capabilities without degrading its math/coding prowess. In essence, QwQ learned to reason deeply and stay helpful and on-topic.
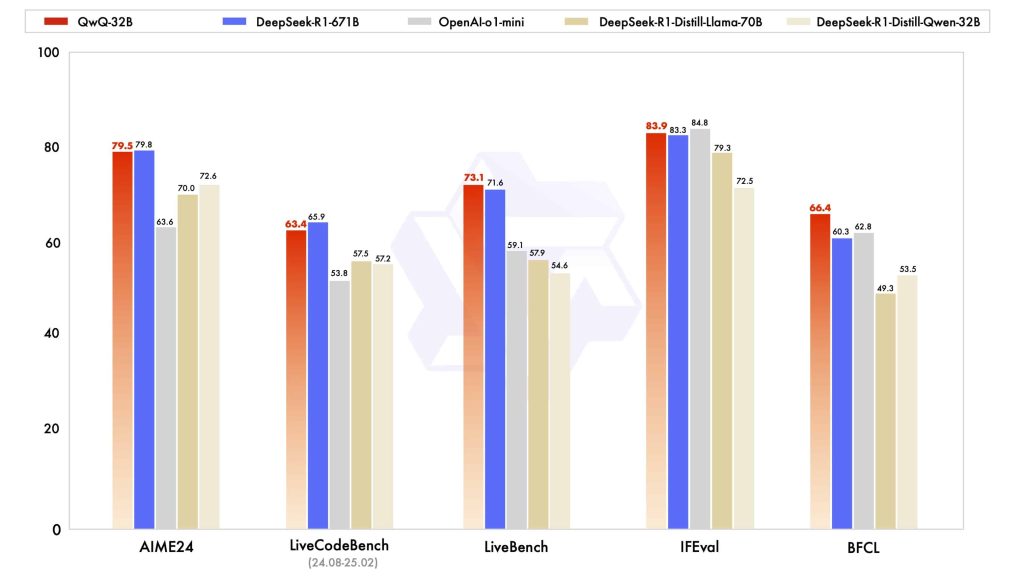
Chain-of-Thought Reasoning: QwQ is explicitly optimized to employ chain-of-thought reasoning internally. It can generate intermediate “thinking” steps (not always shown to the user) and then formulate a final answer. During inference, QwQ even uses inference-time reflection to review and refine its answers. This means the model may internally double-check or critique its draft response before outputting the final reply. The architecture supports an internal <think>…</think> mechanism where the model’s reasoning trace is delineated from the final answer content. This approach yields more reliable and logical responses on hard tasks, as evidenced by QwQ-32B matching the performance of models far larger in size. For example, QwQ’s reasoning abilities rival those of DeepSeek-R1 (a 671B parameter Mixture-of-Experts model) despite being only 32B, underscoring the efficacy of its RL-enhanced training.
Agent Integration: Notably, QwQ also integrates tool-use and agentic behaviors into its training. The model learned to interface with external tools and adapt its reasoning based on feedback from the environment. This was likely achieved by simulating scenarios where the model could issue tool commands or receive observations, and get rewarded for successful outcomes. Thanks to this, QwQ can serve as the reasoning backbone in agent systems – for example, reading from a database or using an API as part of answering a question. The Qwen team reports that QwQ can “think critically while utilizing tools” which opens up possibilities to build advanced agent frameworks on top of it.
Conversational Abilities and Style Control
Although born as a reasoning specialist, QwQ is finely tuned for conversational dialogue. It behaves as a chat model that understands roles (system, user, assistant) and can carry on multi-turn interactions coherently. In training, supervised dialogue data and RLHF alignment ensured QwQ follows conversational instructions and stays helpful, relevant, and safe in responses. A small second-stage RL fine-tune specifically boosted its alignment to human preferences and conversational quality, so it produces high-quality, human-like chat answers. Developers have noted that QwQ excels in long-form dialogue and complex instructions, providing detailed yet aligned answers.
Multi-Turn Memory: QwQ effectively utilizes conversation history to maintain context over long chats. With its extended context window (described below), the model can remember and refer back to earlier parts of a conversation even after dozens of turns. It keeps track of the user’s queries, information given earlier, and the overall discussion topic. This allows for fluent topic progression and avoids repetition. QwQ also exhibits persona consistency – if the conversation establishes the assistant as a certain character or with a certain personality, the model will continue to respond in character consistently across turns. The alignment training (RLHF) helps enforce that the assistant should not contradict itself or forget instructions provided in the system message or earlier dialogue.
Style and Tone Control: A powerful feature for developers is QwQ’s ability to adjust its response style, tone, and voice based on instructions. The model is not limited to a single “assistant” tone; you can prompt it to respond cheerfully, formally, sarcastically, empathetically, or in various literary styles. The recommended way to control style is via the system message or role prompts. For example, a system message might set the stage: “You are an AI assistant with a calm, professional demeanor,” or “You are role-playing as a medieval storyteller, speaking in old Shakespearean English.” QwQ will then modulate its outputs accordingly. The Qwen chat framework allows very detailed persona definitions in the system role – including a character’s name, background, speaking style, and specific behavior rules. This persona description guides QwQ to stay in character. An example from Alibaba’s documentation shows how a system message can define a persona (e.g. a 35-year-old engineer who is professional and concise, refusing personal questions) and Qwen will faithfully enact that persona in its responses. By crafting appropriate system instructions, developers can achieve fine-grained control over QwQ’s tone and persona.
In addition, style can be influenced at the prompt level. You can ask QwQ directly: “Answer the above question in a humorous tone,” or “Rewrite your last answer with more empathy.” Because of QwQ’s alignment training, it generally complies with such instructions and adapts the style while preserving the factual content. This makes QwQ a flexible conversational engine that can fit many applications – from formal customer service bots to playful creative partners – by simply adjusting prompts.
Emotional and Persona-Generation Capabilities
One of QwQ’s core strengths for social AI applications is its ability to generate text with emotional nuance and personality. While many models can output grammatically correct responses, QwQ goes further by aligning with the emotional context of the conversation. It can recognize cues of sentiment or mood in user input and respond appropriately – e.g. with sympathy if the user describes a problem, or with excitement if the user shares good news. More importantly, QwQ can simulate emotions and persona traits in its own voice when asked to do so. Developers can imbue the AI with a fictional personality (e.g. a cheerful friend, a wise mentor, a grumpy wizard) and QwQ will produce responses consistent with that character’s emotional expressions.
This capability is enabled by the rich fine-tuning data and RL alignment for human-like behavior. QwQ has learned to use techniques like exclamation, ellipsis, tone indicators, and descriptive phrasing to convey emotion in text. For example, it might say “I’m really sorry to hear that…” with a compassionate tone, or “That’s fantastic news!” with enthusiasm, depending on context. It can even interject emotional body language or stage directions in text form (if prompted in a roleplay scenario), such as (sighs), (laughs), or (smiles warmly), to make the dialogue more immersive.
Early community fine-tunes of Qwen models demonstrated strong character consistency and emotional depth in long conversations. The underlying model can maintain distinct character personalities across extended dialogues and produce nuanced emotional arcs in storytelling. QwQ inherits these capabilities, allowing it to handle dialogues that require empathy, humor, or dramatic flair. In practice, this means QwQ is well-suited for applications like virtual companions or role-playing chatbots where conveying emotion is key. A QwQ-powered companion bot can listen to a user vent about their day and respond with empathy and encouragement. Likewise, a roleplay NPC powered by QwQ can stay in character (e.g. a nervous innkeeper in a game) and react emotionally to the player’s actions.
It’s important to note that QwQ doesn’t actually “feel” emotions – but it has been tuned to align with human emotional expectations in conversation. The high-quality alignment ensures that its emotional responses are appropriate and not overblown or out-of-place. For instance, it won’t joke about a serious matter if the context suggests a sincere tone is needed. Developers can trust QwQ to handle sensitive or emotional user inputs with a reasonable simulacrum of empathy due to the RLHF training on human-preference data.
Long-Context Dialogue Behavior
Another standout capability of QwQ is its support for extremely long context windows. The model can handle conversations or documents up to 131,072 tokens in length (around 100k words of text) – far exceeding the context length of most chat-oriented LLMs. This is achieved through special fine-tuning (using the YaRN method for RoPE) to extend QwQ’s positional encoding and attention span without sacrificing performance. In practical terms, QwQ can ingest huge transcripts or sustain very lengthy roleplay sessions while remembering details from the beginning.
For example, you could give QwQ a 50-page document as context and then have a conversation about it, and QwQ will be able to pull relevant info even mid-way through the discussion. Or a user could chat with a QwQ-based assistant every day for weeks, and the model could recall past topics or the user’s preferences stated many conversations ago. This long-term context stability makes QwQ ideal for maintaining character backstories and world state in narrative applications. Persona details given at the start (e.g. a character’s entire biography) won’t be forgotten even after thousands of tokens of dialogue.
Technically, QwQ’s architecture uses attention scaling techniques so that it can attend to very long token sequences efficiently. The model applies a rope-based extrapolation and, when needed, an extended context mechanism (YaRN) to generalize beyond its original training length. The Qwen team notes that prompts exceeding 8K tokens may require enabling the YaRN extension, which allows the model to utilize the full 131K window. This means QwQ can be configured for different context lengths depending on the use case – e.g. a default 8K or 32K context for everyday chat, or the full 131K for specialized tasks like processing long texts.
Long-Form Coherence: An important consideration in long contexts is maintaining coherence – many models start to lose track of earlier content or introduce inconsistencies in very long generations. QwQ’s training paid attention to this problem. By training on extended sequences and using chain-of-thought, QwQ learns to preserve context and logical flow across long outputs. It avoids drifting off-topic or contradicting earlier facts in the conversation. Internal tests and community reports indicate that QwQ is able to carry themes and persona traits through extensive dialogues without needing frequent user reminders.
Of course, using extremely long contexts may have performance trade-offs (memory and speed), which we discuss later. But from a capability standpoint, QwQ enables use cases that were previously impractical – like conversationally summarizing a long book chapter by chapter, or running an interactive fiction game with full memory of all player actions.
Technical Integration (Python and REST API)
Being an open model, QwQ is straightforward to integrate into various systems. Developers have two primary options to use QwQ: running the model locally (or on a dedicated server) via machine learning frameworks, or calling an API service that hosts QwQ (Alibaba Cloud offers one). Below we provide code examples for both approaches.
Python Integration with Hugging Face Transformers
QwQ-32B is available on Hugging Face Hub, which makes local usage with Python quite convenient. The model weights (in fp16 or bf16 precision) can be downloaded and loaded with the Hugging Face Transformers library. Ensure you have an updated transformers version (>=4.37) since QwQ relies on Qwen-2.5 architectures that were added recently. Here’s a minimal example of loading QwQ and generating a chat completion:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "Qwen/QwQ-32B"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
# Prepare a conversation with system/user messages
messages = [
{"role": "system", "content": "You are a helpful, friendly AI assistant."},
{"role": "user", "content": "Hello QwQ, can you tell me a joke to cheer me up?"}
]
# Convert messages to model input format using Qwen's chat template
text_input = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(text_input, return_tensors="pt").to(model.device)
# Generate a response (allow up to 256 new tokens for the answer)
outputs = model.generate(**inputs, max_new_tokens=256, temperature=0.7, top_p=0.9)
response_ids = outputs[0][inputs["input_ids"].shape[1]:] # slice out only new tokens
answer = tokenizer.decode(response_ids, skip_special_tokens=True)
print(answer)
In this example, we provide a system message to set the assistant’s persona/tone (helpful and friendly) and a user prompt asking for a joke. We use tokenizer.apply_chat_template to format the messages into Qwen’s internal prompt format – this ensures the special tokens and <think> tag are handled correctly. The model then generates a continuation, and we decode the assistant’s answer. We also set sampling parameters (temperature=0.7, top_p=0.9) for a more varied, non-greedy response; Qwen developers recommend using sampling rather than pure greedy decoding to avoid repetitive loops. The output might look like:
“Assistant: Of course! Why did the computer go to therapy? Because it had too many bytes! (I hope that made you smile a bit.)”
This shows QwQ producing a lighthearted joke in a friendly tone, as instructed.
You can accumulate the messages list with each turn (appending the assistant’s answer as a new message) to have a persistent conversation. Just remember not to include QwQ’s <think> reasoning content in the history – only the final answer should be added for each turn. The apply_chat_template utility already strips out the reasoning content when formatting the history.
Under the hood, QwQ uses standard causal LM generation. Given the model’s size (32B) and context length, it’s advisable to use a GPU with sufficient memory (at least ~48 GB for full precision, or use 8-bit/4-bit quantization to fit on smaller GPUs). The device_map="auto" argument will automatically shard the model across available GPUs if you have multiple. QwQ is also compatible with optimized inference backends like HuggingFace’s Text Generation Inference (TGI) and vLLM for production deployment.
Using QwQ via REST API (OpenAI-Compatible)
For those who prefer a hosted solution, Alibaba Cloud provides a service endpoint for QwQ-32B (and other Qwen models) via their Model Studio / DashScope API. This API is OpenAI API compatible, meaning you can use the same request format as you would with OpenAI’s GPT endpoints. This makes integration very convenient if you already have code using OpenAI’s SDK.
For example, using the official OpenAI Python library, you can call QwQ-32B by pointing the API base URL to Alibaba’s endpoint and specifying the model name:
import openai
openai.api_key = "YOUR_API_KEY" # obtain from Alibaba Cloud Model Studio
openai.api_base = "https://dashscope.aliyuncs.com/compatible-mode/v1"
response = openai.ChatCompletion.create(
model="qwq-32b",
messages=[
{"role": "user", "content": "Which is larger, 9.9 or 9.11?"}
],
temperature=0.0 # zero temperature for a deterministic reasoning question
)
answer_text = response['choices'][0]['message']['content']
print(answer_text)
This will POST a chat completion request to the DashScope endpoint and return QwQ’s answer. In this case, QwQ should respond with an explanation comparing 9.9 and 9.11 (treating them as numbers, 9.11 is larger).
One interesting feature of QwQ’s API is that it can return the model’s reasoning trace separately from the final answer when streaming. If you use stream=True in the API call, the JSON chunks may include a field reasoning_content in addition to the usual content. The reasoning_content is essentially QwQ’s chain-of-thought (the text it generated in the <think> section). By capturing these, developers can inspect or even visualize how QwQ arrived at an answer step by step. In non-streaming mode, the reasoning content is typically not included in the final message (only the answer is given) – the system filters it out to behave like a normal chatbot. But streaming mode provides a hook into the thought process. For advanced use cases, you could leverage this to have an agent loop: let QwQ reason, parse the reasoning for tool invocations or actions, execute them, and then feed the results back before the final answer.
Beyond direct REST calls, the Qwen ecosystem also supports integration with libraries like LangChain, LlamaIndex, and Qwen-Agent for building complex applications. For instance, Qwen-Agent is an open-source agent framework specifically designed to work with Qwen models (allowing function calling and tool usage in a structured way). Developers can plug QwQ in as the language backbone of these systems to create multi-step reasoning pipelines, retrieval-augmented QA systems, and more, with relatively low effort.
Prompt Engineering (Tone, Emotion, Personality)
Working with QwQ for best results may involve some prompt engineering to guide its outputs. Here are several tips and techniques:
- System Message for Persona/Tone: As mentioned, leverage the system role to establish the desired persona and style of the assistant from the start. A well-crafted system prompt can include the assistant’s identity, traits, and boundaries. For example: “You are Luna, a witty and compassionate AI tutor who uses a casual tone. You always encourage the user and include light humor in your answers.” This primes QwQ to respond in a manner consistent with that character without needing repetition in each user query.
- In-Conversation Instructions: You can adjust the tone on the fly by instructing QwQ within a user message. E.g. “Explain the solution, and do it in an excited tone as if teaching a fun fact to a friend.” QwQ will pick up these cues and modulate the response. It’s generally very good at following explicit style directives thanks to its fine-tuning on diverse instructions.
- Emotion Triggers: If you want QwQ to display a certain emotion, you can either describe a scenario that evokes it, or directly tell the assistant to behave with that emotion. For instance, “The user is sad. Respond as an empathetic counselor.” or “Stay calm and reassuring even if the user is angry.” Because QwQ was trained on human dialogues, it recognizes emotional context and will adapt its wording (e.g. using soothing language for empathy).
- Structured Output Prompts: QwQ is capable of producing structured outputs (JSON, lists, markdown, etc.) if you explicitly ask. To integrate with downstream systems, you might prompt the model to format its answer in a machine-readable way. For example, for a multiple-choice question, you can prompt: “Please output your final answer in a JSON object with an
answerfield containing only the choice letter.” This technique was suggested in QwQ’s usage guidelines to standardize outputs. Similarly, for math problems you might say: “Show your reasoning step by step, then put the final numeric answer in a box like this: \boxed{42}.”. By including these format instructions, QwQ will follow suit and make it easy to parse its answer or display it nicely in an application. - Long Prompt Considerations: When giving very long context (e.g. pasting articles or chat history beyond a few thousand tokens), it can help to remind the model of important points or use a summary in the system message to focus its attention. While QwQ can handle up to 100k+ tokens, you still want to ensure critical instructions are not lost in the noise. The model’s focus tends to be stronger at the beginning and end of the prompt, so placing key instructions in the system message (start) or appending a concise directive at the end of user message can be effective.
- Avoiding Prompt Leaks: Because QwQ uses an internal template with special tokens (like
<|im_start|>systemetc.), you generally should rely on the provided chat formatting functions (apply_chat_template) or follow the format exactly as documented. Inserting raw tokens incorrectly might break the prompt parsing. When using the raw API, just send the messages as usual and the service will handle the formatting.
In summary, QwQ responds very well to clear, specific instructions. It was trained to follow user intent closely, so the more guidance you give in the prompt about style or format, the more likely the output will meet your needs. Unlike some models that have a fixed tone, QwQ is quite pliable – a valuable trait for developers building custom conversational agents.
Example Workflows and Use Cases
QwQ’s blend of conversational skill, emotional depth, and reasoning makes it suitable for a wide range of applications. Here we highlight a few use cases and how QwQ contributes in each:
Chatbots with Emotional Intelligence (Virtual Companions)
QwQ is a great choice for building chatbots that users can form a connection with – for example, a mental health support bot, or just a friendly virtual companion. Such bots need to understand user emotions and respond appropriately. QwQ’s alignment and emotional tuning allow it to pick up cues like sadness, frustration, or excitement in user messages and adjust its reply. It can express empathy (“I’m sorry you’re going through that. It sounds really tough.”) or excitement (“Wow, that’s wonderful news! I’m really happy for you!”) at a level that feels natural. The persona persistence of QwQ ensures the bot can develop a consistent personality over long-term interactions, which is key for user trust.
Consider a virtual friend app: The developer can program a base persona (cheerful, supportive) via the system prompt and let QwQ handle the rest. If the user comes home after a bad day and vents, QwQ will recognize the negative sentiment and maintain a sympathetic tone, perhaps even offering encouragement or gentle advice. Its responses are backed by reasoning as well – it might recall prior conversations (e.g. “I remember last week you mentioned a stressful project at work. Is it the same one bothering you today?”) thanks to the long memory. This mix of factual recall and emotional context is exactly what makes an AI companion feel engaging. Developers can further utilize QwQ’s tool-use capability to integrate real-world data: for instance, if the user is sad about missing an event, the bot could use a calendar API (via an agent chain) to find upcoming events and cheer the user up with future plans.
Creative Writing Assistants and Story Generation
Another strong use case is using QwQ as a creative writing partner or narrative generator. The model’s ability to maintain context over thousands of tokens means it can generate coherent long-form content like stories, script dialogues, or even game narrative. A writer can collaborate with QwQ by providing a prompt or an outline, and QwQ will flesh it out with rich detail. Because it was fine-tuned on high-quality text and it employs chain-of-thought, the storytelling is both imaginative and logically consistent. It can keep track of plot points introduced early on and bring them to resolution later, avoiding common pitfalls like forgetting a character’s name or suddenly changing a story’s tone.
Emotional range is crucial in storytelling, and QwQ is adept at writing characters with distinct voices and feelings. If you prompt QwQ with “Tell a short story about a robot discovering a new emotion, in a bittersweet tone,” it might produce a narrative that captures the mix of wonder and melancholy, with the robot character’s dialogue and inner thoughts reflecting confusion and hope. The developer could also instruct QwQ to output the story in a structured format (e.g. with chapter headings, or as a screenplay with character labels) to suit their application.
Furthermore, QwQ can generate dialogue that feels conversational – useful for scriptwriting or game writing. Its role-play training means it can simulate multiple characters talking. A developer could have QwQ generate a scene by giving it a prompt like “[Two characters arguing about a secret]” and it will produce a multi-turn dialogue with emotional dynamics. In fact, Alibaba has specialized variants aimed at role-play and character simulation, demonstrating the demand for this capability. QwQ itself, with proper prompting, can fulfill many of these needs for creative and immersive content generation.
Social Media AI Characters and NPCs
In social platforms or games, AI-driven characters are increasingly popular – think of AI influencers, chat-based game characters, or interactive story bots on Twitter/Reddit. QwQ’s persona agility makes it ideal to power these. A developer can define a detailed persona profile for the character (age, background, speaking style, catchphrases, etc.) and QwQ will embody that character in its interactions. The long context window allows the character to maintain continuity with frequent users or through complex plot lines.
For example, a company might create an AI mascot that users can chat with on a forum. Using QwQ, they ensure the mascot speaks in a consistent voice, remembers loyal users (by storing conversation history), and can handle a variety of user inputs – from casual banter to technical questions – with appropriate tone. Because QwQ is a large model with broad knowledge, the character can be both entertaining and informative. It might respond with memes and jokes to fit internet culture, or switch to a serious tone if a user asks a support question, all within the bounds of the defined personality.
In gaming, QwQ can control NPC dialogue dynamically. Instead of pre-scripted lines, NPCs could be driven by QwQ prompts that include the game state and the NPC’s persona. This would yield more varied and lifelike interactions. QwQ’s emotional coherence ensures that an NPC who is meant to be gruff and unsentimental will consistently respond in that manner, even if the player tries to elicit emotional reactions – the AI won’t break character easily. Alibaba’s own “Qwen-Character” role-play model is an example catered to this domain, highlighting enhanced character portrayal and empathetic listening. With QwQ, many of those benefits are accessible out-of-the-box for custom characters in virtual worlds or social apps.
Agentic Dialogue Systems and Multi-Step Reasoning
QwQ truly shines in applications that require multi-step problem solving via dialogue, such as assistant agents that plan tasks or retrieve information over several turns. Thanks to its chain-of-thought reasoning and tool-use integration, QwQ can function as the brain of an agentic system that interacts with external processes. A classic example is a “ChatGPT-style” AI agent that can use tools: the agent (QwQ) receives a high-level query, breaks it down into steps, possibly queries a database or calls an API for intermediate answers, and then composes a final solution.
With QwQ, one can implement the ReAct pattern (Reason+Act) where the model’s reasoning content is parsed for actions. For instance, you ask: “Find me a restaurant in Paris with good vegan options and make a reservation for Friday at 7 pm.” QwQ might internally generate a thought like: “<think>\nI should search for vegan-friendly restaurants in Paris…\n</think>” followed by a suggestion. By capturing the <think> text, the system can see that QwQ wants to perform a search. It then uses an API to get restaurant data, feeds that back to QwQ (possibly as an observation in the conversation), and QwQ continues reasoning (maybe deciding on one and formulating a reservation request). The final answer to the user is a nicely formatted confirmation with details. This kind of dialogue-based planning is where QwQ’s design (especially the reflection and agentic RL training) provides a huge advantage in building reliable solutions.
Moreover, QwQ’s tool adaptation means it was trained to expect and incorporate tool outputs during reasoning. It can, for example, take a JSON result from a web API provided in the conversation and integrate that data into its answer after the <think> stage. The long context window is again beneficial here because intermediate data or lengthy tool outputs can be fed into QwQ without overflowing the model’s memory.
Overall, QwQ serves as a robust dialogue manager for multi-step workflows: it keeps track of what has been done, what needs to be done next, and when to present the final result. This is useful not only for explicit “assistant agent” use cases but also for any complex conversational logic (tech support bots that troubleshoot through steps, tutoring systems guiding a student through a problem, etc.). QwQ’s careful balance of reasoning power and conversational alignment makes such complex interactions feasible in a natural conversational format.
Performance Considerations
When deploying QwQ-32B in real-world systems, developers should be mindful of its performance characteristics given the model’s size and capabilities:
- Resource Requirements: With 32.5B parameters, QwQ-32B is a heavy model. Running it in full precision typically requires multiple high-memory GPUs or one A100 80GB GPU. However, there are practical ways to reduce memory: QwQ is compatible with 8-bit and 4-bit quantization. Quantizing to 4-bit (e.g. using GPTQ or AWQ) can shrink memory usage so that 32B fits in roughly 16–24 GB, making it possible to run on a single modern GPU or even high-end consumer hardware. In fact, quantized Qwen models have been run on Mac M2 machines and other local devices by early adopters. The trade-off is some loss of model quality, but QwQ seems to retain good performance even at 4-bit, based on community feedback. If using the long 131k context, note that attention memory scales with sequence length – so serving max context may require splitting across more GPUs or using optimized inference engines that can handle long contexts efficiently.
- Latency and Throughput: QwQ’s inference speed will be lower than smaller models, simply due to the parameter count and the longer context handling. In high-throughput settings, you might consider using the INT8 mode or enabling model parallelism across GPUs to speed up generation. Alibaba’s benchmarks indicate QwQ can produce on the order of a few tens of tokens per second on a single high-end GPU, and faster if scaled out (exact numbers vary by hardware and sequence length). Using a serving framework like vLLM or TGI can help with dynamic batching of requests to improve throughput. Also, if you don’t need the full 131k context for a given application, using a shorter context setting (like 8k or 32k) can reduce computational overhead.
- Long-Context Overhead: When utilizing very long contexts, be aware of diminishing returns – processing tens of thousands of tokens every request is costly. It’s often wise to truncate or summarize context that may no longer be relevant. QwQ’s ability to handle it is there if needed, but you’ll pay in latency for extreme cases. Techniques like windowed attention or retrieval augmented generation (splitting context into chunks and querying) could be combined with QwQ to manage this. The YaRN method used by QwQ is quite efficient (only ~0.1% of pretraining data was needed to extend context in fine-tuning), but inference cost is still linear in sequence length.
- Generation Quality and Parameters: QwQ was tuned to output thoughtful, sometimes lengthy responses (because of its reasoning nature). If you need shorter or more terse answers, you may want to adjust decoding settings (e.g. limit
max_new_tokensor increase the penalty for length). By default, QwQ is inclined to be comprehensive. Also, as noted in usage guidelines, using a bit of randomness in decoding (temperature around 0.6–0.7, top-p ~0.95) helps avoid repetitive outputs. Greedy decoding is not recommended except for tasks like math where determinism is desired. The model can occasionally “ramble” if temperature is too high combined with its long-winded reasoning, so find a balance for your use case. - Precision of Reasoning: Although QwQ is among the best in open-source reasoning, it’s not infallible. Sometimes the chain-of-thought can be incorrect or the model might make arithmetic mistakes if the verifier signals weren’t perfect. Always consider adding your own validation if using QwQ for critical calculations (e.g. have it output an answer and then double-check within your code if possible). The good news is QwQ tends to be transparent when unsure – often its reasoning (if you capture it) will show uncertainty, which you can detect and handle (for example, asking the model to try again or break down the problem differently).
In summary, deploying QwQ requires more compute than smaller models, but it brings significant gains in capability. With careful engineering (quantization, scaling, and prompt management), it can be run in production settings effectively. The model’s open license also means you have freedom to optimize and modify it to fit your system.
Limitations & Safety Alignment
No AI model is perfect, and QwQ has certain limitations and safety considerations to keep in mind:
- Compliance and Censorship: Being developed by Alibaba, QwQ-32B was aligned with the safety and regulatory requirements relevant to its context. The model is designed to refuse or avoid generating disallowed content (hate speech, explicit sexual content, extreme violence, etc.) and to follow rules set in its system prompt. In fact, adherence to regional regulations was noted as a factor – for instance, responses on politically sensitive topics may be restricted. Developers using QwQ might observe the model refusing requests that violate its built-in safety guardrails (e.g. asking for instructions to do something illegal or harmful). This is generally a positive for safety, but if your application needs a more permissive model, you would have to fine-tune QwQ or choose a different base. Always test QwQ on the specific content scenarios of your application to ensure its alignment suits your needs.
- Hallucination and Accuracy: Like all large language models, QwQ can produce hallucinations – plausible-sounding statements that are false. Its strong reasoning training reduces this in tasks like math or code (where it can verify outcomes), but for open-domain knowledge queries it might still get things wrong confidently. The broad pretraining helps, but information might be outdated or incomplete. It’s recommended to validate critical facts via retrieval or to keep QwQ’s knowledge updated by fine-tuning if possible. The chain-of-thought output can sometimes help diagnose why it answered a certain way, which is an advantage for troubleshooting correctness issues.
- Bias and Fairness: The training data likely contained biases, and even with alignment, some may persist in QwQ’s outputs. The model might, for example, produce subtly gender-biased assumptions or culturally specific viewpoints. Alibaba has not open-sourced the exact RLHF datasets, so it’s hard to quantify residual biases. Developers should monitor and, if needed, mitigate bias (perhaps via additional prompt guidelines or fine-tuned corrections on sensitive topics). That said, the RLHF process would have tried to instill neutral and helpful behavior across user demographics.
- Over-Alignment: QwQ is aligned to be helpful and not offensive, which usually is desirable, but in some cases it might be overly cautious. It may refuse harmless requests if they resemble something disallowed. It may also default to certain polite or apologetic styles even when not needed, due to alignment training. For example, it might overuse phrases like “I’m sorry, but I cannot do that” if it perceives a slight violation. Careful prompt design (explicitly telling the model it’s allowed to be more creative or that the content is safe) can sometimes get around these issues. Being open-source, one could also fine-tune to adjust the level of strictness if necessary.
- User Data Handling: If you deploy QwQ in an application, remember that any user-provided content that goes into the model (especially if using a cloud API) should be handled per privacy norms. The model itself doesn’t store the conversations permanently, but logs may exist on the service side if using an API. For local deployments, ensure you have enough logging and monitoring, because debugging a 100k-token context can be challenging without tools. There’s no built-in user data anonymization in QwQ beyond what the training data did, so treat it like any other AI model in terms of not feeding it sensitive data you wouldn’t want processed in the cloud (unless you self-host it).
In essence, QwQ is a safe and well-aligned model for general use, but developers should still enforce their own safety layer on top for production (e.g. content filtering before/after the model, user consent for data usage, etc.). The model’s refusals and safe completions are a feature, not a bug – leveraging them properly will help maintain a good user experience and compliance.
Developer-Focused FAQs
How does QwQ differ from other Qwen models (like Qwen-Chat or Qwen3)?
What is the maximum context length and how do I enable it?
transformers library is up to date (which includes Qwen’s dynamic NTK scaling). Keep in mind memory usage and inference time grow with context length, so test carefully. If using the Alibaba Cloud API, the context limit might be set lower (e.g. 32K) for that service, so check their docs for the specific model endpoint.Can QwQ handle languages other than English?
Does QwQ support function calling or tool use out-of-the-box?
What are some best practices for fine-tuning or customizing QwQ?
How do I ensure QwQ’s “thinking” doesn’t appear in the final output?
<think> or the chain-of-thought text. To avoid exposing this to end-users, always post-process the model output to remove the reasoning segment. In the Hugging Face pipeline, apply_chat_template with add_generation_prompt=True already handles it – the model’s final answer will come after a special token that the template knows to cut off. If you manually prompt without that, you might get an answer like: “<think>\nreasoning steps here\n<\think>\nSure, 9.11 is larger than 9.9 because …”. The safe approach is to either use the official template or programmatically strip out anything between the <think> tags (and the tags themselves). Also, do not feed the <think> content back into the model on the next turn’s history. Only include what the model said as the assistant (post-thinking). Following these practices will keep the chain-of-thought hidden, creating an illusion that the AI just “magically” outputs well-reasoned answers.